 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Document Classification Using Labeled and Unlabeled Data Across Hospitals
Dec 04, 2018
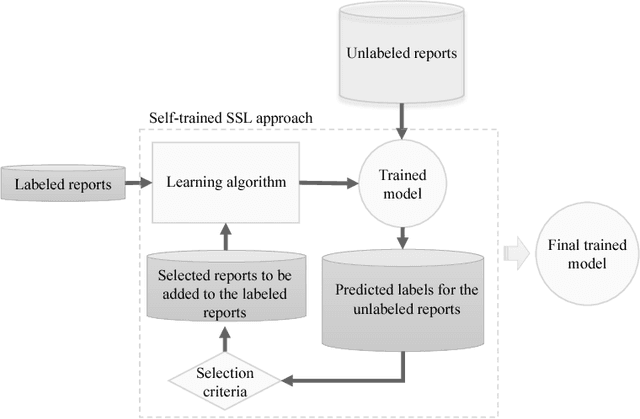

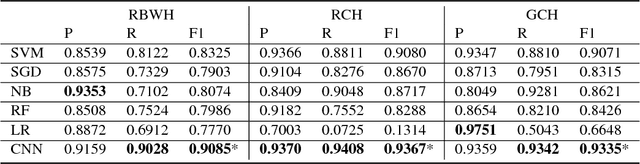
Reviewing radiology reports in emergency departments is an essential but laborious task. Timely follow-up of patients with abnormal cases in their radiology reports may dramatically affect the patient's outcome, especially if they have been discharged with a different initial diagnosis. Machine learning approaches have been devised to expedite the process and detect the cases that demand instant follow up. However, these approaches require a large amount of labeled data to train reliable predictive models. Preparing such a large dataset, which needs to be manually annotated by health professionals, is costly and time-consuming. This paper investigates a semi-supervised learning framework for radiology report classification across three hospitals. The main goal is to leverage clinical unlabeled data in order to augment the learning process where limited labeled data is available. To further improve the classification performance, we also integrate a transfer learning technique into the semi-supervised learning pipeline . Our experimental findings show that (1) convolutional neural networks (CNNs), while being independent of any problem-specific feature engineering, achieve significantly higher effectiveness compared to conventional supervised learning approaches, (2) leveraging unlabeled data in training a CNN-based classifier reduces the dependency on labeled data by more than 50% to reach the same performance of a fully supervised CNN, and (3) transferring the knowledge gained from available labeled data in an external source hospital significantly improves the performance of a semi-supervised CNN model over their fully supervised counterparts in a target hospital.
