 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocality and low-dimensions in the prediction of natural experience from fMRI
Jan 12, 2008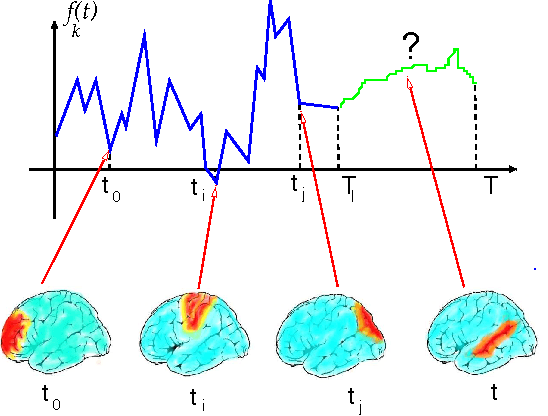
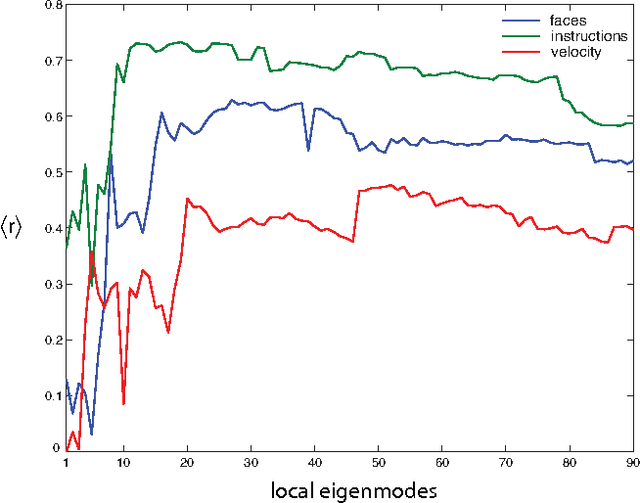
Functional Magnetic Resonance Imaging (fMRI) provides dynamical access into the complex functioning of the human brain, detailing the hemodynamic activity of thousands of voxels during hundreds of sequential time points. One approach towards illuminating the connection between fMRI and cognitive function is through decoding; how do the time series of voxel activities combine to provide information about internal and external experience? Here we seek models of fMRI decoding which are balanced between the simplicity of their interpretation and the effectiveness of their prediction. We use signals from a subject immersed in virtual reality to compare global and local methods of prediction applying both linear and nonlinear techniques of dimensionality reduction. We find that the prediction of complex stimuli is remarkably low-dimensional, saturating with less than 100 features. In particular, we build effective models based on the decorrelated components of cognitive activity in the classically-defined Brodmann areas. For some of the stimuli, the top predictive areas were surprisingly transparent, including Wernicke's area for verbal instructions, visual cortex for facial and body features, and visual-temporal regions for velocity. Direct sensory experience resulted in the most robust predictions, with the highest correlation ($c \sim 0.8$) between the predicted and experienced time series of verbal instructions. Techniques based on non-linear dimensionality reduction (Laplacian eigenmaps) performed similarly. The interpretability and relative simplicity of our approach provides a conceptual basis upon which to build more sophisticated techniques for fMRI decoding and offers a window into cognitive function during dynamic, natural experience.
Toward a statistical mechanics of four letter words
Dec 31, 2007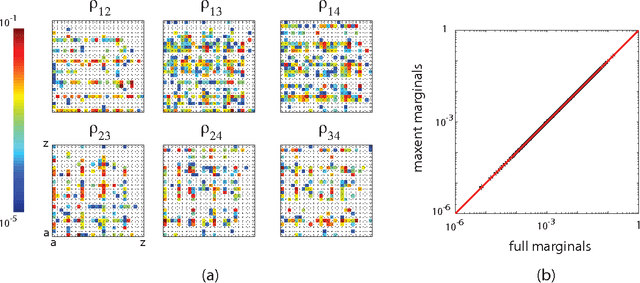
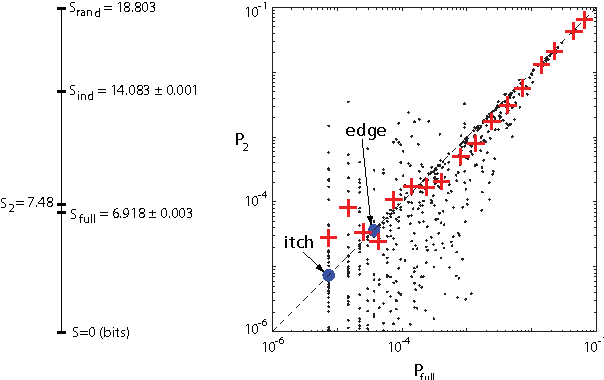
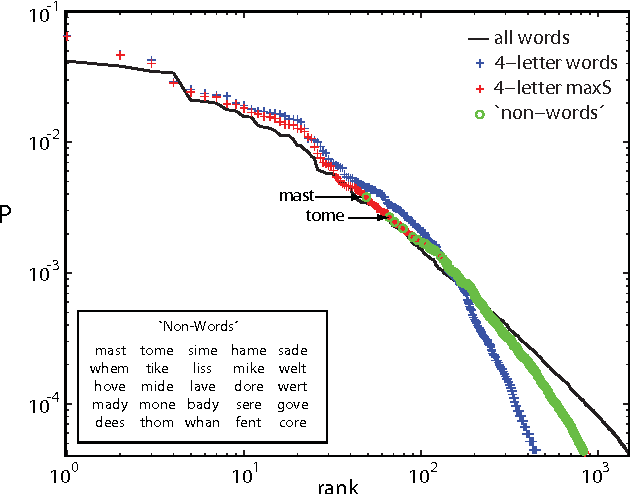
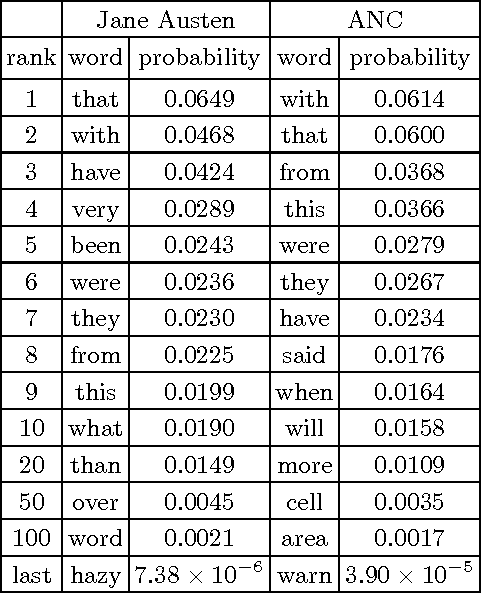
We consider words as a network of interacting letters, and approximate the probability distribution of states taken on by this network. Despite the intuition that the rules of English spelling are highly combinatorial (and arbitrary), we find that maximum entropy models consistent with pairwise correlations among letters provide a surprisingly good approximation to the full statistics of four letter words, capturing ~92% of the multi-information among letters and even "discovering" real words that were not represented in the data from which the pairwise correlations were estimated. The maximum entropy model defines an energy landscape on the space of possible words, and local minima in this landscape account for nearly two-thirds of words used in written English.