 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Clique Forests
May 06, 2019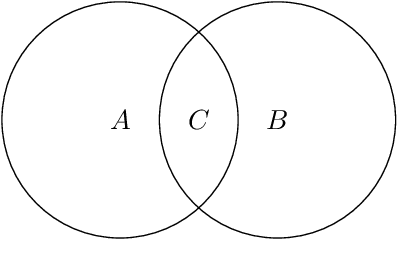
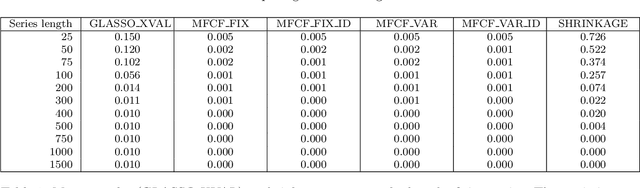

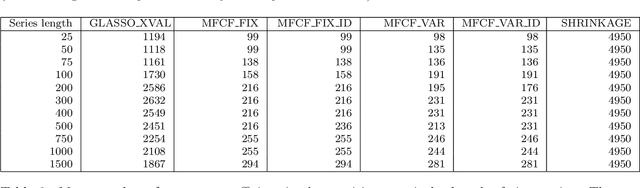
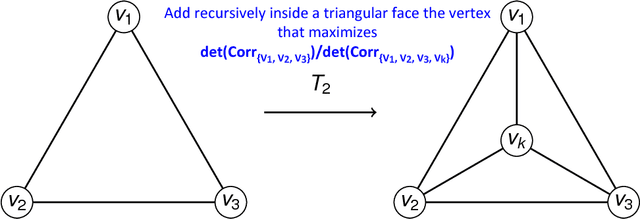
We propose a topological learning algorithm for the estimation of the conditional dependency structure of large sets of random variables from sparse and noisy data. The algorithm, named Maximally Filtered Clique Forest (MFCF), produces a clique forest and an associated Markov Random Field (MRF) by generalising Prim's minimum spanning tree algorithm. To the best of our knowledge, the MFCF presents three elements of novelty with respect to existing structure learning approaches. The first is the repeated application of a local topological move, the clique expansion, that preserves the decomposability of the underlying graph. Through this move the decomposability and calculation of scores is performed incrementally at the variable (rather than edge) level, and this provides better computational performance and an intuitive application of multivariate statistical tests. The second is the capability to accommodate a variety of score functions and, while this paper is focused on multivariate normal distributions, it can be directly generalised to different types of statistics. Finally, the third is the variable range of allowed clique sizes which is an adjustable topological constraint that acts as a topological penalizer providing a way to tackle sparsity at $l_0$ semi-norm level; this allows a clean decoupling of structure learning and parameter estimation. The MFCF produces a representation of the clique forest, together with a perfect ordering of the cliques and a perfect elimination ordering for the vertices. As an example we propose an application to covariance selection models and we show that the MCFC outperforms the Graphical Lasso for a number of classes of matrices.
Parsimonious modeling with Information Filtering Networks
Nov 23, 2016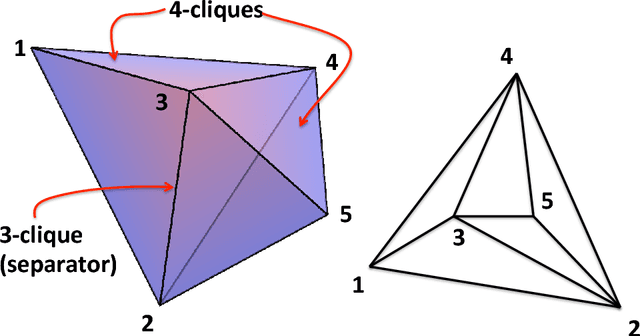

We introduce a methodology to construct parsimonious probabilistic models. This method makes use of Information Filtering Networks to produce a robust estimate of the global sparse inverse covariance from a simple sum of local inverse covariances computed on small sub-parts of the network. Being based on local and low-dimensional inversions, this method is computationally very efficient and statistically robust even for the estimation of inverse covariance of high-dimensional, noisy and short time-series. Applied to financial data our method results computationally more efficient than state-of-the-art methodologies such as Glasso producing, in a fraction of the computation time, models that can have equivalent or better performances but with a sparser inference structure. We also discuss performances with sparse factor models where we notice that relative performances decrease with the number of factors. The local nature of this approach allows us to perform computations in parallel and provides a tool for dynamical adaptation by partial updating when the properties of some variables change without the need of recomputing the whole model. This makes this approach particularly suitable to handle big datasets with large numbers of variables. Examples of practical application for forecasting, stress testing and risk allocation in financial systems are also provided.
* 17 pages, 10 figures, 3 tables