 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust multi-task boosting using clustering and local ensembling
Feb 15, 2026Multi-Task Learning (MTL) aims to boost predictive performance by sharing information across related tasks, yet conventional methods often suffer from negative transfer when unrelated or noisy tasks are forced to share representations. We propose Robust Multi-Task Boosting using Clustering and Local Ensembling (RMB-CLE), a principled MTL framework that integrates error-based task clustering with local ensembling. Unlike prior work that assumes fixed clusters or hand-crafted similarity metrics, RMB-CLE derives inter-task similarity directly from cross-task errors, which admit a risk decomposition into functional mismatch and irreducible noise, providing a theoretically grounded mechanism to prevent negative transfer. Tasks are grouped adaptively via agglomerative clustering, and within each cluster, a local ensemble enables robust knowledge sharing while preserving task-specific patterns. Experiments show that RMB-CLE recovers ground-truth clusters in synthetic data and consistently outperforms multi-task, single-task, and pooling-based ensemble methods across diverse real-world and synthetic benchmarks. These results demonstrate that RMB-CLE is not merely a combination of clustering and boosting but a general and scalable framework that establishes a new basis for robust multi-task learning.
Robust-Multi-Task Gradient Boosting
Jul 15, 2025Multi-task learning (MTL) has shown effectiveness in exploiting shared information across tasks to improve generalization. MTL assumes tasks share similarities that can improve performance. In addition, boosting algorithms have demonstrated exceptional performance across diverse learning problems, primarily due to their ability to focus on hard-to-learn instances and iteratively reduce residual errors. This makes them a promising approach for learning multi-task problems. However, real-world MTL scenarios often involve tasks that are not well-aligned (known as outlier or adversarial tasks), which do not share beneficial similarities with others and can, in fact, deteriorate the performance of the overall model. To overcome this challenge, we propose Robust-Multi-Task Gradient Boosting (R-MTGB), a novel boosting framework that explicitly models and adapts to task heterogeneity during training. R-MTGB structures the learning process into three sequential blocks: (1) learning shared patterns, (2) partitioning tasks into outliers and non-outliers with regularized parameters, and (3) fine-tuning task-specific predictors. This architecture enables R-MTGB to automatically detect and penalize outlier tasks while promoting effective knowledge transfer among related tasks. Our method integrates these mechanisms seamlessly within gradient boosting, allowing robust handling of noisy or adversarial tasks without sacrificing accuracy. Extensive experiments on both synthetic benchmarks and real-world datasets demonstrate that our approach successfully isolates outliers, transfers knowledge, and consistently reduces prediction errors for each task individually, and achieves overall performance gains across all tasks. These results highlight robustness, adaptability, and reliable convergence of R-MTGB in challenging MTL environments.
A Gradient Boosting Approach for Training Convolutional and Deep Neural Networks
Feb 23, 2023
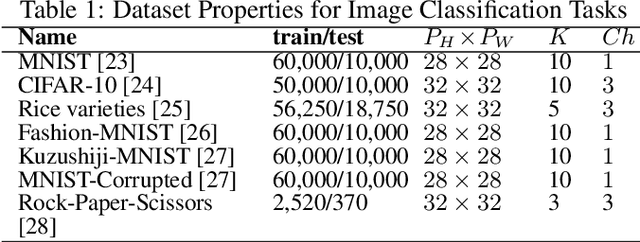
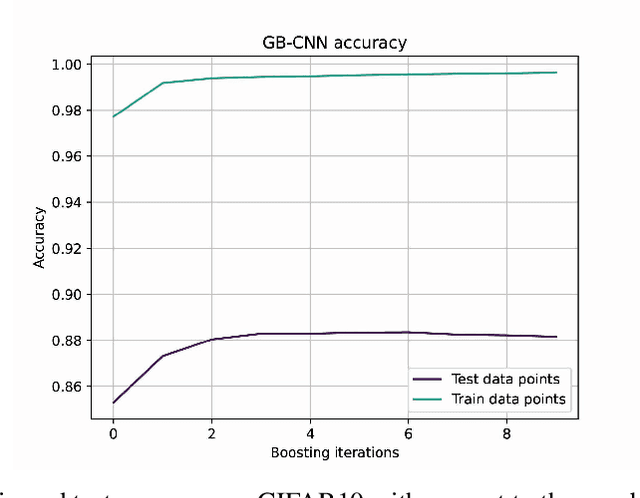
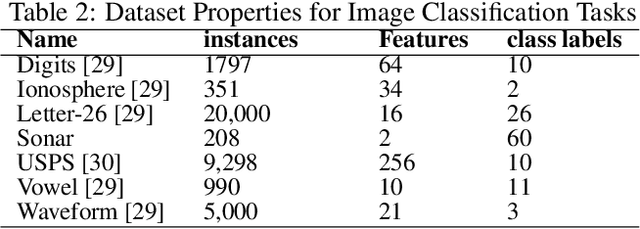
Deep learning has revolutionized the computer vision and image classification domains. In this context Convolutional Neural Networks (CNNs) based architectures are the most widely applied models. In this article, we introduced two procedures for training Convolutional Neural Networks (CNNs) and Deep Neural Network based on Gradient Boosting (GB), namely GB-CNN and GB-DNN. These models are trained to fit the gradient of the loss function or pseudo-residuals of previous models. At each iteration, the proposed method adds one dense layer to an exact copy of the previous deep NN model. The weights of the dense layers trained on previous iterations are frozen to prevent over-fitting, permitting the model to fit the new dense as well as to fine-tune the convolutional layers (for GB-CNN) while still utilizing the information already learned. Through extensive experimentation on different 2D-image classification and tabular datasets, the presented models show superior performance in terms of classification accuracy with respect to standard CNN and Deep-NN with the same architectures.
