 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSRNet: A Multi-Scale Recursive Network for Camouflaged Object Detection
Nov 16, 2025
Camouflaged object detection is an emerging and challenging computer vision task that requires identifying and segmenting objects that blend seamlessly into their environments due to high similarity in color, texture, and size. This task is further complicated by low-light conditions, partial occlusion, small object size, intricate background patterns, and multiple objects. While many sophisticated methods have been proposed for this task, current methods still struggle to precisely detect camouflaged objects in complex scenarios, especially with small and multiple objects, indicating room for improvement. We propose a Multi-Scale Recursive Network that extracts multi-scale features via a Pyramid Vision Transformer backbone and combines them via specialized Attention-Based Scale Integration Units, enabling selective feature merging. For more precise object detection, our decoder recursively refines features by incorporating Multi-Granularity Fusion Units. A novel recursive-feedback decoding strategy is developed to enhance global context understanding, helping the model overcome the challenges in this task. By jointly leveraging multi-scale learning and recursive feature optimization, our proposed method achieves performance gains, successfully detecting small and multiple camouflaged objects. Our model achieves state-of-the-art results on two benchmark datasets for camouflaged object detection and ranks second on the remaining two. Our codes, model weights, and results are available at \href{https://github.com/linaagh98/MSRNet}{https://github.com/linaagh98/MSRNet}.
Seeing Structural Failure Before it Happens: An Image-Based Physics-Informed Neural Network (PINN) for Spaghetti Bridge Load Prediction
Oct 27, 2025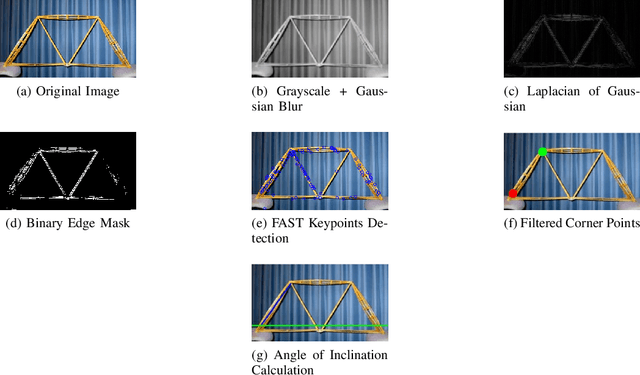



Physics Informed Neural Networks (PINNs) are gaining attention for their ability to embed physical laws into deep learning models, which is particularly useful in structural engineering tasks with limited data. This paper aims to explore the use of PINNs to predict the weight of small scale spaghetti bridges, a task relevant to understanding load limits and potential failure modes in simplified structural models. Our proposed framework incorporates physics-based constraints to the prediction model for improved performance. In addition to standard PINNs, we introduce a novel architecture named Physics Informed Kolmogorov Arnold Network (PIKAN), which blends universal function approximation theory with physical insights. The structural parameters provided as input to the model are collected either manually or through computer vision methods. Our dataset includes 15 real bridges, augmented to 100 samples, and our best model achieves an $R^2$ score of 0.9603 and a mean absolute error (MAE) of 10.50 units. From applied perspective, we also provide a web based interface for parameter entry and prediction. These results show that PINNs can offer reliable estimates of structural weight, even with limited data, and may help inform early stage failure analysis in lightweight bridge designs. The complete data and code are available at https://github.com/OmerJauhar/PINNS-For-Spaghetti-Bridges.
Vehicle and License Plate Recognition with Novel Dataset for Toll Collection
Feb 11, 2022

