 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Co-Training for Semi-Supervised Image Segmentation
Mar 27, 2019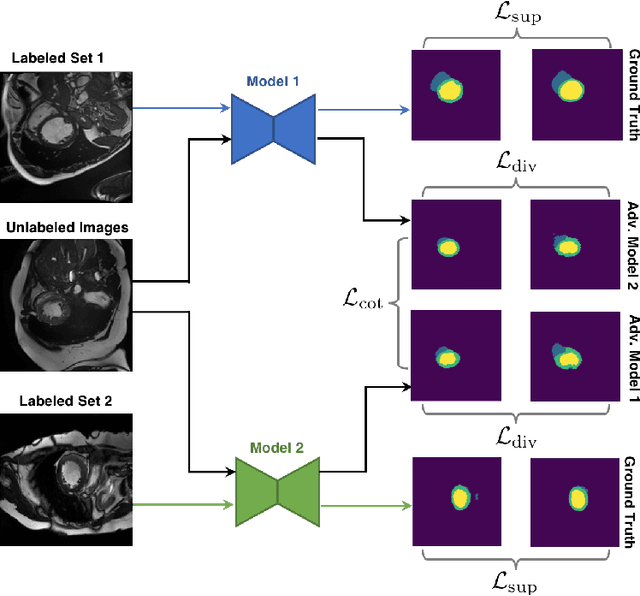
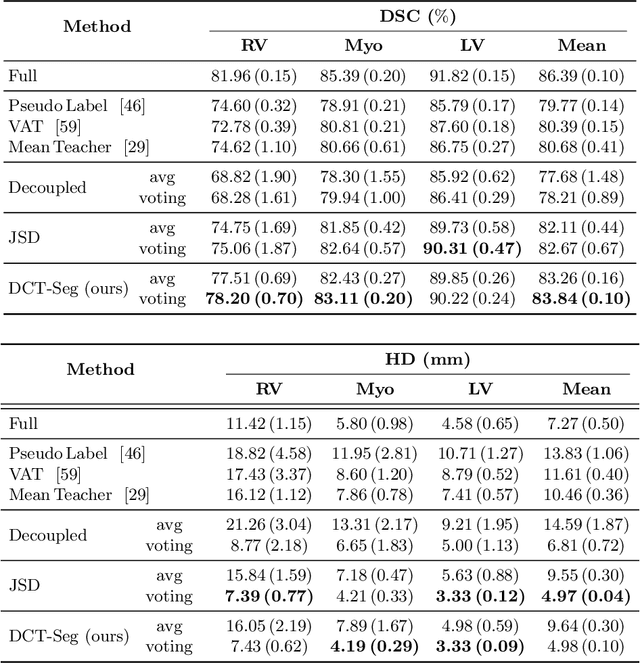

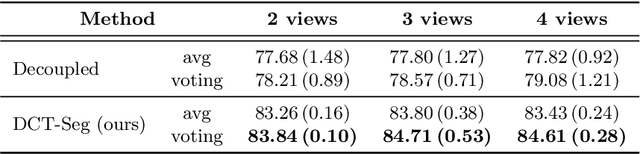
In this paper, we aim to improve the performance of semantic image segmentation in a semi-supervised setting in which training is effectuated with a reduced set of annotated images and additional non-annotated images. We present a method based on an ensemble of deep segmentation models. Each model is trained on a subset of the annotated data, and uses the non-annotated images to exchange information with the other models, similar to co-training. Even if each model learns on the same non-annotated images, diversity is preserved with the use of adversarial samples. Our results show that this ability to simultaneously train models, which exchange knowledge while preserving diversity, leads to state-of-the-art results on two challenging medical image datasets.