 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient Timed Elastic Band Planner for Collision-Free Navigation in Unknown Environments
Dec 04, 2024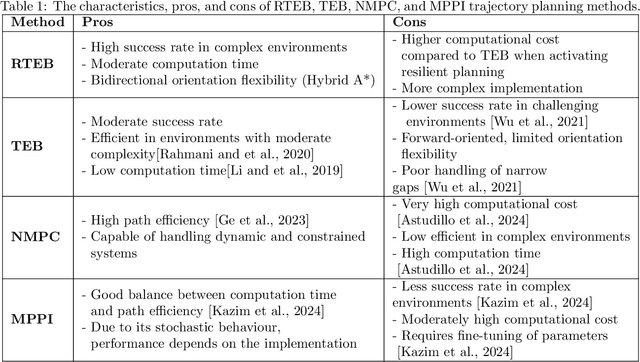
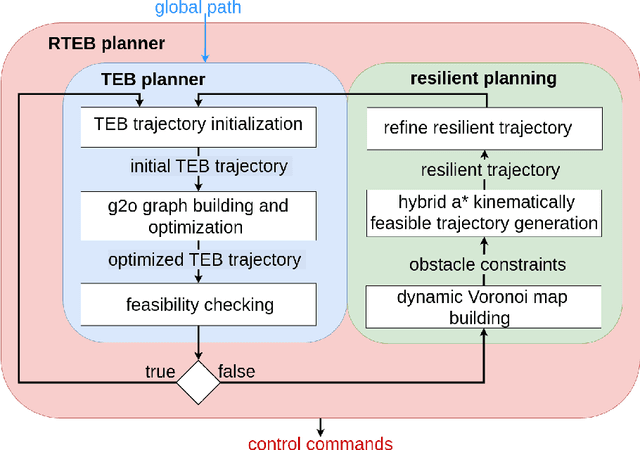
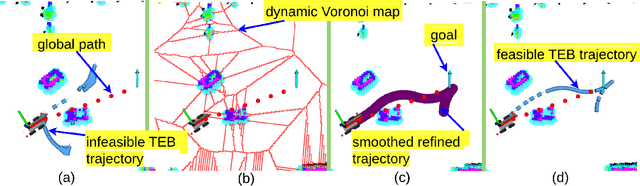
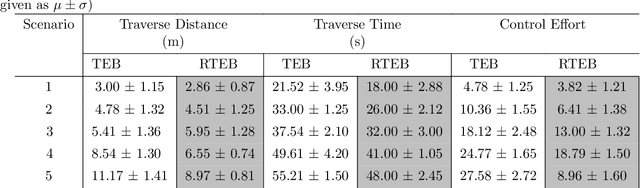
In autonomous navigation, trajectory replanning, refinement, and control command generation are essential for effective motion planning. This paper presents a resilient approach to trajectory replanning addressing scenarios where the initial planner's solution becomes infeasible. The proposed method incorporates a hybrid A* algorithm to generate feasible trajectories when the primary planner fails and applies a soft constraints-based smoothing technique to refine these trajectories, ensuring continuity, obstacle avoidance, and kinematic feasibility. Obstacle constraints are modelled using a dynamic Voronoi map to improve navigation through narrow passages. This approach enhances the consistency of trajectory planning, speeds up convergence, and meets real-time computational requirements. In environments with around 30\% or higher obstacle density, the ratio of free space before and after placing new obstacles, the Resilient Timed Elastic Band (RTEB) planner achieves approximately 20\% reduction in traverse distance, traverse time, and control effort compared to the Timed Elastic Band (TEB) planner and Nonlinear Model Predictive Control (NMPC) planner. These improvements demonstrate the RTEB planner's potential for application in field robotics, particularly in agricultural and industrial environments, where navigating unstructured terrain is crucial for ensuring efficiency and operational resilience.
Learning Manipulation Tasks in Dynamic and Shared 3D Spaces
Apr 26, 2024Automating the segregation process is a need for every sector experiencing a high volume of materials handling, repetitive and exhaustive operations, in addition to risky exposures. Learning automated pick-and-place operations can be efficiently done by introducing collaborative autonomous systems (e.g. manipulators) in the workplace and among human operators. In this paper, we propose a deep reinforcement learning strategy to learn the place task of multi-categorical items from a shared workspace between dual-manipulators and to multi-goal destinations, assuming the pick has been already completed. The learning strategy leverages first a stochastic actor-critic framework to train an agent's policy network, and second, a dynamic 3D Gym environment where both static and dynamic obstacles (e.g. human factors and robot mate) constitute the state space of a Markov decision process. Learning is conducted in a Gazebo simulator and experiments show an increase in cumulative reward function for the agent further away from human factors. Future investigations will be conducted to enhance the task performance for both agents simultaneously.