 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Methods for Sufficient, Socially-Aligned Feature Importance Explanations with In-Distribution Counterfactuals
Jun 01, 2021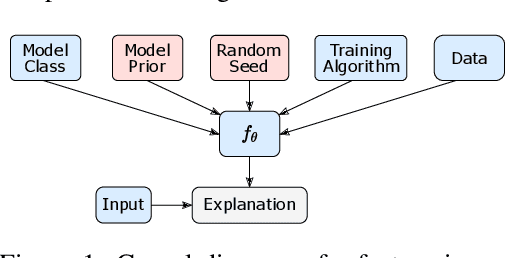


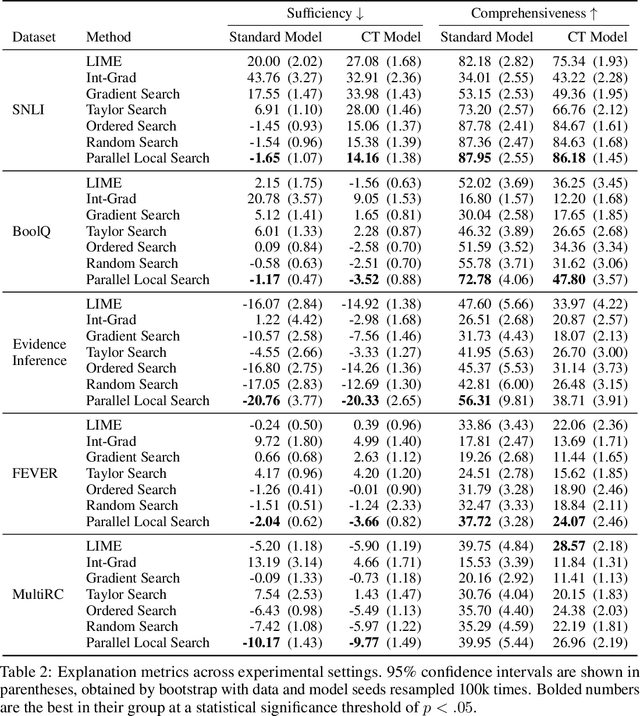
Feature importance (FI) estimates are a popular form of explanation, and they are commonly created and evaluated by computing the change in model confidence caused by removing certain input features at test time. For example, in the standard Sufficiency metric, only the top-k most important tokens are kept. In this paper, we study several under-explored dimensions of FI-based explanations, providing conceptual and empirical improvements for this form of explanation. First, we advance a new argument for why it can be problematic to remove features from an input when creating or evaluating explanations: the fact that these counterfactual inputs are out-of-distribution (OOD) to models implies that the resulting explanations are socially misaligned. The crux of the problem is that the model prior and random weight initialization influence the explanations (and explanation metrics) in unintended ways. To resolve this issue, we propose a simple alteration to the model training process, which results in more socially aligned explanations and metrics. Second, we compare among five approaches for removing features from model inputs. We find that some methods produce more OOD counterfactuals than others, and we make recommendations for selecting a feature-replacement function. Finally, we introduce four search-based methods for identifying FI explanations and compare them to strong baselines, including LIME, Integrated Gradients, and random search. On experiments with six diverse text classification datasets, we find that the only method that consistently outperforms random search is a Parallel Local Search that we introduce. Improvements over the second-best method are as large as 5.4 points for Sufficiency and 17 points for Comprehensiveness. All supporting code is publicly available at https://github.com/peterbhase/ExplanationSearch.
Leakage-Adjusted Simulatability: Can Models Generate Non-Trivial Explanations of Their Behavior in Natural Language?
