 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Control by Iterative Inversion
Nov 03, 2022We formulate learning for control as an $\textit{inverse problem}$ -- inverting a dynamical system to give the actions which yield desired behavior. The key challenge in this formulation is a $\textit{distribution shift}$ -- the learning agent only observes the forward mapping (its actions' consequences) on trajectories that it can execute, yet must learn the inverse mapping for inputs-outputs that correspond to a different, desired behavior. We propose a general recipe for inverse problems with a distribution shift that we term $\textit{iterative inversion}$ -- learn the inverse mapping under the current input distribution (policy), then use it on the desired output samples to obtain new inputs, and repeat. As we show, iterative inversion can converge to the desired inverse mapping, but under rather strict conditions on the mapping itself. We next apply iterative inversion to learn control. Our input is a set of demonstrations of desired behavior, given as video embeddings of trajectories, and our method iteratively learns to imitate trajectories generated by the current policy, perturbed by random exploration noise. We find that constantly adding the demonstrated trajectory embeddings $\textit{as input}$ to the policy when generating trajectories to imitate, a-la iterative inversion, steers the learning towards the desired trajectory distribution. To the best of our knowledge, this is the first exploration of learning control from the viewpoint of inverse problems, and our main advantage is simplicity -- we do not require rewards, and only employ supervised learning, which easily scales to state-of-the-art trajectory embedding techniques and policy representations. With a VQ-VAE embedding, and a transformer-based policy, we demonstrate non-trivial continuous control on several tasks. We also report improved performance on imitating diverse behaviors compared to reward based methods.
Validate on Sim, Detect on Real -- Model Selection for Domain Randomization
Dec 01, 2021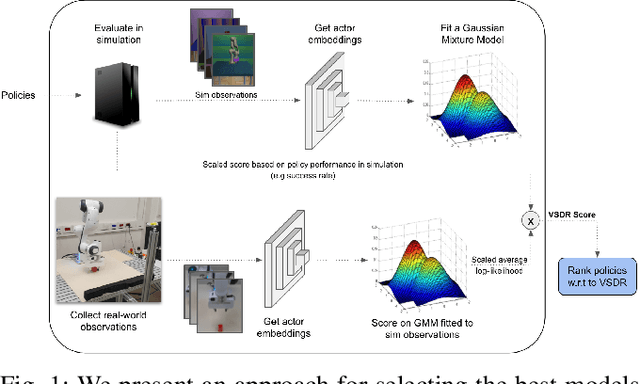

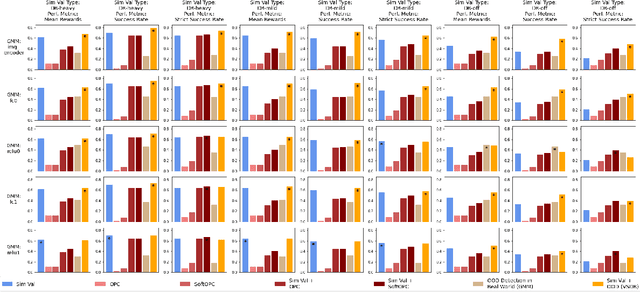

A practical approach to learning robot skills, often termed sim2real, is to train control policies in simulation and then deploy them on a real robot. Popular techniques to improve the sim2real transfer build on domain randomization (DR): Training the policy on a diverse set of randomly generated domains with the hope of better generalization to the real world. Due to the large number of hyper-parameters in both the policy learning and DR algorithms, one often ends up with a large number of trained models, where choosing the best model among them demands costly evaluation on the real robot. In this work we ask: Can we rank the policies without running them in the real world? Our main idea is that a predefined set of real world data can be used to evaluate all policies, using out-of-distribution detection (OOD) techniques. In a sense, this approach can be seen as a "unit test" to evaluate policies before any real world execution. However, we find that by itself, the OOD score can be inaccurate and very sensitive to the particular OOD method. Our main contribution is a simple-yet-effective policy score that combines OOD with an evaluation in simulation. We show that our score - VSDR - can significantly improve the accuracy of policy ranking without requiring additional real world data. We evaluate the effectiveness of VSDR on sim2real transfer in a robotic grasping task with image inputs. We extensively evaluate different DR parameters and OOD methods, and show that VSDR improves policy selection across the board. More importantly, our method achieves significantly better ranking, and uses significantly less data compared to baselines.
Efficient Self-Supervised Data Collection for Offline Robot Learning
May 10, 2021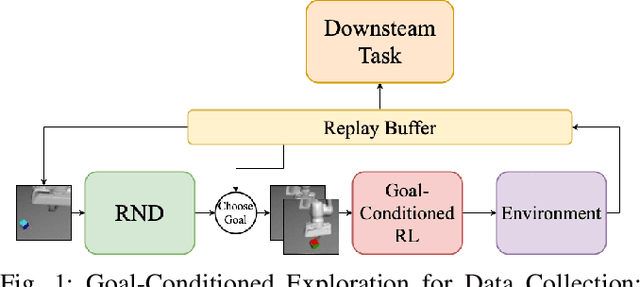



A practical approach to robot reinforcement learning is to first collect a large batch of real or simulated robot interaction data, using some data collection policy, and then learn from this data to perform various tasks, using offline learning algorithms. Previous work focused on manually designing the data collection policy, and on tasks where suitable policies can easily be designed, such as random picking policies for collecting data about object grasping. For more complex tasks, however, it may be difficult to find a data collection policy that explores the environment effectively, and produces data that is diverse enough for the downstream task. In this work, we propose that data collection policies should actively explore the environment to collect diverse data. In particular, we develop a simple-yet-effective goal-conditioned reinforcement-learning method that actively focuses data collection on novel observations, thereby collecting a diverse data-set. We evaluate our method on simulated robot manipulation tasks with visual inputs and show that the improved diversity of active data collection leads to significant improvements in the downstream learning tasks.
Neural Network Distiller: A Python Package For DNN Compression Research
Oct 27, 2019

This paper presents the philosophy, design and feature-set of Neural Network Distiller, an open-source Python package for DNN compression research. Distiller is a library of DNN compression algorithms implementations, with tools, tutorials and sample applications for various learning tasks. Its target users are both engineers and researchers, and the rich content is complemented by a design-for-extensibility to facilitate new research. Distiller is open-source and is available on Github at https://github.com/NervanaSystems/distiller.