 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multiple Instance Learning for Taxonomic Classification of Metagenomic read sets
Sep 28, 2019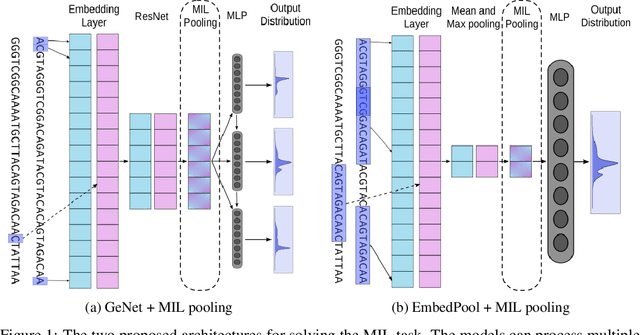
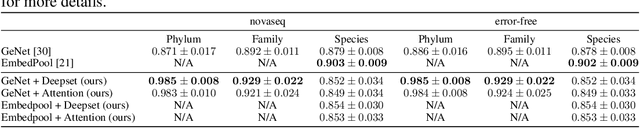
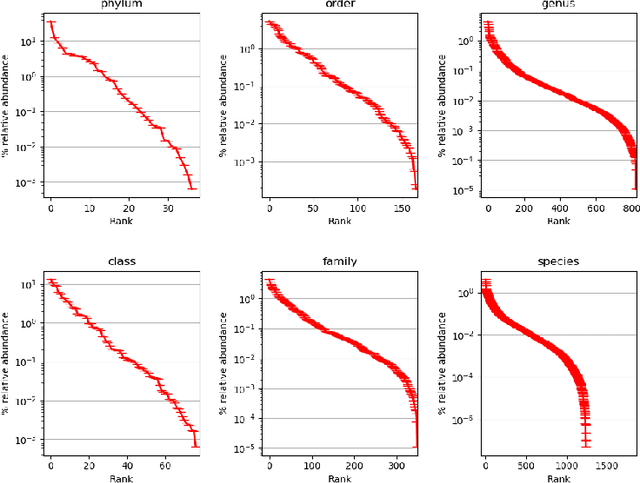
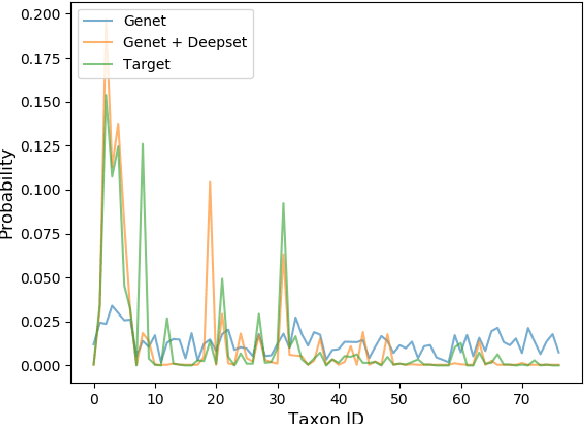
Metagenomic studies have increasingly utilized sequencing technologies in order to analyze DNA fragments found in environmental samples. It can provide useful insights for studying the interactions between hosts and microbes, infectious disease proliferation, and novel species discovery. One important step in this analysis is the taxonomic classification of those DNA fragments. Of particular interest is the determination of the distribution of the taxa of microbes in metagenomic samples. Recent attempts using deep learning focus on architectures that classify single DNA reads independently from each other. In this work, we attempt to solve the task of directly predicting the distribution over the taxa of whole metagenomic read sets. We formulate this task as a Multiple Instance Learning (MIL) problem. We extend architectures used in single-read taxonomic classification with two different types of permutation-invariant MIL pooling layers: a) deepsets and b) attention-based pooling. We illustrate that our architecture can exploit the co-occurrence of species in metagenomic read sets and outperforms the single-read architectures in predicting the distribution over the taxa at higher taxonomic ranks.