 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Audio-Visual Smartphone Dataset And Evaluation
Sep 09, 2021
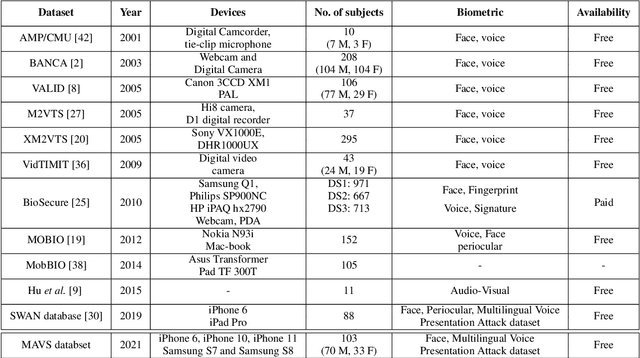


Smartphones have been employed with biometric-based verification systems to provide security in highly sensitive applications. Audio-visual biometrics are getting popular due to the usability and also it will be challenging to spoof because of multi-modal nature. In this work, we present an audio-visual smartphone dataset captured in five different recent smartphones. This new dataset contains 103 subjects captured in three different sessions considering the different real-world scenarios. Three different languages are acquired in this dataset to include the problem of language dependency of the speaker recognition systems. These unique characteristics of this dataset will pave the way to implement novel state-of-the-art unimodal or audio-visual speaker recognition systems. We also report the performance of the bench-marked biometric verification systems on our dataset. The robustness of biometric algorithms is evaluated towards multiple dependencies like signal noise, device, language and presentation attacks like replay and synthesized signals with extensive experiments. The obtained results raised many concerns about the generalization properties of state-of-the-art biometrics methods in smartphones.