 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimABSA: Building Multilingual and Multidomain Datasets for Dimensional Aspect-Based Sentiment Analysis
Jan 30, 2026Aspect-Based Sentiment Analysis (ABSA) focuses on extracting sentiment at a fine-grained aspect level and has been widely applied across real-world domains. However, existing ABSA research relies on coarse-grained categorical labels (e.g., positive, negative), which limits its ability to capture nuanced affective states. To address this limitation, we adopt a dimensional approach that represents sentiment with continuous valence-arousal (VA) scores, enabling fine-grained analysis at both the aspect and sentiment levels. To this end, we introduce DimABSA, the first multilingual, dimensional ABSA resource annotated with both traditional ABSA elements (aspect terms, aspect categories, and opinion terms) and newly introduced VA scores. This resource contains 76,958 aspect instances across 42,590 sentences, spanning six languages and four domains. We further introduce three subtasks that combine VA scores with different ABSA elements, providing a bridge from traditional ABSA to dimensional ABSA. Given that these subtasks involve both categorical and continuous outputs, we propose a new unified metric, continuous F1 (cF1), which incorporates VA prediction error into standard F1. We provide a comprehensive benchmark using both prompted and fine-tuned large language models across all subtasks. Our results show that DimABSA is a challenging benchmark and provides a foundation for advancing multilingual dimensional ABSA.
SAPO: Self-Adaptive Process Optimization Makes Small Reasoners Stronger
Jan 28, 2026Existing self-evolution methods overlook the influence of fine-grained reasoning steps, which leads to the reasoner-verifier gap. The computational inefficiency of Monte Carlo (MC) process supervision further exacerbates the difficulty in mitigating the gap. Motivated by the Error-Related Negativity (ERN), which the reasoner can localize error following incorrect decisions, guiding rapid adjustments, we propose a Self-Adaptive Process Optimization (SAPO) method for self-improvement in Small Language Models (SLMs). SAPO adaptively and efficiently introduces process supervision signals by actively minimizing the reasoner-verifier gap rather than relying on inefficient MC estimations. Extensive experiments demonstrate that the proposed method outperforms most existing self-evolution methods on two challenging task types: mathematics and code. Additionally, to further investigate SAPO's impact on verifier performance, this work introduces two new benchmarks for process reward models in both mathematical and coding tasks.
Instruction Tuning with Retrieval-based Examples Ranking for Aspect-based Sentiment Analysis
May 29, 2024



Aspect-based sentiment analysis (ABSA) identifies sentiment information related to specific aspects and provides deeper market insights to businesses and organizations. With the emergence of large language models (LMs), recent studies have proposed using fixed examples for instruction tuning to reformulate ABSA as a generation task. However, the performance is sensitive to the selection of in-context examples; several retrieval methods are based on surface similarity and are independent of the LM generative objective. This study proposes an instruction learning method with retrieval-based example ranking for ABSA tasks. For each target sample, an LM was applied as a scorer to estimate the likelihood of the output given the input and a candidate example as the prompt, and training examples were labeled as positive or negative by ranking the scores. An alternating training schema is proposed to train both the retriever and LM. Instructional prompts can be constructed using high-quality examples. The LM is used for both scoring and inference, improving the generation efficiency without incurring additional computational costs or training difficulties. Extensive experiments on three ABSA subtasks verified the effectiveness of the proposed method, demonstrating its superiority over various strong baseline models. Code and data are released at https://github.com/zgMin/IT-RER-ABSA.
Enhancing Semantics in Multimodal Chain of Thought via Soft Negative Sampling
May 16, 2024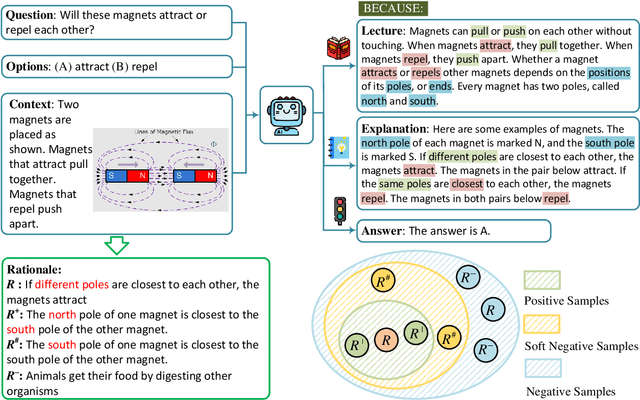

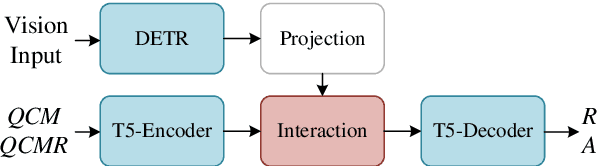

Chain of thought (CoT) has proven useful for problems requiring complex reasoning. Many of these problems are both textual and multimodal. Given the inputs in different modalities, a model generates a rationale and then uses it to answer a question. Because of the hallucination issue, the generated soft negative rationales with high textual quality but illogical semantics do not always help improve answer accuracy. This study proposes a rationale generation method using soft negative sampling (SNSE-CoT) to mitigate hallucinations in multimodal CoT. Five methods were applied to generate soft negative samples that shared highly similar text but had different semantics from the original. Bidirectional margin loss (BML) was applied to introduce them into the traditional contrastive learning framework that involves only positive and negative samples. Extensive experiments on the ScienceQA dataset demonstrated the effectiveness of the proposed method. Code and data are released at https://github.com/zgMin/SNSE-CoT.