 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Adaptive Clustering Scheme for Client Selections in Communication-Efficient Federated Learning
Apr 11, 2025Federated learning is a novel decentralized learning architecture. During the training process, the client and server must continuously upload and receive model parameters, which consumes a lot of network transmission resources. Some methods use clustering to find more representative customers, select only a part of them for training, and at the same time ensure the accuracy of training. However, in federated learning, it is not trivial to know what the number of clusters can bring the best training result. Therefore, we propose to dynamically adjust the number of clusters to find the most ideal grouping results. It may reduce the number of users participating in the training to achieve the effect of reducing communication costs without affecting the model performance. We verify its experimental results on the non-IID handwritten digit recognition dataset and reduce the cost of communication and transmission by almost 50% compared with traditional federated learning without affecting the accuracy of the model.
Real-Time Compressed Sensing for Joint Hyperspectral Image Transmission and Restoration for CubeSat
Apr 24, 2024



This paper addresses the challenges associated with hyperspectral image (HSI) reconstruction from miniaturized satellites, which often suffer from stripe effects and are computationally resource-limited. We propose a Real-Time Compressed Sensing (RTCS) network designed to be lightweight and require only relatively few training samples for efficient and robust HSI reconstruction in the presence of the stripe effect and under noisy transmission conditions. The RTCS network features a simplified architecture that reduces the required training samples and allows for easy implementation on integer-8-based encoders, facilitating rapid compressed sensing for stripe-like HSI, which exactly matches the moderate design of miniaturized satellites on push broom scanning mechanism. This contrasts optimization-based models that demand high-precision floating-point operations, making them difficult to deploy on edge devices. Our encoder employs an integer-8-compatible linear projection for stripe-like HSI data transmission, ensuring real-time compressed sensing. Furthermore, based on the novel two-streamed architecture, an efficient HSI restoration decoder is proposed for the receiver side, allowing for edge-device reconstruction without needing a sophisticated central server. This is particularly crucial as an increasing number of miniaturized satellites necessitates significant computing resources on the ground station. Extensive experiments validate the superior performance of our approach, offering new and vital capabilities for existing miniaturized satellite systems.
Spatiotemporal Feature Learning Based on Two-Step LSTM and Transformer for CT Scans
Jul 08, 2022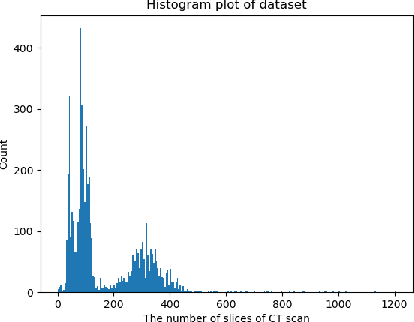
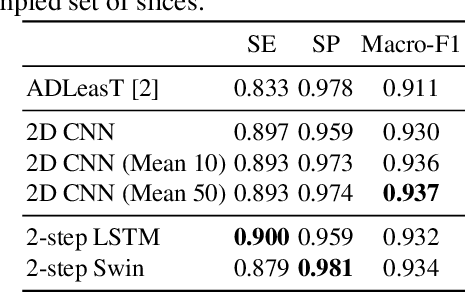
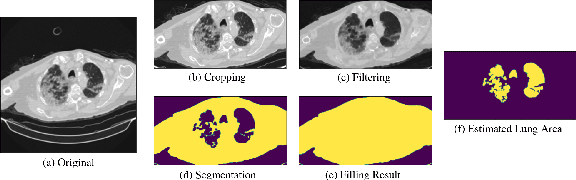
Computed tomography (CT) imaging could be very practical for diagnosing various diseases. However, the nature of the CT images is even more diverse since the resolution and number of the slices of a CT scan are determined by the machine and its settings. Conventional deep learning models are hard to tickle such diverse data since the essential requirement of the deep neural network is the consistent shape of the input data. In this paper, we propose a novel, effective, two-step-wise approach to tickle this issue for COVID-19 symptom classification thoroughly. First, the semantic feature embedding of each slice for a CT scan is extracted by conventional backbone networks. Then, we proposed a long short-term memory (LSTM) and Transformer-based sub-network to deal with temporal feature learning, leading to spatiotemporal feature representation learning. In this fashion, the proposed two-step LSTM model could prevent overfitting, as well as increase performance. Comprehensive experiments reveal that the proposed two-step method not only shows excellent performance but also could be compensated for each other. More specifically, the two-step LSTM model has a lower false-negative rate, while the 2-step Swin model has a lower false-positive rate. In summary, it is suggested that the model ensemble could be adopted for more stable and promising performance in real-world applications.