Condensed Gradient Boosting
Nov 26, 2022This paper presents a computationally efficient variant of gradient boosting for multi-class classification and multi-output regression tasks. Standard gradient boosting uses a 1-vs-all strategy for classifications tasks with more than two classes. This strategy translates in that one tree per class and iteration has to be trained. In this work, we propose the use of multi-output regressors as base models to handle the multi-class problem as a single task. In addition, the proposed modification allows the model to learn multi-output regression problems. An extensive comparison with other multi-ouptut based gradient boosting methods is carried out in terms of generalization and computational efficiency. The proposed method showed the best trade-off between generalization ability and training and predictions speeds.
A Comparative Analysis of XGBoost
Nov 05, 2019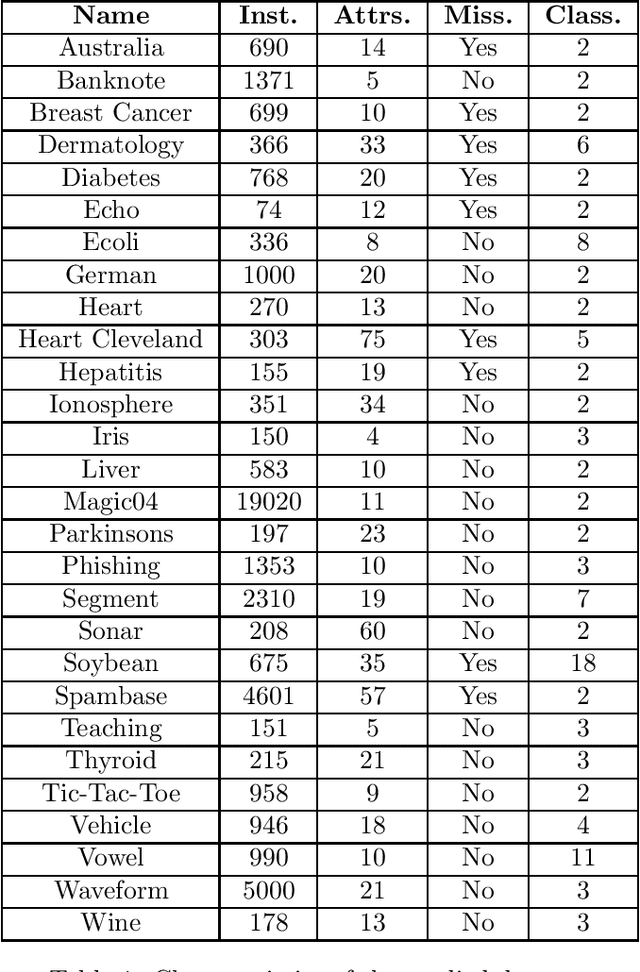
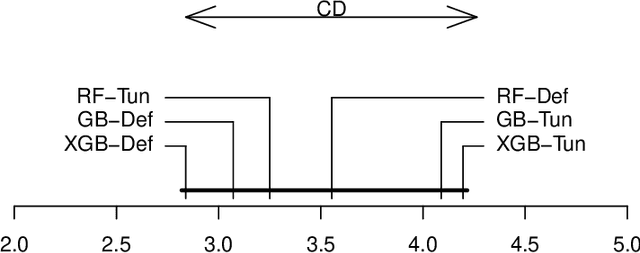
