 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient CNN-LSTM based Image Captioning using Neural Network Compression
Paper and Code
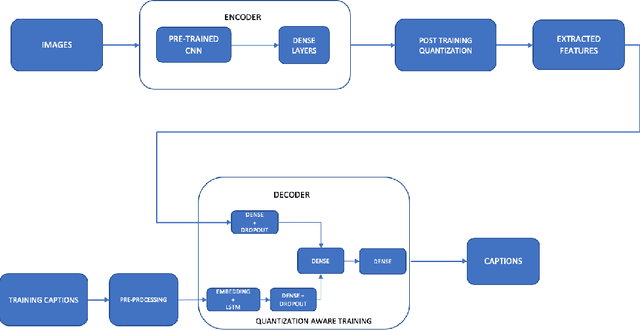
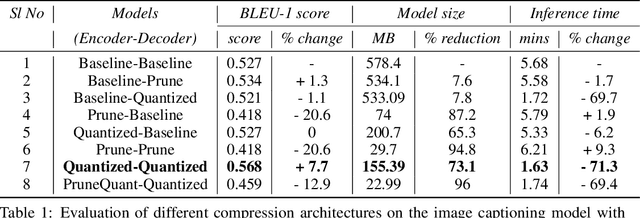
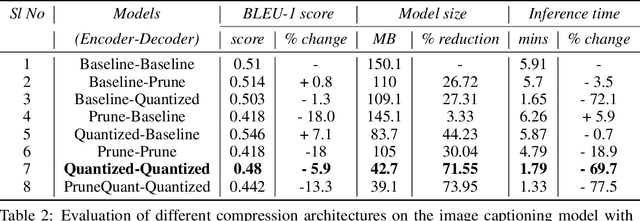

Modern Neural Networks are eminent in achieving state of the art performance on tasks under Computer Vision, Natural Language Processing and related verticals. However, they are notorious for their voracious memory and compute appetite which further obstructs their deployment on resource limited edge devices. In order to achieve edge deployment, researchers have developed pruning and quantization algorithms to compress such networks without compromising their efficacy. Such compression algorithms are broadly experimented on standalone CNN and RNN architectures while in this work, we present an unconventional end to end compression pipeline of a CNN-LSTM based Image Captioning model. The model is trained using VGG16 or ResNet50 as an encoder and an LSTM decoder on the flickr8k dataset. We then examine the effects of different compression architectures on the model and design a compression architecture that achieves a 73.1% reduction in model size, 71.3% reduction in inference time and a 7.7% increase in BLEU score as compared to its uncompressed counterpart.