 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Representation for Robots through Human-Robot Interaction
Aug 01, 2013
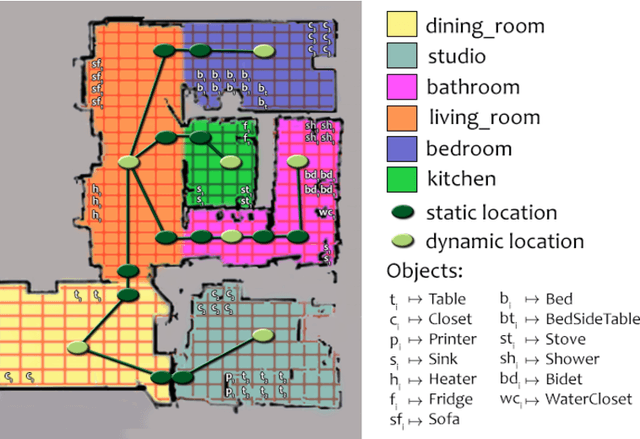
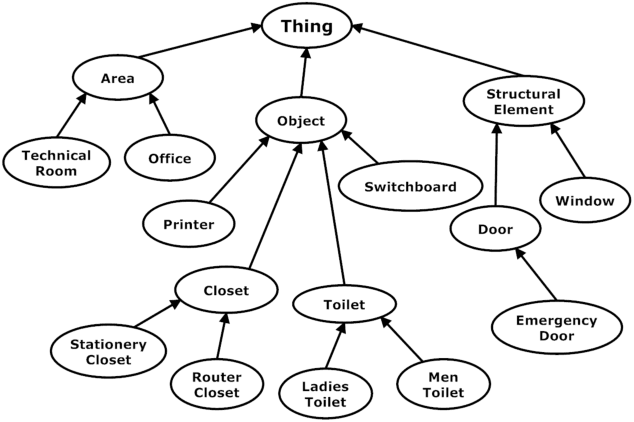
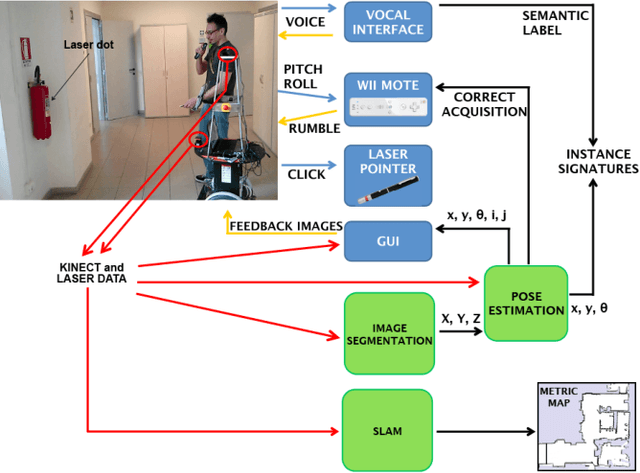
The representation of the knowledge needed by a robot to perform complex tasks is restricted by the limitations of perception. One possible way of overcoming this situation and designing "knowledgeable" robots is to rely on the interaction with the user. We propose a multi-modal interaction framework that allows to effectively acquire knowledge about the environment where the robot operates. In particular, in this paper we present a rich representation framework that can be automatically built from the metric map annotated with the indications provided by the user. Such a representation, allows then the robot to ground complex referential expressions for motion commands and to devise topological navigation plans to achieve the target locations.