 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoodpecker-DL: Accelerating Deep Neural Networks via Hardware-Aware Multifaceted Optimizations
Aug 11, 2020


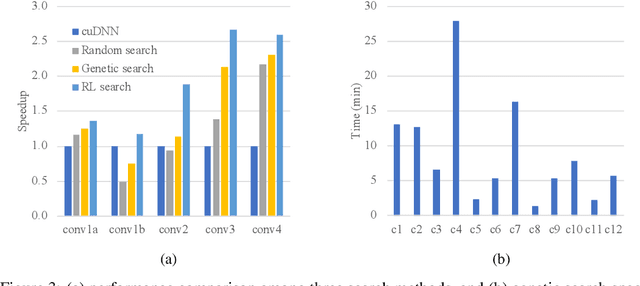
Accelerating deep model training and inference is crucial in practice. Existing deep learning frameworks usually concentrate on optimizing training speed and pay fewer attentions to inference-specific optimizations. Actually, model inference differs from training in terms of computation, e.g. parameters are refreshed each gradient update step during training, but kept invariant during inference. These special characteristics of model inference open new opportunities for its optimization. In this paper, we propose a hardware-aware optimization framework, namely Woodpecker-DL (WPK), to accelerate inference by taking advantage of multiple joint optimizations from the perspectives of graph optimization, automated searches, domain-specific language (DSL) compiler techniques and system-level exploration. In WPK, we investigated two new automated search approaches based on genetic algorithm and reinforcement learning, respectively, to hunt the best operator code configurations targeting specific hardware. A customized DSL compiler is further attached to these search algorithms to generate efficient codes. To create an optimized inference plan, WPK systematically explores high-speed operator implementations from third-party libraries besides our automatically generated codes and singles out the best implementation per operator for use. Extensive experiments demonstrated that on a Tesla P100 GPU, we can achieve the maximum speedup of 5.40 over cuDNN and 1.63 over TVM on individual convolution operators, and run up to 1.18 times faster than TensorRT for end-to-end model inference.