 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidate on Sim, Detect on Real -- Model Selection for Domain Randomization
Paper and Code
Dec 01, 2021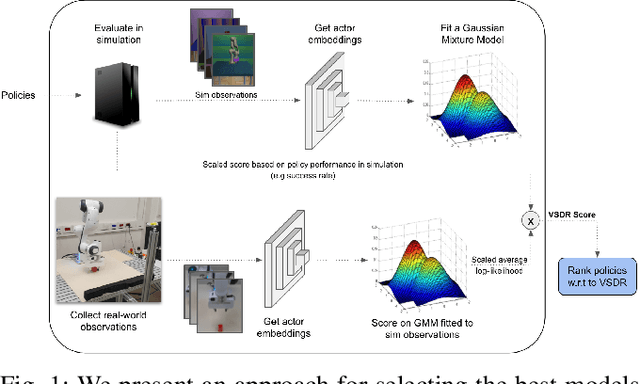

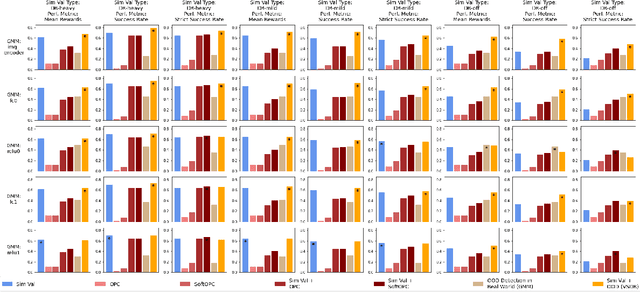

A practical approach to learning robot skills, often termed sim2real, is to train control policies in simulation and then deploy them on a real robot. Popular techniques to improve the sim2real transfer build on domain randomization (DR): Training the policy on a diverse set of randomly generated domains with the hope of better generalization to the real world. Due to the large number of hyper-parameters in both the policy learning and DR algorithms, one often ends up with a large number of trained models, where choosing the best model among them demands costly evaluation on the real robot. In this work we ask: Can we rank the policies without running them in the real world? Our main idea is that a predefined set of real world data can be used to evaluate all policies, using out-of-distribution detection (OOD) techniques. In a sense, this approach can be seen as a "unit test" to evaluate policies before any real world execution. However, we find that by itself, the OOD score can be inaccurate and very sensitive to the particular OOD method. Our main contribution is a simple-yet-effective policy score that combines OOD with an evaluation in simulation. We show that our score - VSDR - can significantly improve the accuracy of policy ranking without requiring additional real world data. We evaluate the effectiveness of VSDR on sim2real transfer in a robotic grasping task with image inputs. We extensively evaluate different DR parameters and OOD methods, and show that VSDR improves policy selection across the board. More importantly, our method achieves significantly better ranking, and uses significantly less data compared to baselines.