 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Kernel Tuning Parameter Prediction using Deep Sequence Models
Apr 15, 2024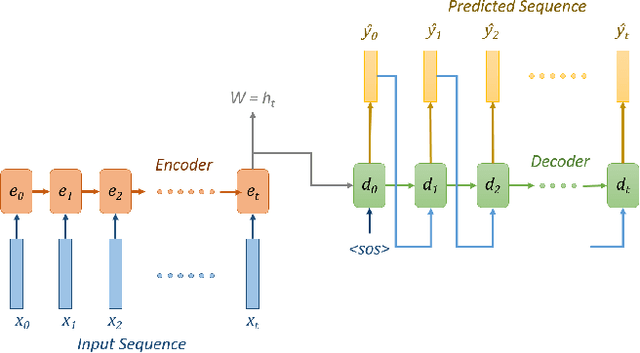
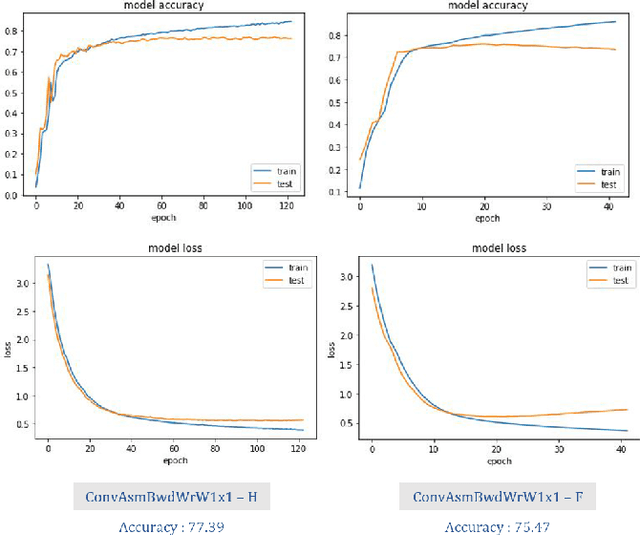
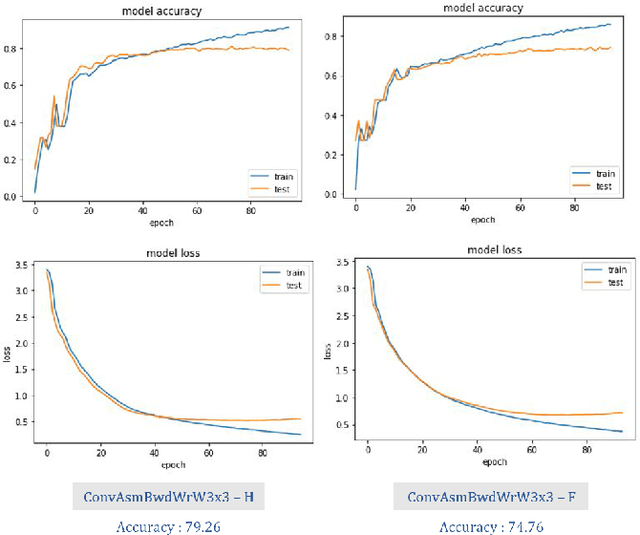

GPU kernels have come to the forefront of computing due to their utility in varied fields, from high-performance computing to machine learning. A typical GPU compute kernel is invoked millions, if not billions of times in a typical application, which makes their performance highly critical. Due to the unknown nature of the optimization surface, an exhaustive search is required to discover the global optimum, which is infeasible due to the possible exponential number of parameter combinations. In this work, we propose a methodology that uses deep sequence-to-sequence models to predict the optimal tuning parameters governing compute kernels. This work considers the prediction of kernel parameters as a sequence to the sequence translation problem, borrowing models from the Natural Language Processing (NLP) domain. Parameters describing the input, output and weight tensors are considered as the input language to the model that emits the corresponding kernel parameters. In essence, the model translates the problem parameter language to kernel parameter language. The core contributions of this work are: a) Proposing that a sequence to sequence model can accurately learn the performance dynamics of a GPU compute kernel b) A novel network architecture which predicts the kernel tuning parameters for GPU kernels, c) A constrained beam search which incorporates the physical limits of the GPU hardware as well as other expert knowledge reducing the search space. The proposed algorithm can achieve more than 90% accuracy on various convolutional kernels in MIOpen, the AMD machine learning primitives library. As a result, the proposed technique can reduce the development time and compute resources required to tune unseen input configurations, resulting in shorter development cycles, reduced development costs, and better user experience.
