 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEAR: Certified Ensemble Adversarial Robustness in DNNs
May 31, 2026Deep Neural Networks (DNNs) are highly susceptible to adversarial perturbations, leading to extensive research on robustness for safety-critical applications. State-of-the-art empirical defense mechanisms improve the robustness of DNNs through the training phase, but still struggle against adaptive white-box attacks. On the other hand, certified defenses offer provable guarantees of robustness within a specified perturbation bound. These guarantees hold regardless of the level of perturbations, even if the attacker is given full knowledge of the model. In this paper, we propose CEAR, an ensemble-based robust method that utilizes a hybrid of empirical and certified defense mechanisms. CEAR trains each network within the ensemble using varying Gaussian noise and temperatures to obfuscate gradients and logits, making the model more resistant to stronger gradient-based attacks. We then use noisy logits and propose two different voting mechanisms to further improve robustness. Furthermore, we extend randomized smoothing to verify the robustness of ensemble-based classifiers. Our experimental evaluations on MNIST, CIFAR10, and TinyImageNet datasets demonstrate superior certified accuracy on average, increased robustness radius, and decreased transferability compared to baseline methods.
LLMs Uncertainty Quantification via Adaptive Conformal Semantic Entropy
May 05, 2026LLMs' overconfidence, particularly when hallucinating, poses a significant challenge for the deployment of the models in safety-critical settings and makes a reliable estimation of uncertainty necessary. Existing approaches for uncertainty quantification typically prioritize lexical or probabilistic measures; however, these techniques often ignore the semantic variance of different responses with similar meaning. In this paper, we propose Adaptive Conformal Semantic Entropy (ACSE), a method for estimating prompt-level uncertainty by adaptively measuring semantic dispersion in LLMs outputs. Our uncertainty scoring function is based on clustering semantic entropy of multiple diverse