 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Kernel Tuning Parameter Prediction using Deep Sequence Models
Paper and Code
Apr 15, 2024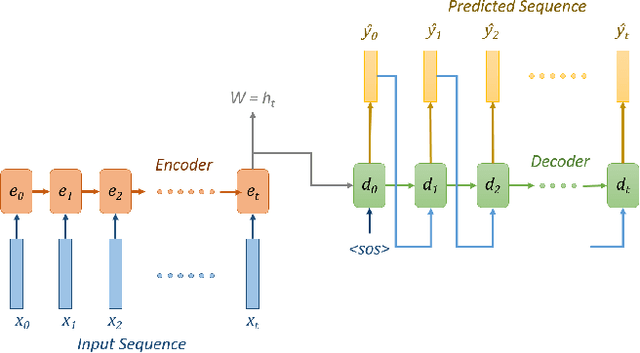
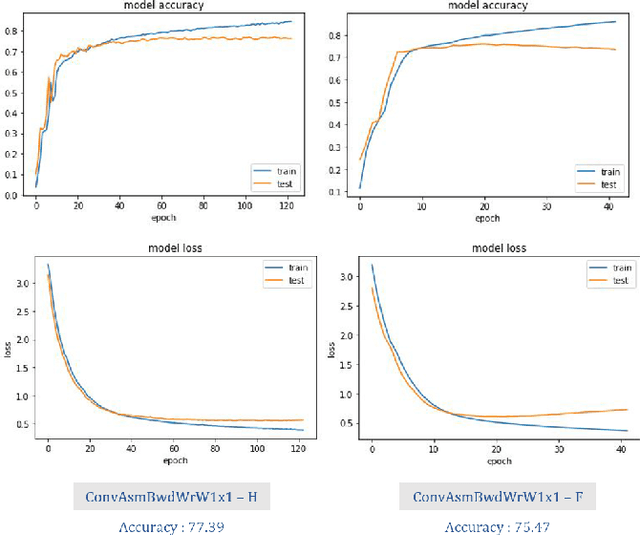
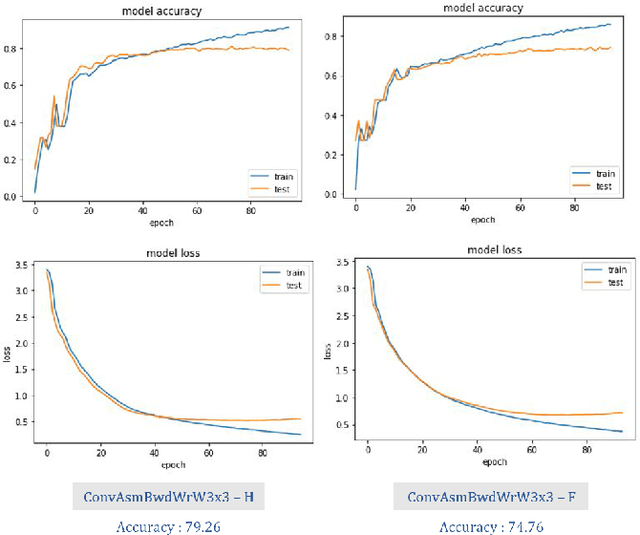

GPU kernels have come to the forefront of computing due to their utility in varied fields, from high-performance computing to machine learning. A typical GPU compute kernel is invoked millions, if not billions of times in a typical application, which makes their performance highly critical. Due to the unknown nature of the optimization surface, an exhaustive search is required to discover the global optimum, which is infeasible due to the possible exponential number of parameter combinations. In this work, we propose a methodology that uses deep sequence-to-sequence models to predict the optimal tuning parameters governing compute kernels. This work considers the prediction of kernel parameters as a sequence to the sequence translation problem, borrowing models from the Natural Language Processing (NLP) domain. Parameters describing the input, output and weight tensors are considered as the input language to the model that emits the corresponding kernel parameters. In essence, the model translates the problem parameter language to kernel parameter language. The core contributions of this work are: a) Proposing that a sequence to sequence model can accurately learn the performance dynamics of a GPU compute kernel b) A novel network architecture which predicts the kernel tuning parameters for GPU kernels, c) A constrained beam search which incorporates the physical limits of the GPU hardware as well as other expert knowledge reducing the search space. The proposed algorithm can achieve more than 90% accuracy on various convolutional kernels in MIOpen, the AMD machine learning primitives library. As a result, the proposed technique can reduce the development time and compute resources required to tune unseen input configurations, resulting in shorter development cycles, reduced development costs, and better user experience.