A Machine Learning Based Analytical Framework for Semantic Annotation Requirements
Apr 26, 2011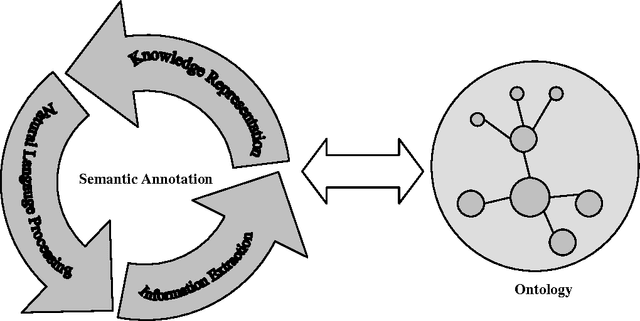
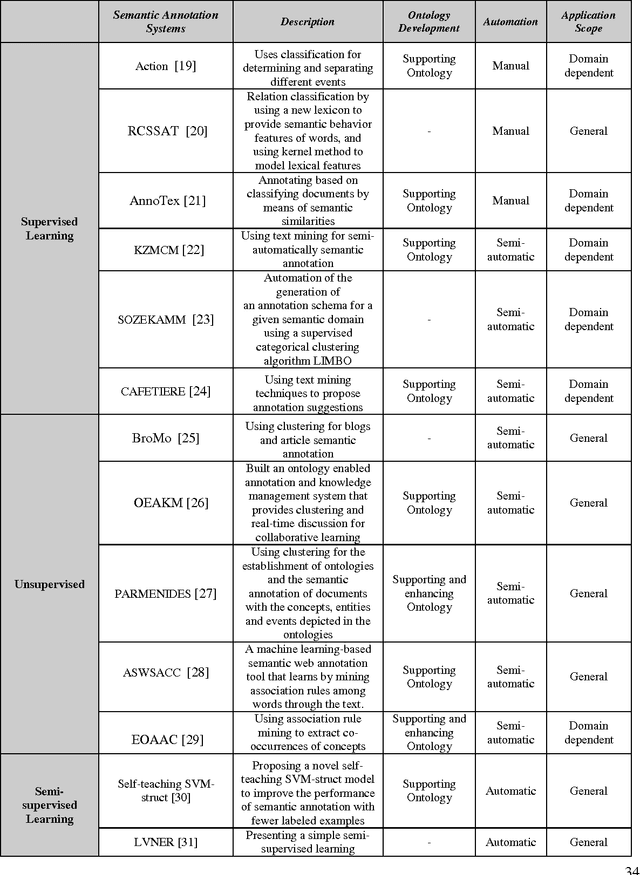
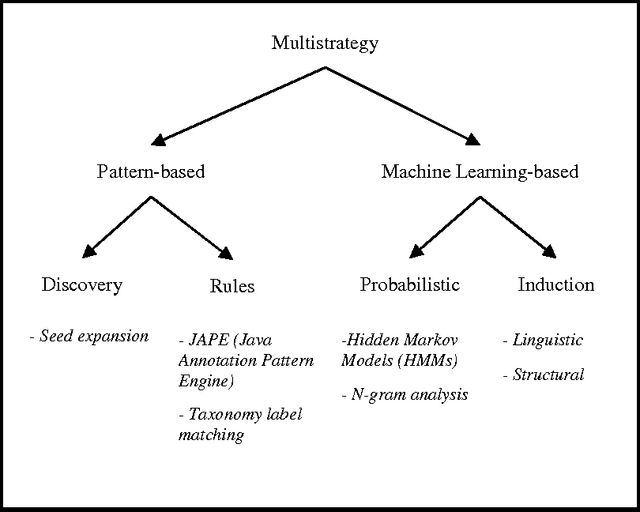
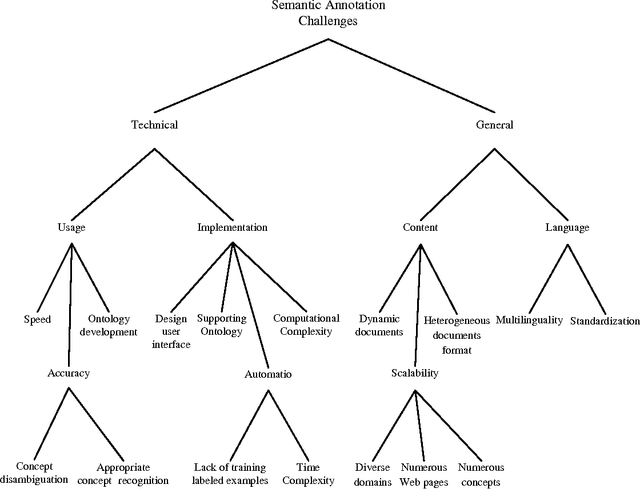
The Semantic Web is an extension of the current web in which information is given well-defined meaning. The perspective of Semantic Web is to promote the quality and intelligence of the current web by changing its contents into machine understandable form. Therefore, semantic level information is one of the cornerstones of the Semantic Web. The process of adding semantic metadata to web resources is called Semantic Annotation. There are many obstacles against the Semantic Annotation, such as multilinguality, scalability, and issues which are related to diversity and inconsistency in content of different web pages. Due to the wide range of domains and the dynamic environments that the Semantic Annotation systems must be performed on, the problem of automating annotation process is one of the significant challenges in this domain. To overcome this problem, different machine learning approaches such as supervised learning, unsupervised learning and more recent ones like, semi-supervised learning and active learning have been utilized. In this paper we present an inclusive layered classification of Semantic Annotation challenges and discuss the most important issues in this field. Also, we review and analyze machine learning applications for solving semantic annotation problems. For this goal, the article tries to closely study and categorize related researches for better understanding and to reach a framework that can map machine learning techniques into the Semantic Annotation challenges and requirements.