responses to the same prompt. The function adaptively adjusts the uncertainty score based on semantic features of each cluster. To ensure statistical reliability of our score, we use conformal calibration to apply a decision rule to accept/abstain the prompts, providing a finite-sample, distribution-free guarantee such that the error rate among the accepted responses remains bounded by a user-specified tolerance. Our extensive experimental evaluations using different LLMs and datasets, demonstrate that our approach consistently outperforms state-of-the-art uncertainty quantification baselines using discriminative performance, conformal guarantees, and probabilistic calibration indicators. As a highlight, for TriviaQA dataset, AUROC of our approach is 0.88 compared to 0.65 produced by the token entropy approach.
Evidential Uncertainty Sets in Deep Classifiers Using Conformal Prediction
Jun 16, 2024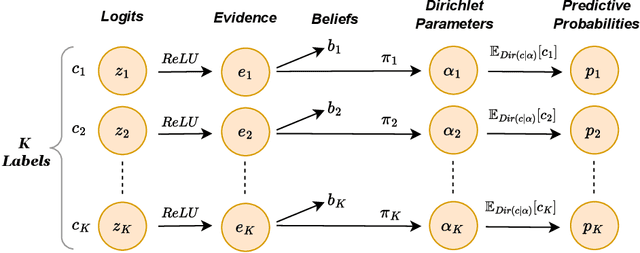
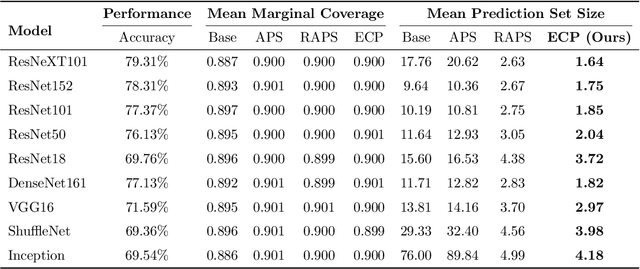
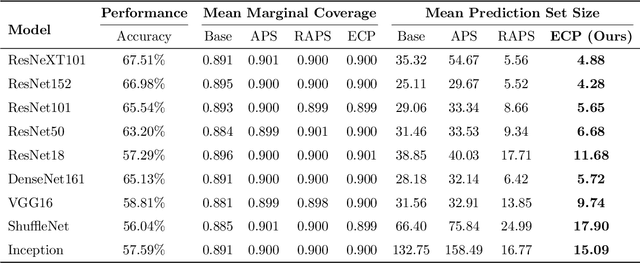
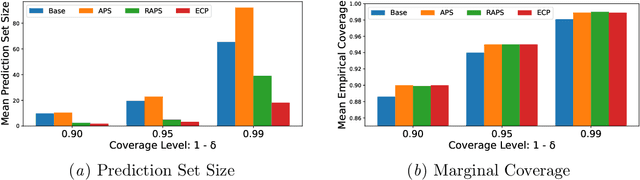
In this paper, we propose Evidential Conformal Prediction (ECP) method for image classifiers to generate the conformal prediction sets. Our method is designed based on a non-conformity score function that has its roots in Evidential Deep Learning (EDL) as a method of quantifying model (epistemic) uncertainty in DNN classifiers. We use evidence that are derived from the logit values of target labels to compute the components of our non-conformity score function: the heuristic notion of uncertainty in CP, uncertainty surprisal, and expected utility. Our extensive experimental evaluation demonstrates that ECP outperforms three state-of-the-art methods for generating CP sets, in terms of their set sizes and adaptivity while maintaining the coverage of true labels.
Quantifying Deep Learning Model Uncertainty in Conformal Prediction
Jun 01, 2023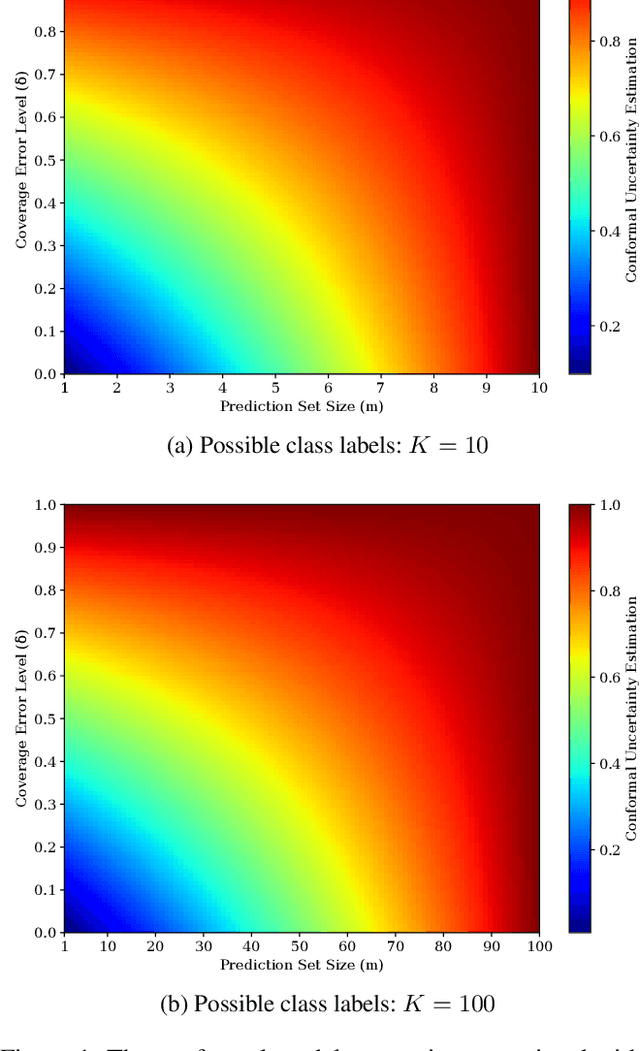
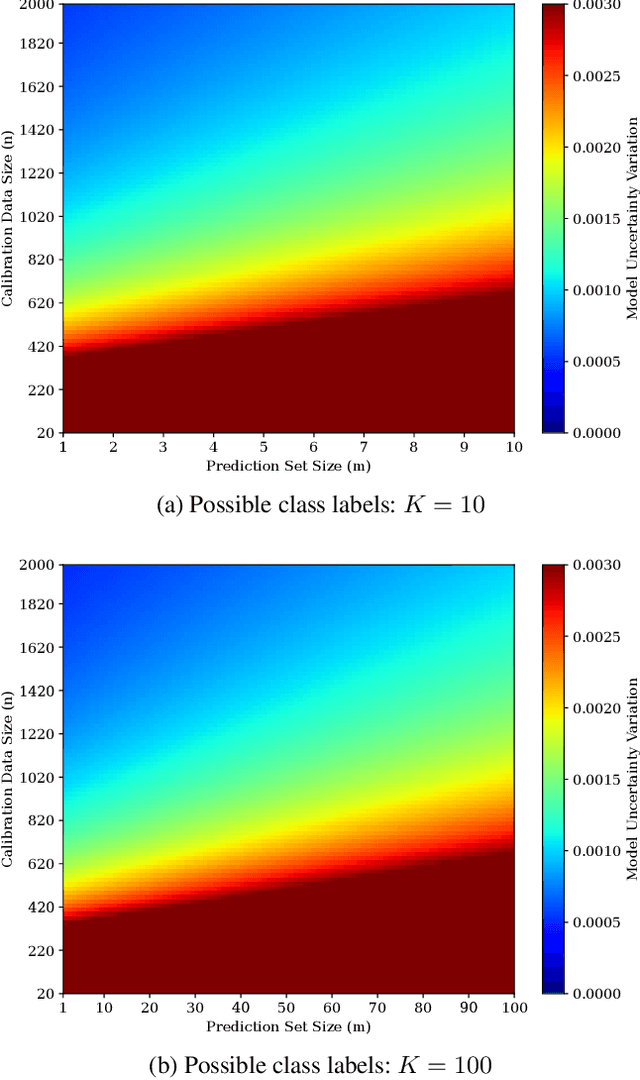
