 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Planning Framework for UAV-Based Surface Inspection in Partially Unknown Indoor Environments
Apr 12, 2025



Inspecting indoor environments such as tunnels, industrial facilities, and construction sites is essential for infrastructure monitoring and maintenance. While manual inspection in these environments is often time-consuming and potentially hazardous, Unmanned Aerial Vehicles (UAVs) can improve efficiency by autonomously handling inspection tasks. Such inspection tasks usually rely on reference maps for coverage planning. However, in industrial applications, only the floor plans are typically available. The unforeseen obstacles not included in the floor plans will result in outdated reference maps and inefficient or unsafe inspection trajectories. In this work, we propose an adaptive inspection framework that integrates global coverage planning with local reactive adaptation to improve the coverage and efficiency of UAV-based inspection in partially unknown indoor environments. Experimental results in structured indoor scenarios demonstrate the effectiveness of the proposed approach in inspection efficiency and achieving high coverage rates with adaptive obstacle handling, highlighting its potential for enhancing the efficiency of indoor facility inspection.
LV-DOT: LiDAR-visual dynamic obstacle detection and tracking for autonomous robot navigation
Feb 28, 2025


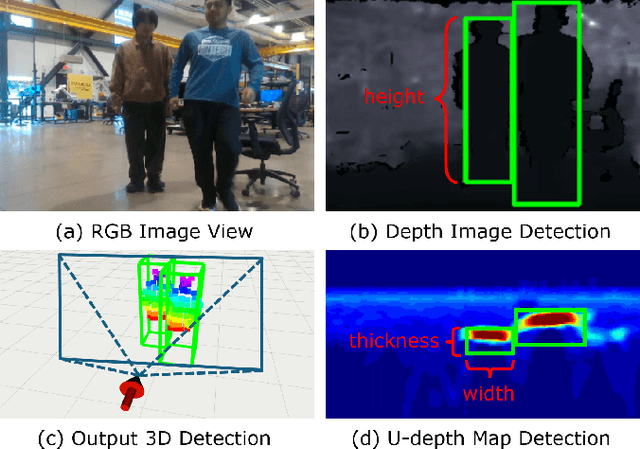
Accurate perception of dynamic obstacles is essential for autonomous robot navigation in indoor environments. Although sophisticated 3D object detection and tracking methods have been investigated and developed thoroughly in the fields of computer vision and autonomous driving, their demands on expensive and high-accuracy sensor setups and substantial computational resources from large neural networks make them unsuitable for indoor robotics. Recently, more lightweight perception algorithms leveraging onboard cameras or LiDAR sensors have emerged as promising alternatives. However, relying on a single sensor poses significant limitations: cameras have limited fields of view and can suffer from high noise, whereas LiDAR sensors operate at lower frequencies and lack the richness of visual features. To address this limitation, we propose a dynamic obstacle detection and tracking framework that uses both onboard camera and LiDAR data to enable lightweight and accurate perception. Our proposed method expands on our previous ensemble detection approach, which integrates outputs from multiple low-accuracy but computationally efficient detectors to ensure real-time performance on the onboard computer. In this work, we propose a more robust fusion strategy that integrates both LiDAR and visual data to enhance detection accuracy further. We then utilize a tracking module that adopts feature-based object association and the Kalman filter to track and estimate detected obstacles' states. Besides, a dynamic obstacle classification algorithm is designed to robustly identify moving objects. The dataset evaluation demonstrates a better perception performance compared to benchmark methods. The physical experiments on a quadcopter robot confirms the feasibility for real-world navigation.
FreeBlend: Advancing Concept Blending with Staged Feedback-Driven Interpolation Diffusion
Feb 08, 2025Concept blending is a promising yet underexplored area in generative models. While recent approaches, such as embedding mixing and latent modification based on structural sketches, have been proposed, they often suffer from incompatible semantic information and discrepancies in shape and appearance. In this work, we introduce FreeBlend, an effective, training-free framework designed to address these challenges. To mitigate cross-modal loss and enhance feature detail, we leverage transferred image embeddings as conditional inputs. The framework employs a stepwise increasing interpolation strategy between latents, progressively adjusting the blending ratio to seamlessly integrate auxiliary features. Additionally, we introduce a feedback-driven mechanism that updates the auxiliary latents in reverse order, facilitating global blending and preventing rigid or unnatural outputs. Extensive experiments demonstrate that our method significantly improves both the semantic coherence and visual quality of blended images, yielding compelling and coherent results.