 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelFSR: Self-Conditioned Face Super-Resolution in the Wild via Flow Field Degradation Network
Dec 20, 2021
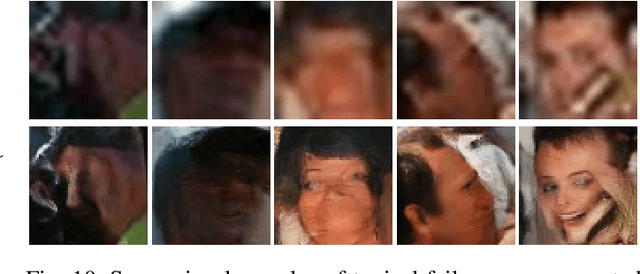
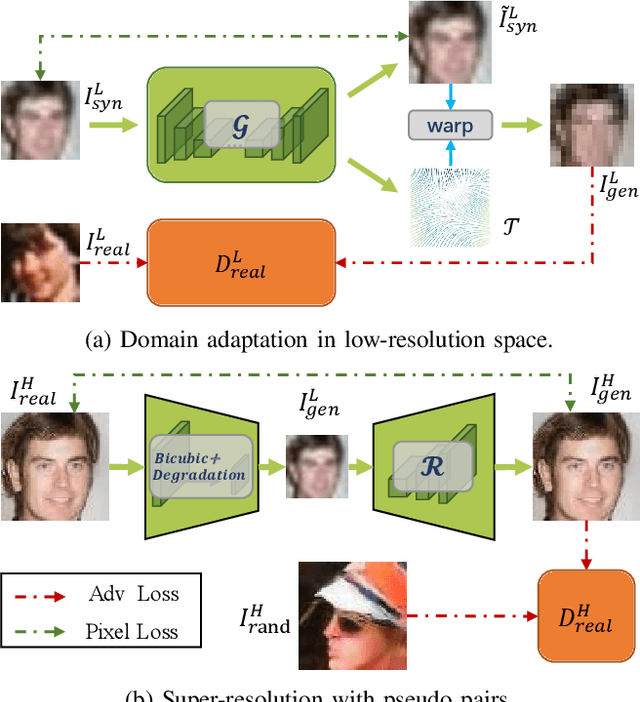
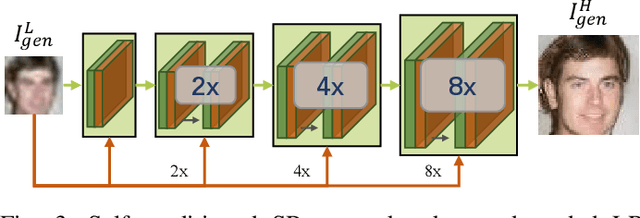
In spite of the success on benchmark datasets, most advanced face super-resolution models perform poorly in real scenarios since the remarkable domain gap between the real images and the synthesized training pairs. To tackle this problem, we propose a novel domain-adaptive degradation network for face super-resolution in the wild. This degradation network predicts a flow field along with an intermediate low resolution image. Then, the degraded counterpart is generated by warping the intermediate image. With the preference of capturing motion blur, such a model performs better at preserving identity consistency between the original images and the degraded. We further present the self-conditioned block for super-resolution network. This block takes the input image as a condition term to effectively utilize facial structure information, eliminating the reliance on explicit priors, e.g. facial landmarks or boundary. Our model achieves state-of-the-art performance on both CelebA and real-world face dataset. The former demonstrates the powerful generative ability of our proposed architecture while the latter shows great identity consistency and perceptual quality in real-world images.