 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Versatile Time-Series Analysis with Tiny Transformers on Embedded FPGAs
May 23, 2025Transformer-based models have shown strong performance across diverse time-series tasks, but their deployment on resource-constrained devices remains challenging due to high memory and computational demand. While prior work targeting Microcontroller Units (MCUs) has explored hardware-specific optimizations, such approaches are often task-specific and limited to 8-bit fixed-point precision. Field-Programmable Gate Arrays (FPGAs) offer greater flexibility, enabling fine-grained control over data precision and architecture. However, existing FPGA-based deployments of Transformers for time-series analysis typically focus on high-density platforms with manual configuration. This paper presents a unified and fully automated deployment framework for Tiny Transformers on embedded FPGAs. Our framework supports a compact encoder-only Transformer architecture across three representative time-series tasks (forecasting, classification, and anomaly detection). It combines quantization-aware training (down to 4 bits), hardware-aware hyperparameter search using Optuna, and automatic VHDL generation for seamless deployment. We evaluate our framework on six public datasets across two embedded FPGA platforms. Results show that our framework produces integer-only, task-specific Transformer accelerators achieving as low as 0.033 mJ per inference with millisecond latency on AMD Spartan-7, while also providing insights into deployment feasibility on Lattice iCE40. All source code will be released in the GitHub repository (https://github.com/Edwina1030/TinyTransformer4TS).
Resource-aware Mixed-precision Quantization for Enhancing Deployability of Transformers for Time-series Forecasting on Embedded FPGAs
Oct 04, 2024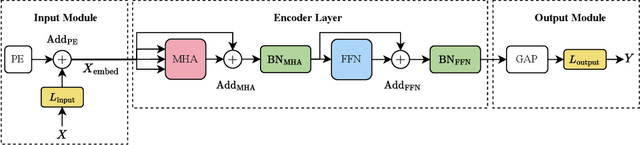

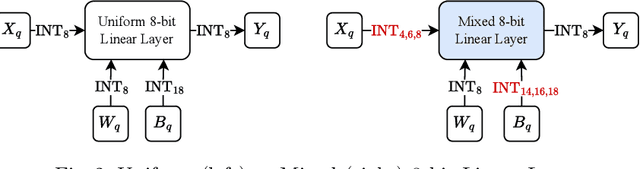

This study addresses the deployment challenges of integer-only quantized Transformers on resource-constrained embedded FPGAs (Xilinx Spartan-7 XC7S15). We enhanced the flexibility of our VHDL template by introducing a selectable resource type for storing intermediate results across model layers, thereby breaking the deployment bottleneck by utilizing BRAM efficiently. Moreover, we developed a resource-aware mixed-precision quantization approach that enables researchers to explore hardware-level quantization strategies without requiring extensive expertise in Neural Architecture Search. This method provides accurate resource utilization estimates with a precision discrepancy as low as 3%, compared to actual deployment metrics. Compared to previous work, our approach has successfully facilitated the deployment of model configurations utilizing mixed-precision quantization, thus overcoming the limitations inherent in five previously non-deployable configurations with uniform quantization bitwidths. Consequently, this research enhances the applicability of Transformers in embedded systems, facilitating a broader range of Transformer-powered applications on edge devices.
On-device AI: Quantization-aware Training of Transformers in Time-Series
Aug 29, 2024Artificial Intelligence (AI) models for time-series in pervasive computing keep getting larger and more complicated. The Transformer model is by far the most compelling of these AI models. However, it is difficult to obtain the desired performance when deploying such a massive model on a sensor device with limited resources. My research focuses on optimizing the Transformer model for time-series forecasting tasks. The optimized model will be deployed as hardware accelerators on embedded Field Programmable Gate Arrays (FPGAs). I will investigate the impact of applying Quantization-aware Training to the Transformer model to reduce its size and runtime memory footprint while maximizing the advantages of FPGAs.
Towards Auto-Building of Embedded FPGA-based Soft Sensors for Wastewater Flow Estimation
Jul 06, 2024Executing flow estimation using Deep Learning (DL)-based soft sensors on resource-limited IoT devices has demonstrated promise in terms of reliability and energy efficiency. However, its application in the field of wastewater flow estimation remains underexplored due to: (1) a lack of available datasets, (2) inconvenient toolchains for on-device AI model development and deployment, and (3) hardware platforms designed for general DL purposes rather than being optimized for energy-efficient soft sensor applications. This study addresses these gaps by proposing an automated, end-to-end solution for wastewater flow estimation using a prototype IoT device.
FlowPrecision: Advancing FPGA-Based Real-Time Fluid Flow Estimation with Linear Quantization
Mar 04, 2024In industrial and environmental monitoring, achieving real-time and precise fluid flow measurement remains a critical challenge. This study applies linear quantization in FPGA-based soft sensors for fluid flow estimation, significantly enhancing Neural Network model precision by overcoming the limitations of traditional fixed-point quantization. Our approach achieves up to a 10.10% reduction in Mean Squared Error and a notable 9.39% improvement in inference speed through targeted hardware optimizations. Validated across multiple data sets, our findings demonstrate that the optimized FPGA-based quantized models can provide efficient, accurate real-time inference, offering a viable alternative to cloud-based processing in pervasive autonomous systems.
On-Device Soft Sensors: Real-Time Fluid Flow Estimation from Level Sensor Data
Nov 25, 2023Soft sensors are crucial in bridging autonomous systems' physical and digital realms, enhancing sensor fusion and perception. Instead of deploying soft sensors on the Cloud, this study shift towards employing on-device soft sensors, promising heightened efficiency and bolstering data security. Our approach substantially improves energy efficiency by deploying Artificial Intelligence (AI) directly on devices within a wireless sensor network. Furthermore, the synergistic integration of the Microcontroller Unit and Field-Programmable Gate Array (FPGA) leverages the rapid AI inference capabilities of the latter. Empirical evidence from our real-world use case demonstrates that FPGA-based soft sensors achieve inference times ranging remarkably from 1.04 to 12.04 microseconds. These compelling results highlight the considerable potential of our innovative approach for executing real-time inference tasks efficiently, thereby presenting a feasible alternative that effectively addresses the latency challenges intrinsic to Cloud-based deployments.
A Study of Quantisation-aware Training on Time Series Transformer Models for Resource-constrained FPGAs
Oct 04, 2023This study explores the quantisation-aware training (QAT) on time series Transformer models. We propose a novel adaptive quantisation scheme that dynamically selects between symmetric and asymmetric schemes during the QAT phase. Our approach demonstrates that matching the quantisation scheme to the real data distribution can reduce computational overhead while maintaining acceptable precision. Moreover, our approach is robust when applied to real-world data and mixed-precision quantisation, where most objects are quantised to 4 bits. Our findings inform model quantisation and deployment decisions while providing a foundation for advancing quantisation techniques.