Oct 08, 2020Data collection for natural language (NL) understanding tasks has increasingly included human explanations alongside data points, allowing past works to introduce models that both perform a task and generate NL explanations for their outputs. Yet to date, model-generated explanations have been evaluated on the basis of surface-level similarities to human explanations, both through automatic metrics like BLEU and human evaluations. We argue that these evaluations are insufficient, since they fail to indicate whether explanations support actual model behavior (faithfulness), rather than simply match what a human would say (plausibility). In this work, we address the problem of evaluating explanations from the model simulatability perspective. Our contributions are as follows: (1) We introduce a leakage-adjusted simulatability (LAS) metric for evaluating NL explanations, which measures how well explanations help an observer predict a model's output, while controlling for how explanations can directly leak the output. We use a model as a proxy for a human observer, and validate this choice with two human subject experiments. (2) Using the CoS-E and e-SNLI datasets, we evaluate two existing generative graphical models and two new approaches; one rationalizing method we introduce achieves roughly human-level LAS scores. (3) Lastly, we frame explanation generation as a multi-agent game and optimize explanations for simulatability while penalizing label leakage, which can improve LAS scores. We provide code for the experiments in this paper at https://github.com/peterbhase/LAS-NL-Explanations
Bayesian optimal control of GHZ states in Rydberg lattices
May 12, 2020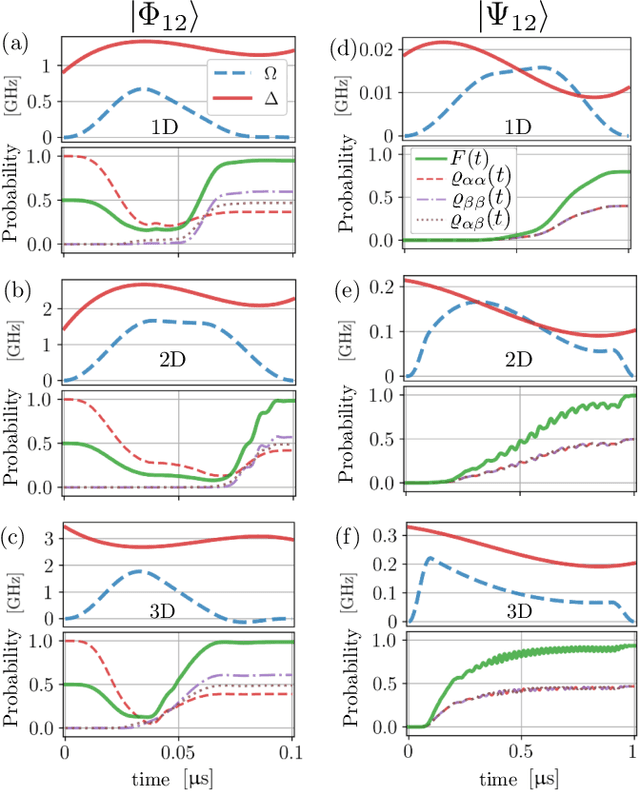
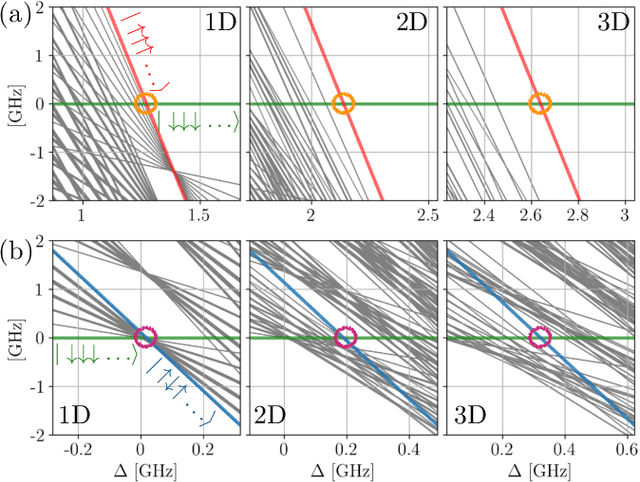
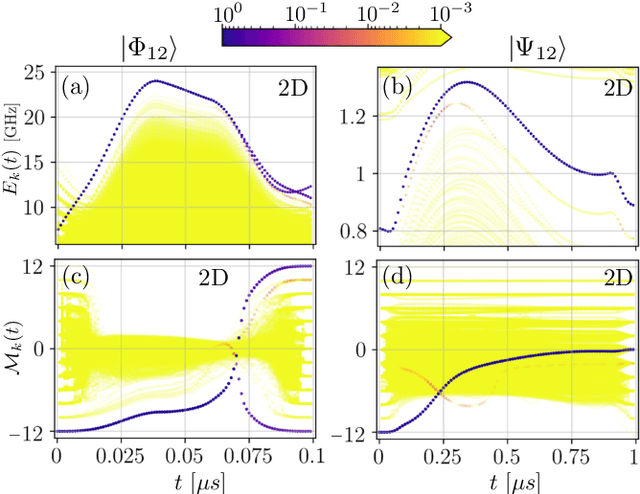
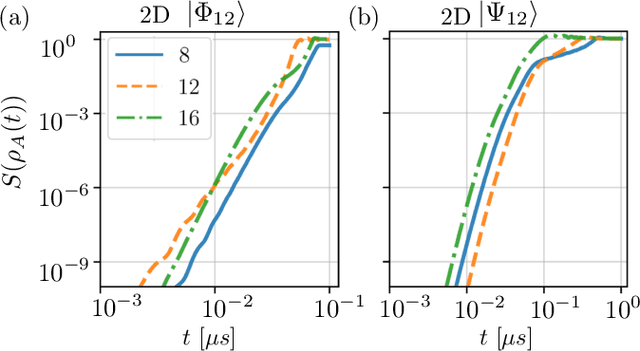
The ability to prepare non-classical states in a robust manner is essential for quantum sensors beyond the standard quantum limit. We demonstrate that Bayesian optimal control is capable of finding control pulses that drive trapped Rydberg atoms into highly entangled GHZ states. The control sequences that can be constructed in laboratory experiments result in preparation times that scale very favourably with the system size.