Visual Transformer with Statistical Test for COVID-19 Classification
Jul 12, 2021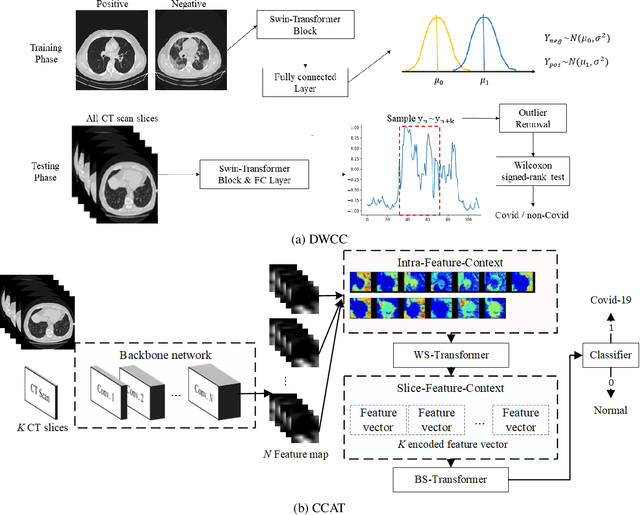
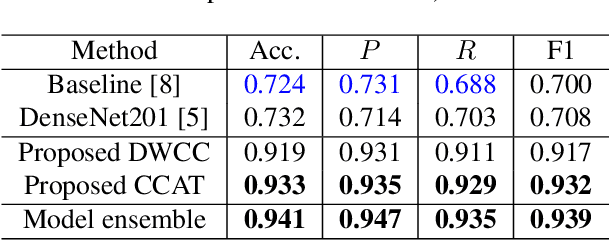
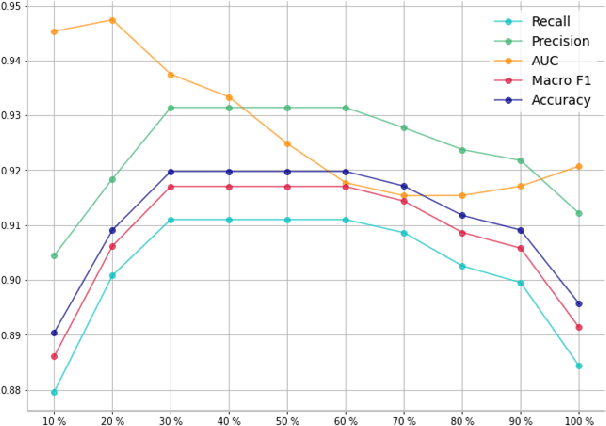
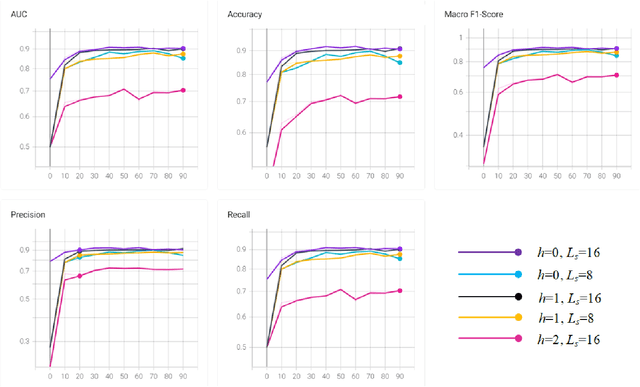
With the massive damage in the world caused by Coronavirus Disease 2019 SARS-CoV-2 (COVID-19), many related research topics have been proposed in the past two years. The Chest Computed Tomography (CT) scans are the most valuable materials to diagnose the COVID-19 symptoms. However, most schemes for COVID-19 classification of Chest CT scan is based on a single-slice level, implying that the most critical CT slice should be selected from the original CT scan volume manually. We simultaneously propose 2-D and 3-D models to predict the COVID-19 of CT scan to tickle this issue. In our 2-D model, we introduce the Deep Wilcoxon signed-rank test (DWCC) to determine the importance of each slice of a CT scan to overcome the issue mentioned previously. Furthermore, a Convolutional CT scan-Aware Transformer (CCAT) is proposed to discover the context of the slices fully. The frame-level feature is extracted from each CT slice based on any backbone network and followed by feeding the features to our within-slice-Transformer (WST) to discover the context information in the pixel dimension. The proposed Between-Slice-Transformer (BST) is used to aggregate the extracted spatial-context features of every CT slice. A simple classifier is then used to judge whether the Spatio-temporal features are COVID-19 or non-COVID-19. The extensive experiments demonstrated that the proposed CCAT and DWCC significantly outperform the state-of-the-art methods.