Replication of Multi-agent Reinforcement Learning for the "Hide and Seek" Problem
Oct 09, 2023



Reinforcement learning generates policies based on reward functions and hyperparameters. Slight changes in these can significantly affect results. The lack of documentation and reproducibility in Reinforcement learning research makes it difficult to replicate once-deduced strategies. While previous research has identified strategies using grounded maneuvers, there is limited work in more complex environments. The agents in this study are simulated similarly to Open Al's hider and seek agents, in addition to a flying mechanism, enhancing their mobility, and expanding their range of possible actions and strategies. This added functionality improves the Hider agents to develop a chasing strategy from approximately 2 million steps to 1.6 million steps and hiders
Low Resource Summarization using Pre-trained Language Models
Oct 04, 2023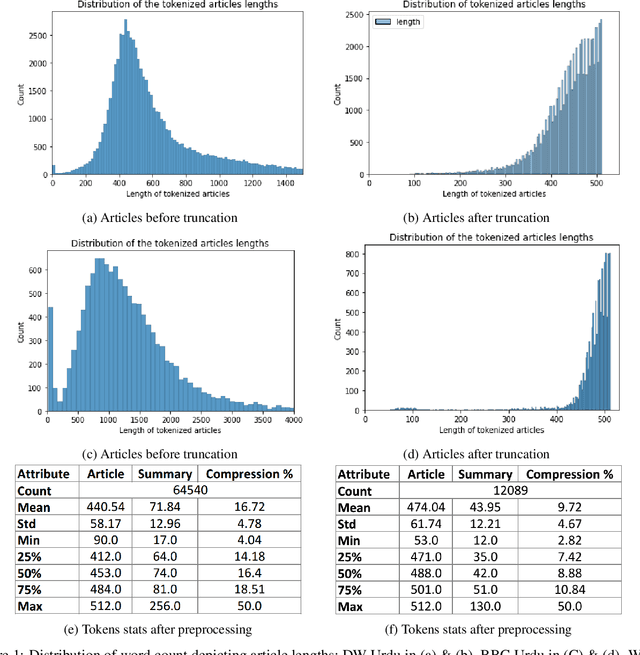
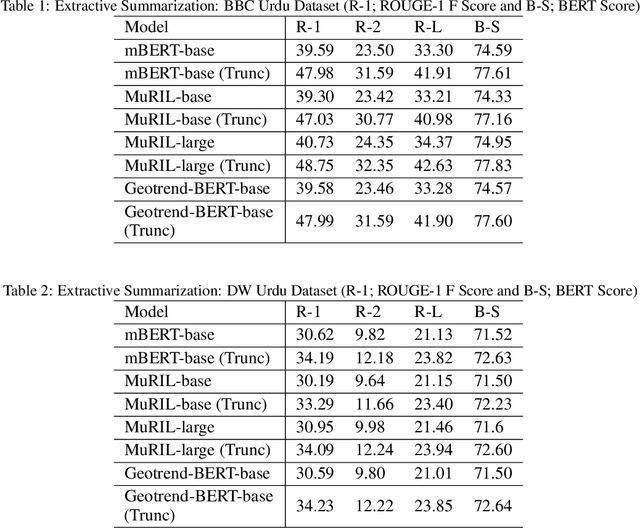
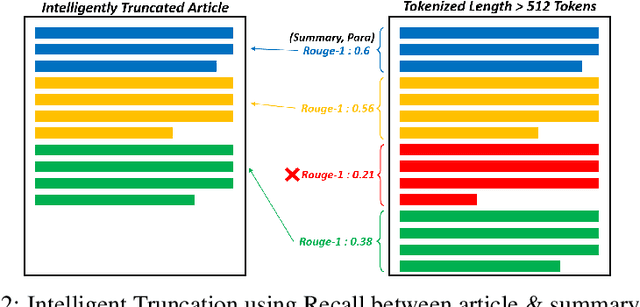
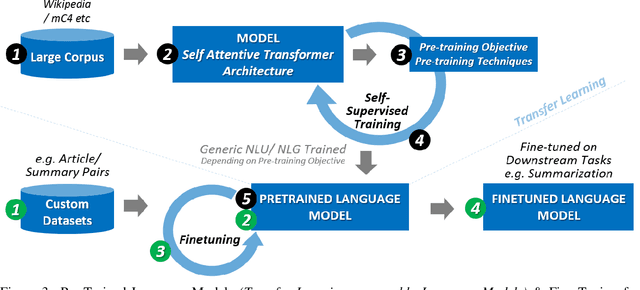
With the advent of Deep Learning based Artificial Neural Networks models, Natural Language Processing (NLP) has witnessed significant improvements in textual data processing in terms of its efficiency and accuracy. However, the research is mostly restricted to high-resource languages such as English and low-resource languages still suffer from a lack of available resources in terms of training datasets as well as models with even baseline evaluation results. Considering the limited availability of resources for low-resource languages, we propose a methodology for adapting self-attentive transformer-based architecture models (mBERT, mT5) for low-resource summarization, supplemented by the construction of a new baseline dataset (76.5k article, summary pairs) in a low-resource language Urdu. Choosing news (a publicly available source) as the application domain has the potential to make the proposed methodology useful for reproducing in other languages with limited resources. Our adapted summarization model \textit{urT5} with up to 44.78\% reduction in size as compared to \textit{mT5} can capture contextual information of low resource language effectively with evaluation score (up to 46.35 ROUGE-1, 77 BERTScore) at par with state-of-the-art models in high resource language English \textit{(PEGASUS: 47.21, BART: 45.14 on XSUM Dataset)}. The proposed method provided a baseline approach towards extractive as well as abstractive summarization with competitive evaluation results in a limited resource setup.
