 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of Riemannian distances between covariance operators and Gaussian processes
Aug 26, 2021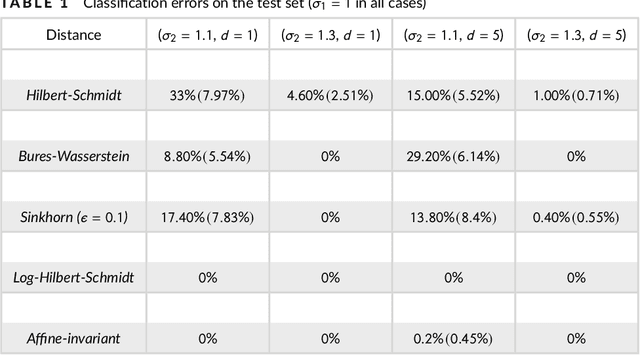
In this work we study two Riemannian distances between infinite-dimensional positive definite Hilbert-Schmidt operators, namely affine-invariant Riemannian and Log-Hilbert-Schmidt distances, in the context of covariance operators associated with functional stochastic processes, in particular Gaussian processes. Our first main results show that both distances converge in the Hilbert-Schmidt norm. Using concentration results for Hilbert space-valued random variables, we then show that both distances can be consistently and efficiently estimated from (i) sample covariance operators, (ii) finite, normalized covariance matrices, and (iii) finite samples generated by the given processes, all with dimension-independent convergence. Our theoretical analysis exploits extensively the methodology of reproducing kernel Hilbert space (RKHS) covariance and cross-covariance operators. The theoretical formulation is illustrated with numerical experiments on covariance operators of Gaussian processes.
Operator-Valued Bochner Theorem, Fourier Feature Maps for Operator-Valued Kernels, and Vector-Valued Learning
Aug 19, 2016

This paper presents a framework for computing random operator-valued feature maps for operator-valued positive definite kernels. This is a generalization of the random Fourier features for scalar-valued kernels to the operator-valued case. Our general setting is that of operator-valued kernels corresponding to RKHS of functions with values in a Hilbert space. We show that in general, for a given kernel, there are potentially infinitely many random feature maps, which can be bounded or unbounded. Most importantly, given a kernel, we present a general, closed form formula for computing a corresponding probability measure, which is required for the construction of the Fourier features, and which, unlike the scalar case, is not uniquely and automatically determined by the kernel. We also show that, under appropriate conditions, random bounded feature maps can always be computed. Furthermore, we show the uniform convergence, under the Hilbert-Schmidt norm, of the resulting approximate kernel to the exact kernel on any compact subset of Euclidean space. Our convergence requires differentiable kernels, an improvement over the twice-differentiability requirement in previous work in the scalar setting. We then show how operator-valued feature maps and their approximations can be employed in a general vector-valued learning framework. The mathematical formulation is illustrated by numerical examples on matrix-valued kernels.
A Unifying Framework in Vector-valued Reproducing Kernel Hilbert Spaces for Manifold Regularization and Co-Regularized Multi-view Learning
Mar 17, 2015

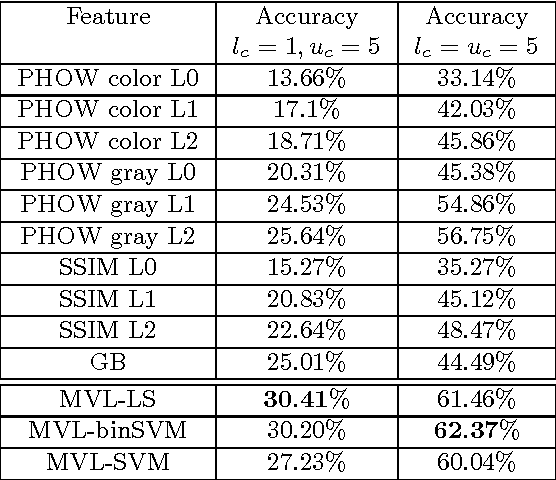

This paper presents a general vector-valued reproducing kernel Hilbert spaces (RKHS) framework for the problem of learning an unknown functional dependency between a structured input space and a structured output space. Our formulation encompasses both Vector-valued Manifold Regularization and Co-regularized Multi-view Learning, providing in particular a unifying framework linking these two important learning approaches. In the case of the least square loss function, we provide a closed form solution, which is obtained by solving a system of linear equations. In the case of Support Vector Machine (SVM) classification, our formulation generalizes in particular both the binary Laplacian SVM to the multi-class, multi-view settings and the multi-class Simplex Cone SVM to the semi-supervised, multi-view settings. The solution is obtained by solving a single quadratic optimization problem, as in standard SVM, via the Sequential Minimal Optimization (SMO) approach. Empirical results obtained on the task of object recognition, using several challenging datasets, demonstrate the competitiveness of our algorithms compared with other state-of-the-art methods.
* 72 pages
Scalable Matrix-valued Kernel Learning for High-dimensional Nonlinear Multivariate Regression and Granger Causality
Aug 09, 2014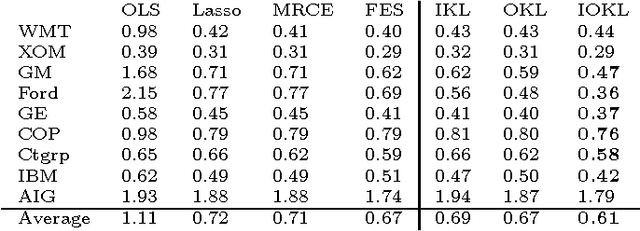

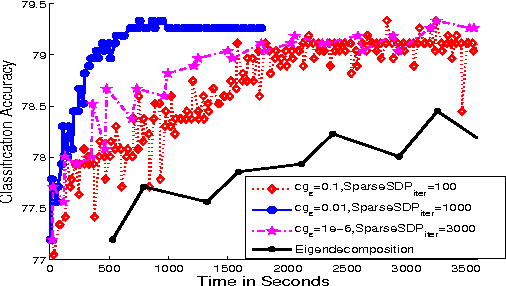
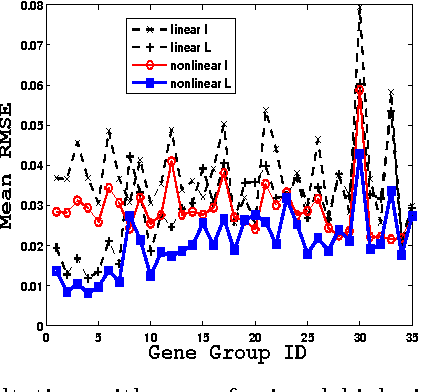
We propose a general matrix-valued multiple kernel learning framework for high-dimensional nonlinear multivariate regression problems. This framework allows a broad class of mixed norm regularizers, including those that induce sparsity, to be imposed on a dictionary of vector-valued Reproducing Kernel Hilbert Spaces. We develop a highly scalable and eigendecomposition-free algorithm that orchestrates two inexact solvers for simultaneously learning both the input and output components of separable matrix-valued kernels. As a key application enabled by our framework, we show how high-dimensional causal inference tasks can be naturally cast as sparse function estimation problems, leading to novel nonlinear extensions of a class of Graphical Granger Causality techniques. Our algorithmic developments and extensive empirical studies are complemented by theoretical analyses in terms of Rademacher generalization bounds.