 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does the LLM Stop Computing: An Empirical Study of User-Reported Failures in Open-Source LLMs
Jan 20, 2026The democratization of open-source Large Language Models (LLMs) allows users to fine-tune and deploy models on local infrastructure but exposes them to a First Mile deployment landscape. Unlike black-box API consumption, the reliability of user-managed orchestration remains a critical blind spot. To bridge this gap, we conduct the first large-scale empirical study of 705 real-world failures from the open-source DeepSeek, Llama, and Qwen ecosystems. Our analysis reveals a paradigm shift: white-box orchestration relocates the reliability bottleneck from model algorithmic defects to the systemic fragility of the deployment stack. We identify three key phenomena: (1) Diagnostic Divergence: runtime crashes distinctively signal infrastructure friction, whereas incorrect functionality serves as a signature for internal tokenizer defects. (2) Systemic Homogeneity: Root causes converge across divergent series, confirming reliability barriers are inherent to the shared ecosystem rather than specific architectures. (3) Lifecycle Escalation: Barriers escalate from intrinsic configuration struggles during fine-tuning to compounded environmental incompatibilities during inference. Supported by our publicly available dataset, these insights provide actionable guidance for enhancing the reliability of the LLM landscape.
A Survey on Failure Analysis and Fault Injection in AI Systems
Jun 28, 2024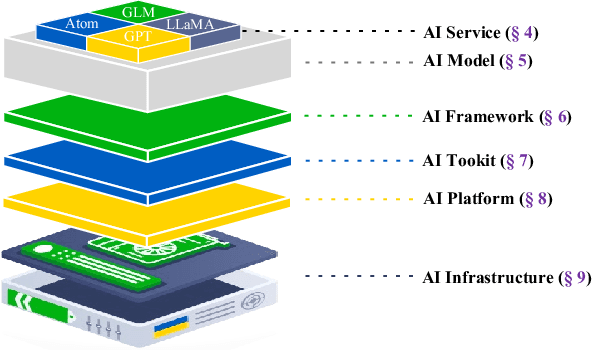
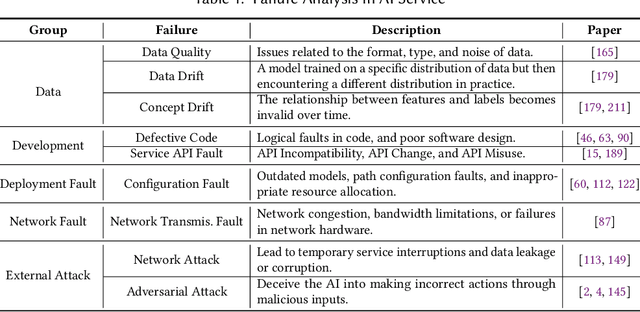
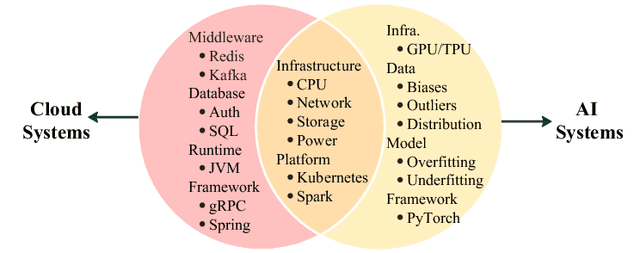
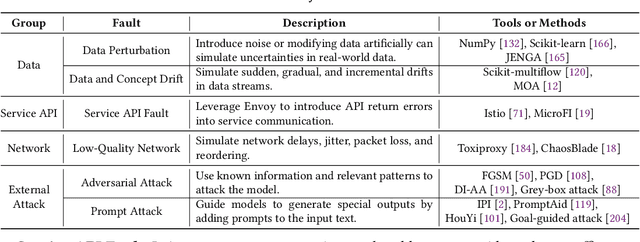
The rapid advancement of Artificial Intelligence (AI) has led to its integration into various areas, especially with Large Language Models (LLMs) significantly enhancing capabilities in Artificial Intelligence Generated Content (AIGC). However, the complexity of AI systems has also exposed their vulnerabilities, necessitating robust methods for failure analysis (FA) and fault injection (FI) to ensure resilience and reliability. Despite the importance of these techniques, there lacks a comprehensive review of FA and FI methodologies in AI systems. This study fills this gap by presenting a detailed survey of existing FA and FI approaches across six layers of AI systems. We systematically analyze 160 papers and repositories to answer three research questions including (1) what are the prevalent failures in AI systems, (2) what types of faults can current FI tools simulate, (3) what gaps exist between the simulated faults and real-world failures. Our findings reveal a taxonomy of AI system failures, assess the capabilities of existing FI tools, and highlight discrepancies between real-world and simulated failures. Moreover, this survey contributes to the field by providing a framework for fault diagnosis, evaluating the state-of-the-art in FI, and identifying areas for improvement in FI techniques to enhance the resilience of AI systems.