Preparation of ordered states in ultra-cold gases using Bayesian optimization
Jan 10, 2020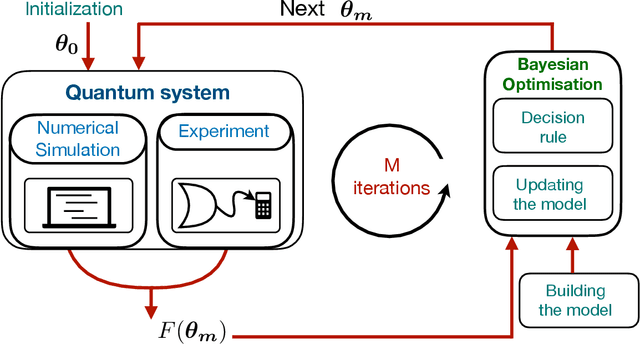
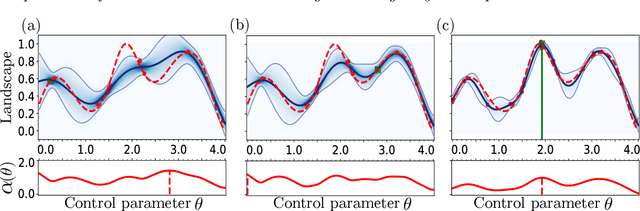
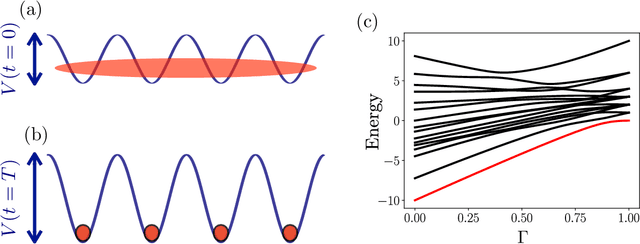
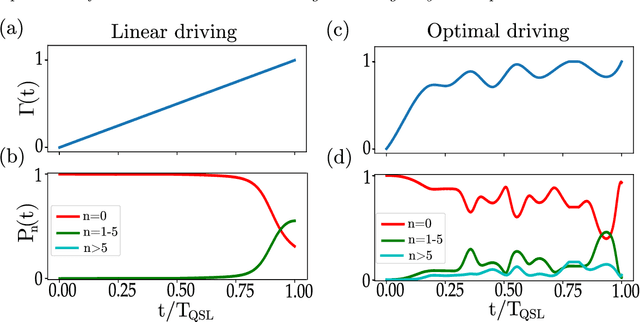
Ultra-cold atomic gases are unique in terms of the degree of controllability, both for internal and external degrees of freedom. This makes it possible to use them for the study of complex quantum many-body phenomena. However in many scenarios, the prerequisite condition of faithfully preparing a desired quantum state despite decoherence and system imperfections is not always adequately met. To path the way to a specific target state, we explore quantum optimal control framework based on Bayesian optimization. The probabilistic modeling and broad exploration aspects of Bayesian optimization is particularly suitable for quantum experiments where data acquisition can be expensive. Using numerical simulations for the superfluid to Mott-insulator transition for bosons in a lattice as well for the formation of Rydberg crystals as explicit examples, we demonstrate that Bayesian optimization is capable of finding better control solutions with regards to finite and noisy data compared to existing methods of optimal control.