 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomers Behavior Modeling by Semi-Supervised Learning in Customer Relationship Management
Jan 08, 2012



Leveraging the power of increasing amounts of data to analyze customer base for attracting and retaining the most valuable customers is a major problem facing companies in this information age. Data mining technologies extract hidden information and knowledge from large data stored in databases or data warehouses, thereby supporting the corporate decision making process. CRM uses data mining (one of the elements of CRM) techniques to interact with customers. This study investigates the use of a technique, semi-supervised learning, for the management and analysis of customer-related data warehouse and information. The idea of semi-supervised learning is to learn not only from the labeled training data, but to exploit also the structural information in additionally available unlabeled data. The proposed semi-supervised method is a model by means of a feed-forward neural network trained by a back propagation algorithm (multi-layer perceptron) in order to predict the category of an unknown customer (potential customers). In addition, this technique can be used with Rapid Miner tools for both labeled and unlabeled data.
A New Color Feature Extraction Method Based on Dynamic Color Distribution Entropy of Neighborhoods
Jan 08, 2012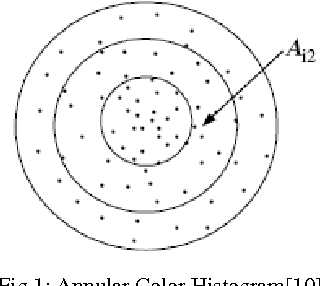
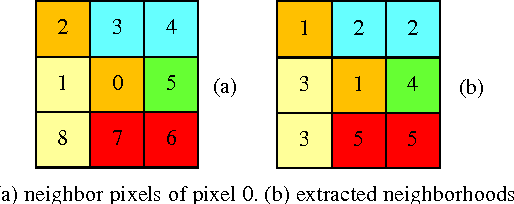
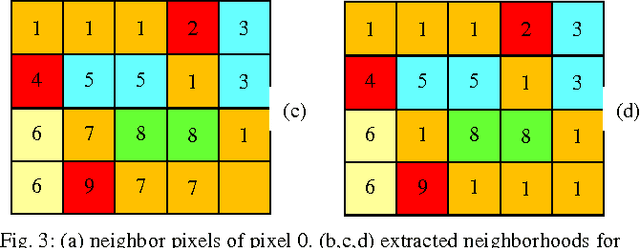
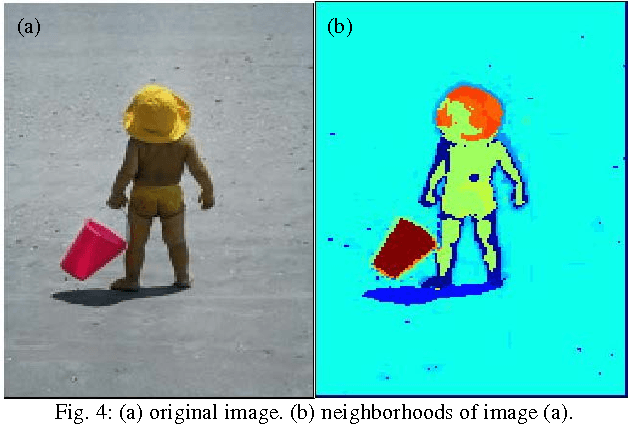
One of the important requirements in image retrieval, indexing, classification, clustering and etc. is extracting efficient features from images. The color feature is one of the most widely used visual features. Use of color histogram is the most common way for representing color feature. One of disadvantage of the color histogram is that it does not take the color spatial distribution into consideration. In this paper dynamic color distribution entropy of neighborhoods method based on color distribution entropy is presented, which effectively describes the spatial information of colors. The image retrieval results in compare to improved color distribution entropy show the acceptable efficiency of this approach.