ECO-AMLP: A Decision Support System using an Enhanced Class Outlier with Automatic Multilayer Perceptron for Diabetes Prediction
Jun 23, 2017
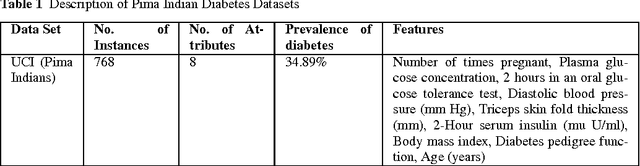
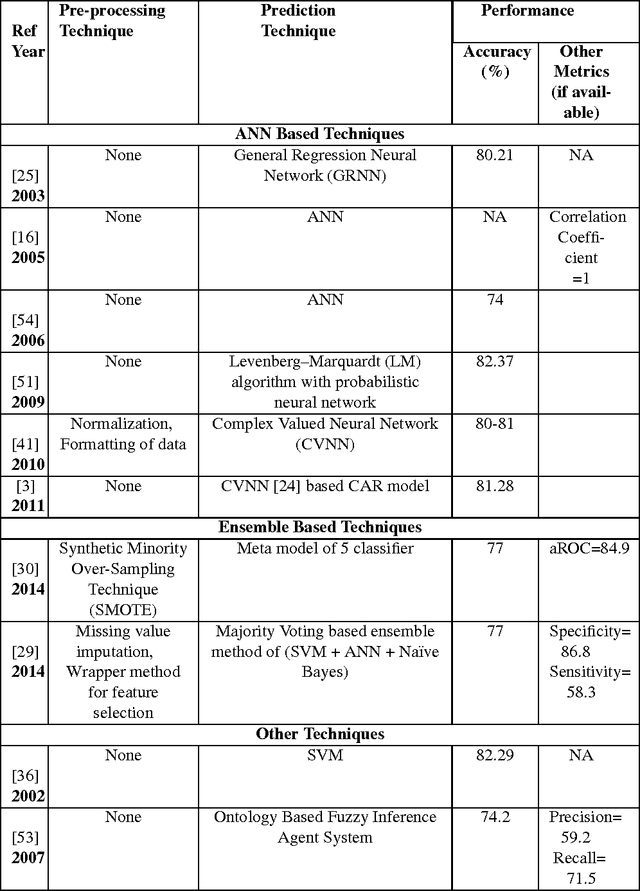
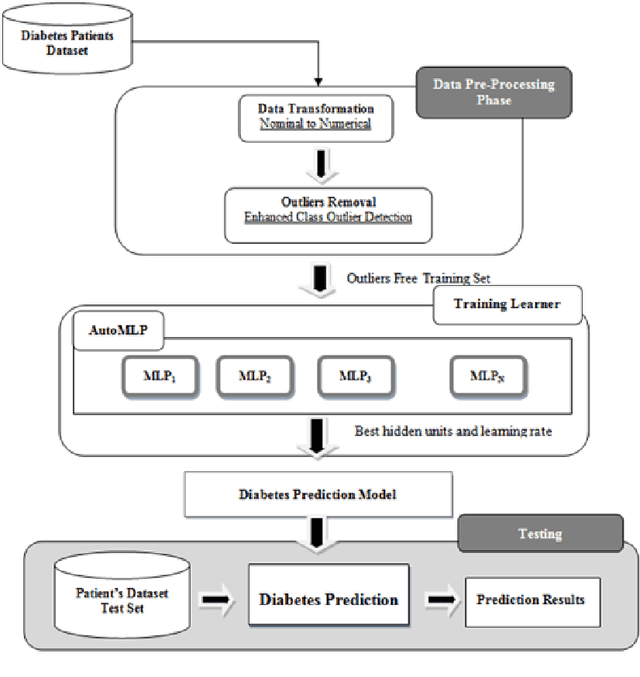
With advanced data analytical techniques, efforts for more accurate decision support systems for disease prediction are on rise. Surveys by World Health Organization (WHO) indicate a great increase in number of diabetic patients and related deaths each year. Early diagnosis of diabetes is a major concern among researchers and practitioners. The paper presents an application of \textit{Automatic Multilayer Perceptron }which\textit{ }is combined with an outlier detection method \textit{Enhanced Class Outlier Detection using distance based algorithm }to create a prediction framework named as Enhanced Class Outlier with Automatic Multi layer Perceptron (ECO-AMLP). A series of experiments are performed on publicly available Pima Indian Diabetes Dataset to compare ECO-AMLP with other individual classifiers as well as ensemble based methods. The outlier technique used in our framework gave better results as compared to other pre-processing and classification techniques. Finally, the results are compared with other state-of-the-art methods reported in literature for diabetes prediction on PIDD and achieved accuracy of 88.7\% bests all other reported studies.