Precise estimation of predictive uncertainty in deep neural networks is a critical requirement for reliable decision-making in machine learning and statistical modeling, particularly in the context of medical AI. Conformal Prediction (CP) has emerged as a promising framework for representing the model uncertainty by providing well-calibrated confidence levels for individual predictions. However, the quantification of model uncertainty in conformal prediction remains an active research area, yet to be fully addressed. In this paper, we explore state-of-the-art CP methodologies and their theoretical foundations. We propose a probabilistic approach in quantifying the model uncertainty derived from the produced prediction sets in conformal prediction and provide certified boundaries for the computed uncertainty. By doing so, we allow model uncertainty measured by CP to be compared by other uncertainty quantification methods such as Bayesian (e.g., MC-Dropout and DeepEnsemble) and Evidential approaches.
Linear Convergence of Gradient and Proximal-Gradient Methods Under the Polyak-Łojasiewicz Condition
Jun 11, 2018In 1963, Polyak proposed a simple condition that is sufficient to show a global linear convergence rate for gradient descent. This condition is a special case of the \L{}ojasiewicz inequality proposed in the same year, and it does not require strong convexity (or even convexity). In this work, we show that this much-older Polyak-\L{}ojasiewicz (PL) inequality is actually weaker than the main conditions that have been explored to show linear convergence rates without strong convexity over the last 25 years. We also use the PL inequality to give new analyses of randomized and greedy coordinate descent methods, sign-based gradient descent methods, and stochastic gradient methods in the classic setting (with decreasing or constant step-sizes) as well as the variance-reduced setting. We further propose a generalization that applies to proximal-gradient methods for non-smooth optimization, leading to simple proofs of linear convergence of these methods. Along the way, we give simple convergence results for a wide variety of problems in machine learning: least squares, logistic regression, boosting, resilient backpropagation, L1-regularization, support vector machines, stochastic dual coordinate ascent, and stochastic variance-reduced gradient methods.