A Machine Learning Based Analytical Framework for Semantic Annotation Requirements
Apr 26, 2011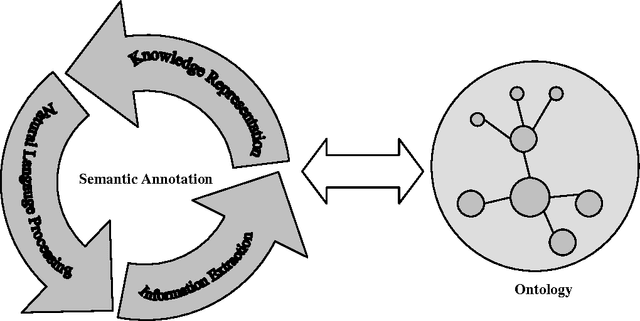
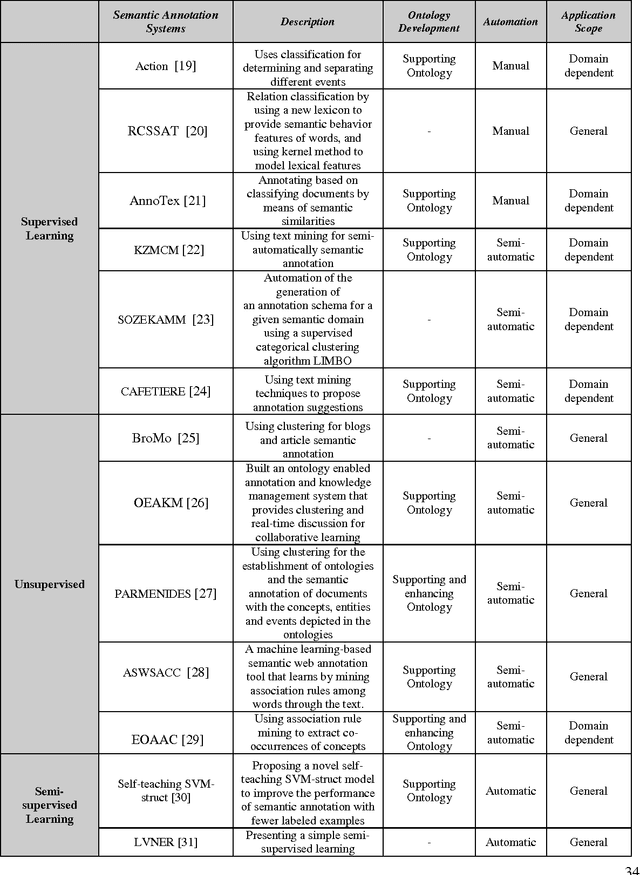
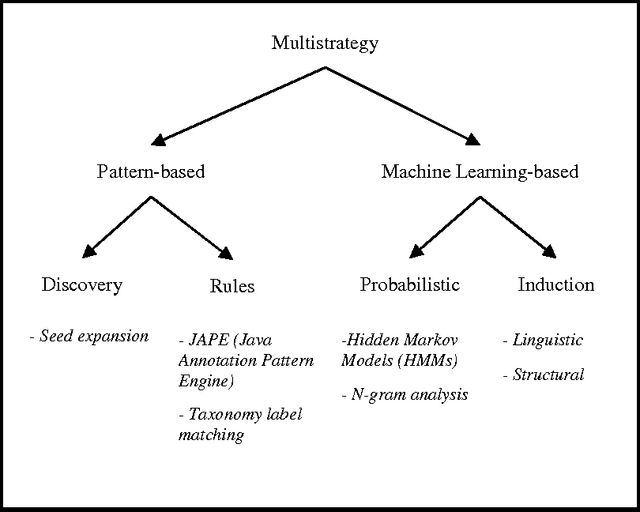
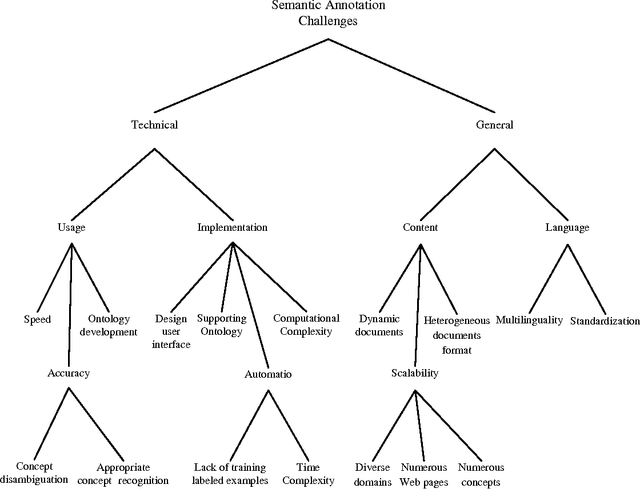
The Semantic Web is an extension of the current web in which information is given well-defined meaning. The perspective of Semantic Web is to promote the quality and intelligence of the current web by changing its contents into machine understandable form. Therefore, semantic level information is one of the cornerstones of the Semantic Web. The process of adding semantic metadata to web resources is called Semantic Annotation. There are many obstacles against the Semantic Annotation, such as multilinguality, scalability, and issues which are related to diversity and inconsistency in content of different web pages. Due to the wide range of domains and the dynamic environments that the Semantic Annotation systems must be performed on, the problem of automating annotation process is one of the significant challenges in this domain. To overcome this problem, different machine learning approaches such as supervised learning, unsupervised learning and more recent ones like, semi-supervised learning and active learning have been utilized. In this paper we present an inclusive layered classification of Semantic Annotation challenges and discuss the most important issues in this field. Also, we review and analyze machine learning applications for solving semantic annotation problems. For this goal, the article tries to closely study and categorize related researches for better understanding and to reach a framework that can map machine learning techniques into the Semantic Annotation challenges and requirements.