 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Relocation Tracking in Dynamic Kitchen Environments
Mar 03, 2025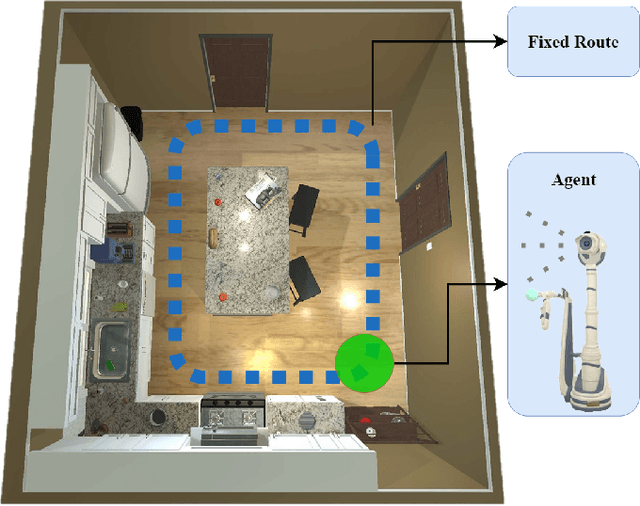

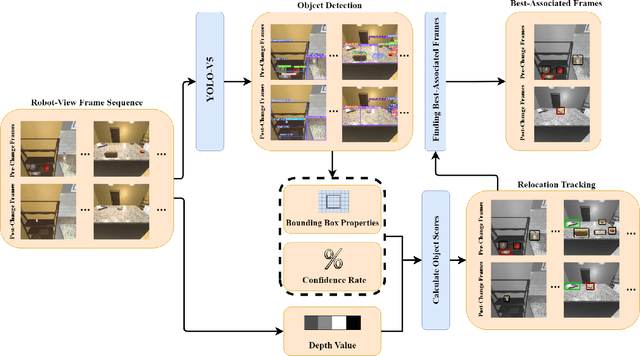
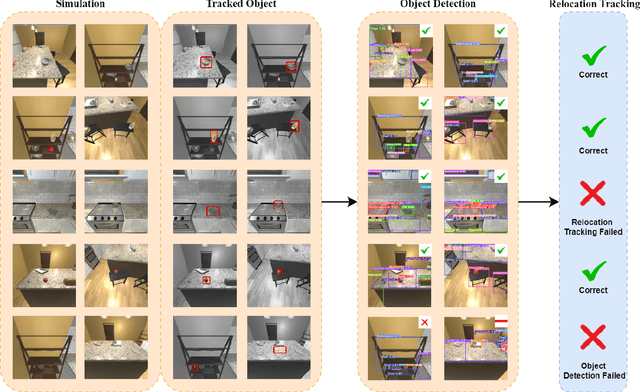
As smart homes become more prevalent in daily life, the ability to understand dynamic environments is essential which is increasingly dependent on AI systems. This study focuses on developing an intelligent algorithm which can navigate a robot through a kitchen, recognizing objects, and tracking their relocation. The kitchen was chosen as the testing ground due to its dynamic nature as objects are frequently moved, rearranged and replaced. Various techniques, such as SLAM feature-based tracking and deep learning-based object detection (e.g., Faster R-CNN), are commonly used for object tracking. Additionally, methods such as optical flow analysis and 3D reconstruction have also been used to track the relocation of objects. These approaches often face challenges when it comes to problems such as lighting variations and partial occlusions, where parts of the object are hidden in some frames but visible in others. The proposed method in this study leverages the YOLOv5 architecture, initialized with pre-trained weights and subsequently fine-tuned on a custom dataset. A novel method was developed, introducing a frame-scoring algorithm which calculates a score for each object based on its location and features within all frames. This scoring approach helps to identify changes by determining the best-associated frame for each object and comparing the results in each scene, overcoming limitations seen in other methods while maintaining simplicity in design. The experimental results demonstrate an accuracy of 97.72%, a precision of 95.83% and a recall of 96.84% for this algorithm, which highlights the efficacy of the model in detecting spatial changes.
Scene Understanding in Pick-and-Place Tasks: Analyzing Transformations Between Initial and Final Scenes
Sep 26, 2024



With robots increasingly collaborating with humans in everyday tasks, it is important to take steps toward robotic systems capable of understanding the environment. This work focuses on scene understanding to detect pick and place tasks given initial and final images from the scene. To this end, a dataset is collected for object detection and pick and place task detection. A YOLOv5 network is subsequently trained to detect the objects in the initial and final scenes. Given the detected objects and their bounding boxes, two methods are proposed to detect the pick and place tasks which transform the initial scene into the final scene. A geometric method is proposed which tracks objects' movements in the two scenes and works based on the intersection of the bounding boxes which moved within scenes. Contrarily, the CNN-based method utilizes a Convolutional Neural Network to classify objects with intersected bounding boxes into 5 classes, showing the spatial relationship between the involved objects. The performed pick and place tasks are then derived from analyzing the experiments with both scenes. Results show that the CNN-based method, using a VGG16 backbone, outscores the geometric method by roughly 12 percentage points in certain scenarios, with an overall success rate of 84.3%.
Improving the Successful Robotic Grasp Detection Using Convolutional Neural Networks
Mar 08, 2024Robotic grasp should be carried out in a real-time manner by proper accuracy. Perception is the first and significant step in this procedure. This paper proposes an improved pipeline model trying to detect grasp as a rectangle representation for different seen or unseen objects. It helps the robot to start control procedures from nearer to the proper part of the object. The main idea consists in pre-processing, output normalization, and data augmentation to improve accuracy by 4.3 percent without making the system slow. Also, a comparison has been conducted over different pre-trained models like AlexNet, ResNet, Vgg19, which are the most famous feature extractors for image processing in object detection. Although AlexNet has less complexity than other ones, it outperformed them, which helps the real-time property.
AGILE: Approach-based Grasp Inference Learned from Element Decomposition
Feb 06, 2024



Humans, this species expert in grasp detection, can grasp objects by taking into account hand-object positioning information. This work proposes a method to enable a robot manipulator to learn the same, grasping objects in the most optimal way according to how the gripper has approached the object. Built on deep learning, the proposed method consists of two main stages. In order to generalize the network on unseen objects, the proposed Approach-based Grasping Inference involves an element decomposition stage to split an object into its main parts, each with one or more annotated grasps for a particular approach of the gripper. Subsequently, a grasp detection network utilizes the decomposed elements by Mask R-CNN and the information on the approach of the gripper in order to detect the element the gripper has approached and the most optimal grasp. In order to train the networks, the study introduces a robotic grasping dataset collected in the Coppeliasim simulation environment. The dataset involves 10 different objects with annotated element decomposition masks and grasp rectangles. The proposed method acquires a 90% grasp success rate on seen objects and 78% on unseen objects in the Coppeliasim simulation environment. Lastly, simulation-to-reality domain adaptation is performed by applying transformations on the training set collected in simulation and augmenting the dataset, which results in a 70% physical grasp success performance using a Delta parallel robot and a 2 -fingered gripper.