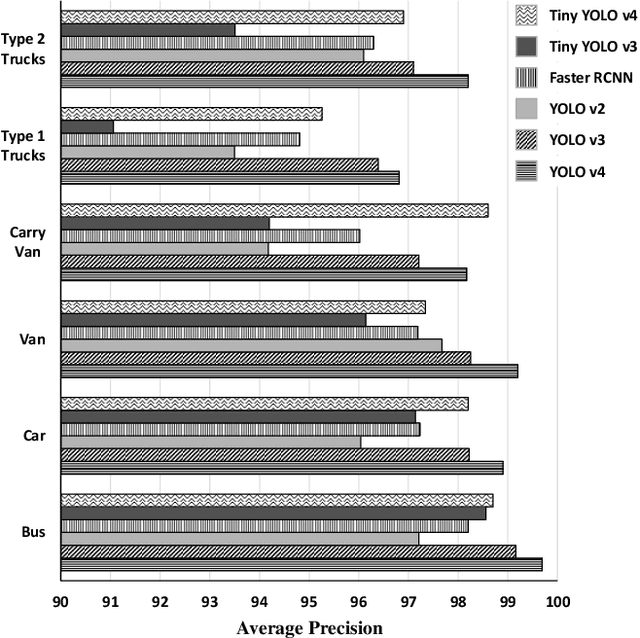

We propose an automatic framework for toll collection, consisting of three steps: vehicle type recognition, license plate localization, and reading. However, each of the three steps becomes non-trivial due to image variations caused by several factors. The traditional vehicle decorations on the front cause variations among vehicles of the same type. These decorations make license plate localization and recognition difficult due to severe background clutter and partial occlusions. Likewise, on most vehicles, specifically trucks, the position of the license plate is not consistent. Lastly, for license plate reading, the variations are induced by non-uniform font styles, sizes, and partially occluded letters and numbers. Our proposed framework takes advantage of both data availability and performance evaluation of the backbone deep learning architectures. We gather a novel dataset, \emph{Diverse Vehicle and License Plates Dataset (DVLPD)}, consisting of 10k images belonging to six vehicle types. Each image is then manually annotated for vehicle type, license plate, and its characters and digits. For each of the three tasks, we evaluate You Only Look Once (YOLO)v2, YOLOv3, YOLOv4, and FasterRCNN. For real-time implementation on a Raspberry Pi, we evaluate the lighter versions of YOLO named Tiny YOLOv3 and Tiny YOLOv4. The best Mean Average Precision (mAP@0.5) of 98.8% for vehicle type recognition, 98.5% for license plate detection, and 98.3% for license plate reading is achieved by YOLOv4, while its lighter version, i.e., Tiny YOLOv4 obtained a mAP of 97.1%, 97.4%, and 93.7% on vehicle type recognition, license plate detection, and license plate reading, respectively. The dataset and the training codes are available at https://github.com/usama-x930/VT-LPR
CoinNet: Deep Ancient Roman Republican Coin Classification via Feature Fusion and Attention
Aug 26, 2019
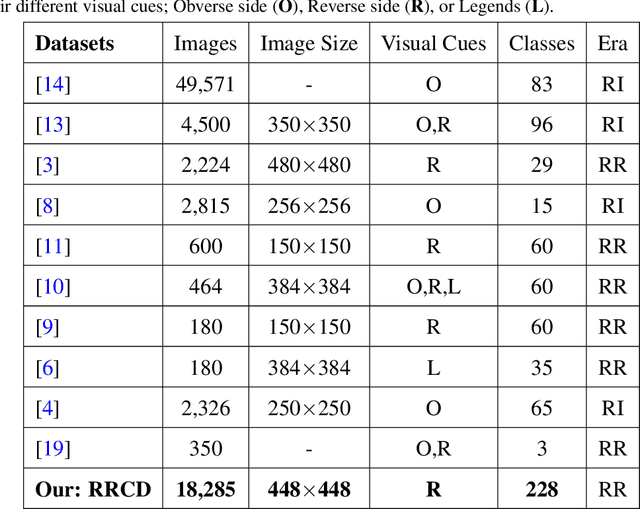

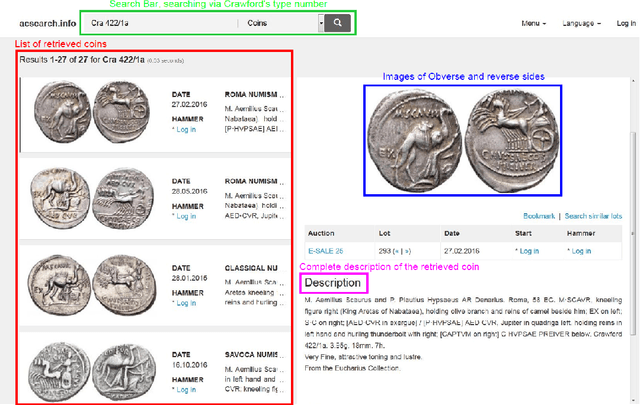
We perform classification of ancient Roman Republican coins via recognizing their reverse motifs where various objects, faces, scenes, animals, and buildings are minted along with legends. Most of these coins are eroded due to their age and varying degrees of preservation, thereby affecting their informative attributes for visual recognition. Changes in the positions of principal symbols on the reverse motifs also cause huge variations among the coin types. Lastly, in-plane orientations, uneven illumination, and a moderate background clutter further make the task of classification non-trivial and challenging. To this end, we present a novel network model, CoinNet, that employs compact bilinear pooling, residual groups, and feature attention layers. Furthermore, we gathered the largest and most diverse image dataset of the Roman Republican coins that contains more than 18,000 images belonging to 228 different reverse motifs. On this dataset, our model achieves a classification accuracy of more than \textbf{98\%} and outperforms the conventional bag-of-visual-words based approaches and more recent state-of-the-art deep learning methods. We also provide a detailed ablation study of our network and its generalization capability.
A Bag of Visual Words Approach for Symbols-Based Coarse-Grained Ancient Coin Classification
Apr 23, 2013

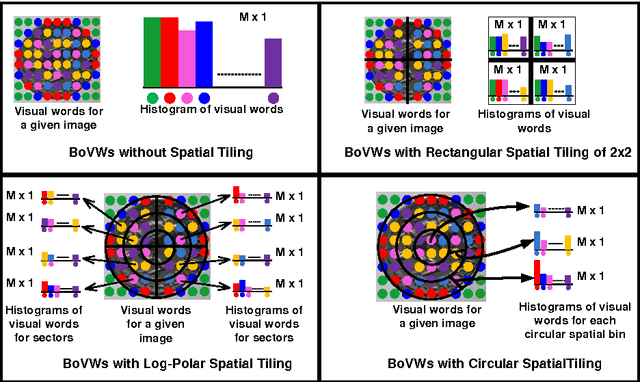

The field of Numismatics provides the names and descriptions of the symbols minted on the ancient coins. Classification of the ancient coins aims at assigning a given coin to its issuer. Various issuers used various symbols for their coins. We propose to use these symbols for a framework that will coarsely classify the ancient coins. Bag of visual words (BoVWs) is a well established visual recognition technique applied to various problems in computer vision like object and scene recognition. Improvements have been made by incorporating the spatial information to this technique. We apply the BoVWs technique to our problem and use three symbols for coarse-grained classification. We use rectangular tiling, log-polar tiling and circular tiling to incorporate spatial information to BoVWs. Experimental results show that the circular tiling proves superior to the rest of the methods for our problem.