 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient CNN-LSTM based Image Captioning using Neural Network Compression
Dec 17, 2020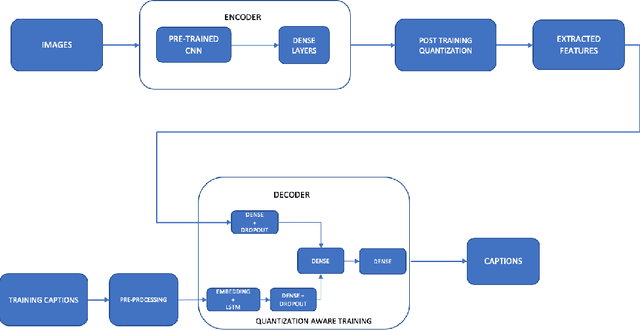
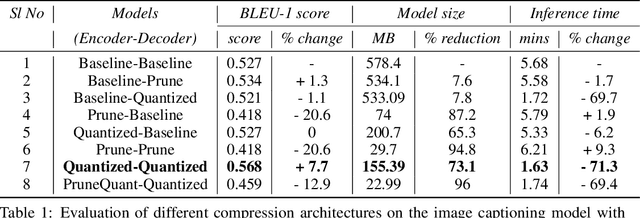
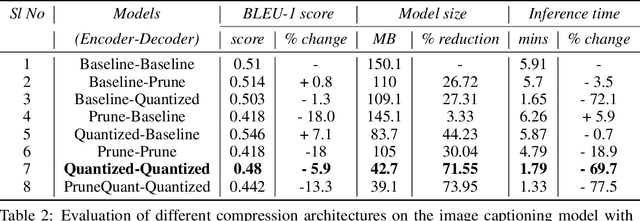

Modern Neural Networks are eminent in achieving state of the art performance on tasks under Computer Vision, Natural Language Processing and related verticals. However, they are notorious for their voracious memory and compute appetite which further obstructs their deployment on resource limited edge devices. In order to achieve edge deployment, researchers have developed pruning and quantization algorithms to compress such networks without compromising their efficacy. Such compression algorithms are broadly experimented on standalone CNN and RNN architectures while in this work, we present an unconventional end to end compression pipeline of a CNN-LSTM based Image Captioning model. The model is trained using VGG16 or ResNet50 as an encoder and an LSTM decoder on the flickr8k dataset. We then examine the effects of different compression architectures on the model and design a compression architecture that achieves a 73.1% reduction in model size, 71.3% reduction in inference time and a 7.7% increase in BLEU score as compared to its uncompressed counterpart.
Placement in Integrated Circuits using Cyclic Reinforcement Learning and Simulated Annealing
Nov 15, 2020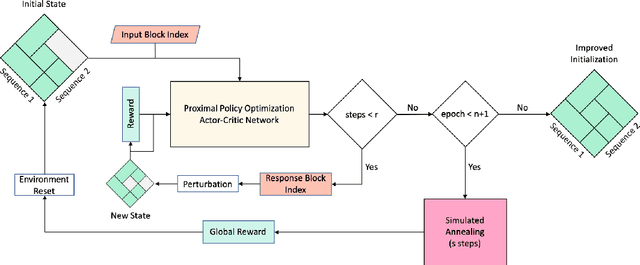
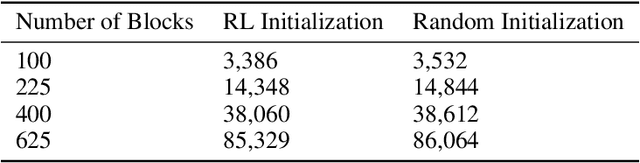
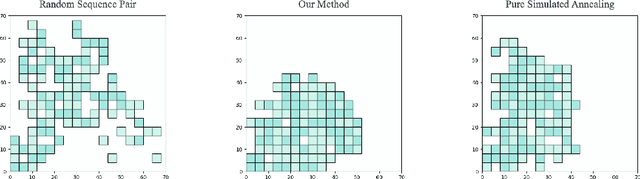

Physical design and production of Integrated Circuits (IC) is becoming increasingly more challenging as the sophistication in IC technology is steadily increasing. Placement has been one of the most critical steps in IC physical design. Through decades of research, partition-based, analytical-based and annealing-based placers have been enriching the placement solution toolbox. However, open challenges including long run time and lack of ability to generalize continue to restrict wider applications of existing placement tools. We devise a learning-based placement tool based on cyclic application of Reinforcement Learning (RL) and Simulated Annealing (SA) by leveraging the advancement of RL. Results show that the RL module is able to provide a better initialization for SA and thus leads to a better final placement design. Compared to other recent learning-based placers, our method is majorly different with its combination of RL and SA. It leverages the RL model's ability to quickly get a good rough solution after training and the heuristic's ability to realize greedy improvements in the solution.