 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Graph Representation Learning for Depression Screening with Transformer
May 10, 2023Early detection of mental disorder is crucial as it enables prompt intervention and treatment, which can greatly improve outcomes for individuals suffering from debilitating mental affliction. The recent proliferation of mental health discussions on social media platforms presents research opportunities to investigate mental health and potentially detect instances of mental illness. However, existing depression detection methods are constrained due to two major limitations: (1) the reliance on feature engineering and (2) the lack of consideration for time-varying factors. Specifically, these methods require extensive feature engineering and domain knowledge, which heavily rely on the amount, quality, and type of user-generated content. Moreover, these methods ignore the important impact of time-varying factors on depression detection, such as the dynamics of linguistic patterns and interpersonal interactive behaviors over time on social media (e.g., replies, mentions, and quote-tweets). To tackle these limitations, we propose an early depression detection framework, ContrastEgo treats each user as a dynamic time-evolving attributed graph (ego-network) and leverages supervised contrastive learning to maximize the agreement of users' representations at different scales while minimizing the agreement of users' representations to differentiate between depressed and control groups. ContrastEgo embraces four modules, (1) constructing users' heterogeneous interactive graphs, (2) extracting the representations of users' interaction snapshots using graph neural networks, (3) modeling the sequences of snapshots using attention mechanism, and (4) depression detection using contrastive learning. Extensive experiments on Twitter data demonstrate that ContrastEgo significantly outperforms the state-of-the-art methods in terms of all the effectiveness metrics in various experimental settings.
Spatial Classification With Limited Observations Based On Physics-Aware Structural Constraint
Aug 25, 2020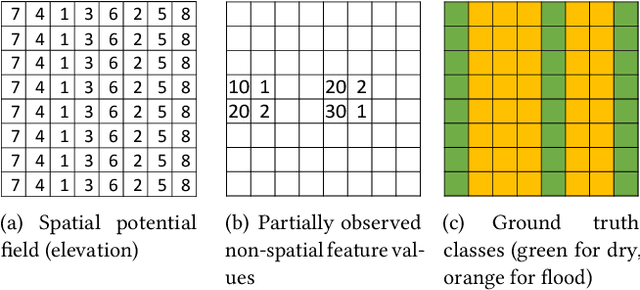

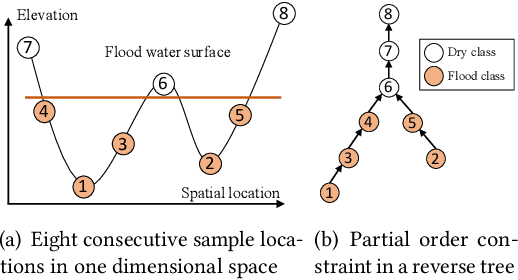

Spatial classification with limited feature observations has been a challenging problem in machine learning. The problem exists in applications where only a subset of sensors are deployed at certain spots or partial responses are collected in field surveys. Existing research mostly focuses on addressing incomplete or missing data, e.g., data cleaning and imputation, classification models that allow for missing feature values or model missing features as hidden variables in the EM algorithm. These methods, however, assume that incomplete feature observations only happen on a small subset of samples, and thus cannot solve problems where the vast majority of samples have missing feature observations. To address this issue, we recently proposed a new approach that incorporates physics-aware structural constraint into the model representation. Our approach assumes that a spatial contextual feature is observed for all sample locations and establishes spatial structural constraint from the underlying spatial contextual feature map. We design efficient algorithms for model parameter learning and class inference. This paper extends our recent approach by allowing feature values of samples in each class to follow a multi-modal distribution. We propose learning algorithms for the extended model with multi-modal distribution. Evaluations on real-world hydrological applications show that our approach significantly outperforms baseline methods in classification accuracy, and the multi-modal extension is more robust than our early single-modal version especially when feature distribution in training samples is multi-modal. Computational experiments show that the proposed solution is computationally efficient on large datasets.