 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity detection over a heterogeneous population of non-aligned networks
Apr 04, 2019
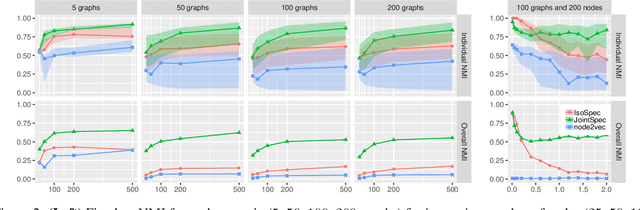
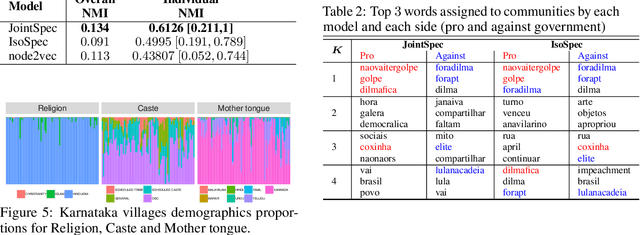
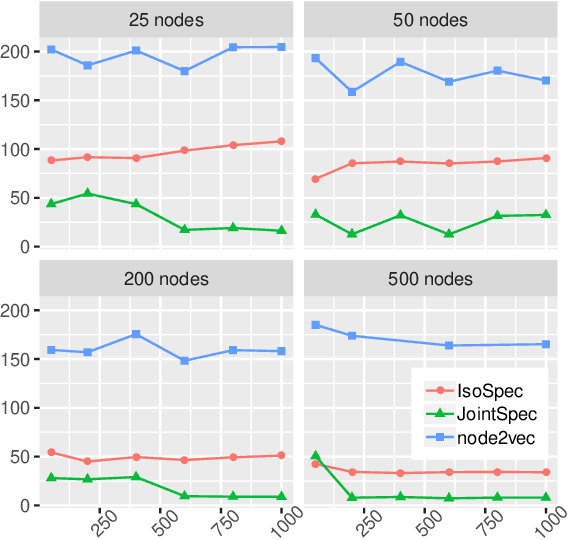
Clustering and community detection with multiple graphs have typically focused on aligned graphs, where there is a mapping between nodes across the graphs (e.g., multi-view, multi-layer, temporal graphs). However, there are numerous application areas with multiple graphs that are only partially aligned, or even unaligned. These graphs are often drawn from the same population, with communities of potentially different sizes that exhibit similar structure. In this paper, we develop a joint stochastic blockmodel (Joint SBM) to estimate shared communities across sets of heterogeneous non-aligned graphs. We derive an efficient spectral clustering approach to learn the parameters of the joint SBM. We evaluate the model on both synthetic and real-world datasets and show that the joint model is able to exploit cross-graph information to better estimate the communities compared to learning separate SBMs on each individual graph.
Multi-level hypothesis testing for populations of heterogeneous networks
Sep 07, 2018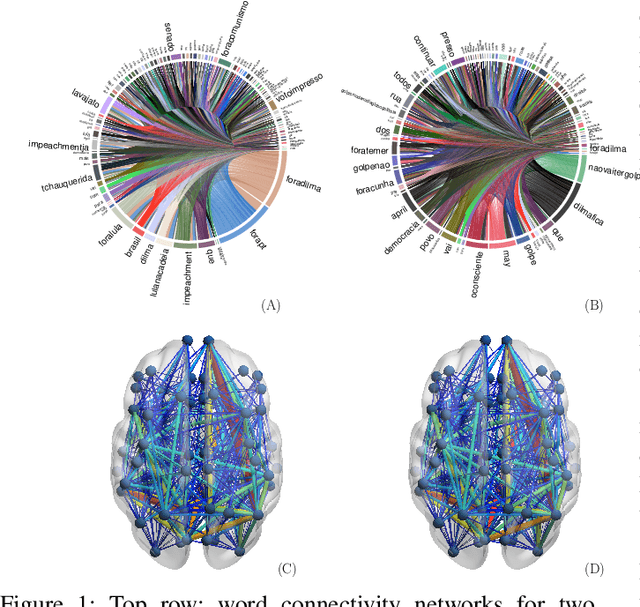
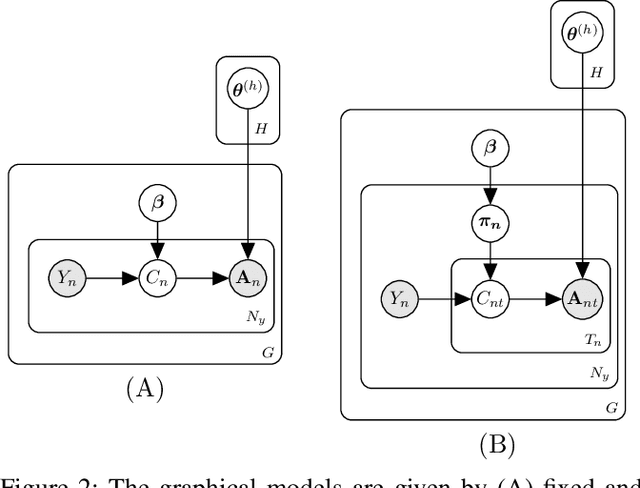
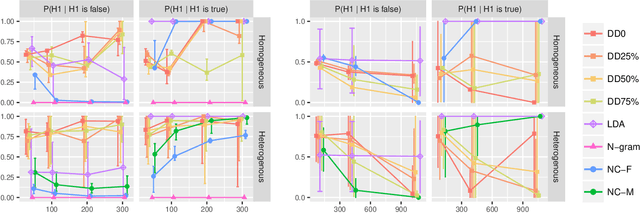
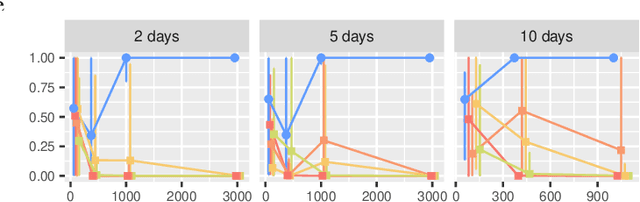
In this work, we consider hypothesis testing and anomaly detection on datasets where each observation is a weighted network. Examples of such data include brain connectivity networks from fMRI flow data, or word co-occurrence counts for populations of individuals. Current approaches to hypothesis testing for weighted networks typically requires thresholding the edge-weights, to transform the data to binary networks. This results in a loss of information, and outcomes are sensitivity to choice of threshold levels. Our work avoids this, and we consider weighted-graph observations in two situations, 1) where each graph belongs to one of two populations, and 2) where entities belong to one of two populations, with each entity possessing multiple graphs (indexed e.g. by time). Specifically, we propose a hierarchical Bayesian hypothesis testing framework that models each population with a mixture of latent space models for weighted networks, and then tests populations of networks for differences in distribution over components. Our framework is capable of population-level, entity-specific, as well as edge-specific hypothesis testing. We apply it to synthetic data and three real-world datasets: two social media datasets involving word co-occurrences from discussions on Twitter of the political unrest in Brazil, and on Instagram concerning Attention Deficit Hyperactivity Disorder (ADHD) and depression drugs, and one medical dataset involving fMRI brain-scans of human subjects. The results show that our proposed method has lower Type I error and higher statistical power compared to alternatives that need to threshold the edge weights. Moreover, they show our proposed method is better suited to deal with highly heterogeneous datasets.