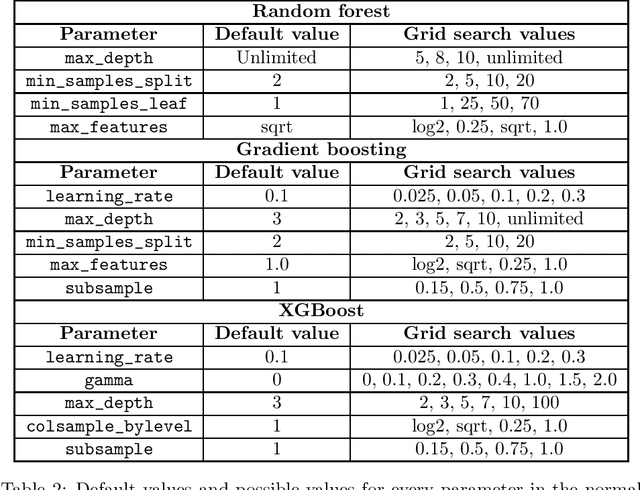
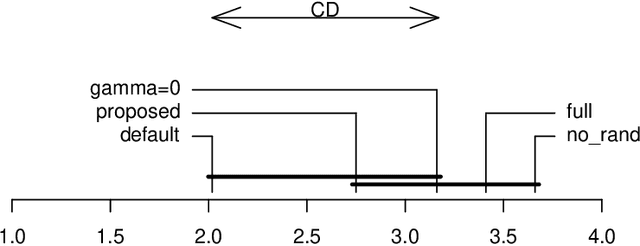
XGBoost is a scalable ensemble technique based on gradient boosting that has demonstrated to be a reliable and efficient machine learning challenge solver. This work proposes a practical analysis of how this novel technique works in terms of training speed, generalization performance and parameter setup. In addition, a comprehensive comparison between XGBoost, random forests and gradient boosting has been performed using carefully tuned models as well as using the default settings. The results of this comparison may indicate that XGBoost is not necessarily the best choice under all circumstances. Finally an extensive analysis of XGBoost parametrization tuning process is carried out.
Sequential Training of Neural Networks with Gradient Boosting
Sep 26, 2019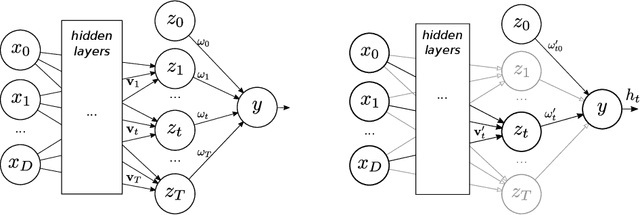
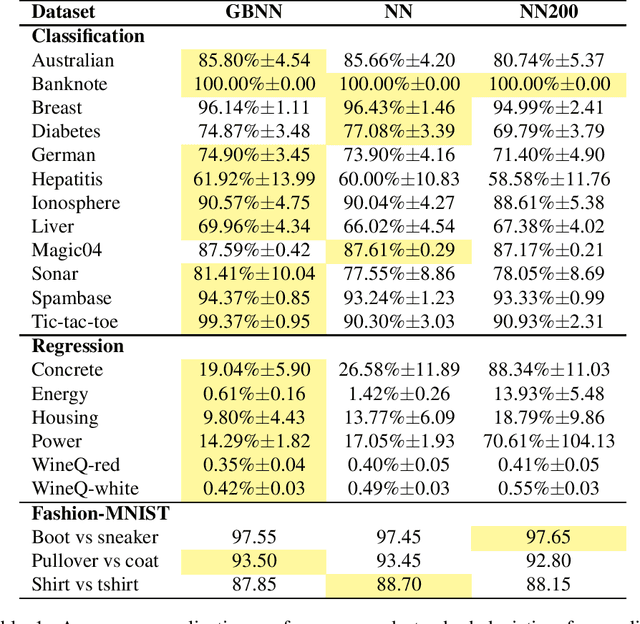
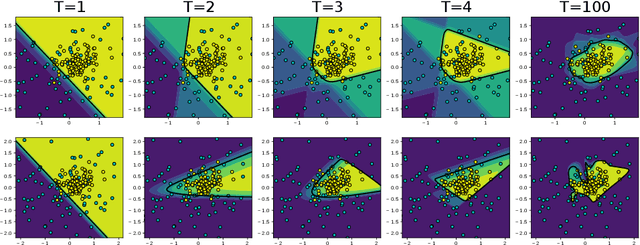
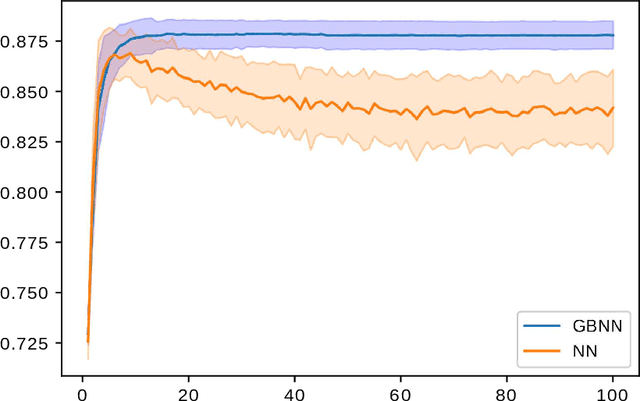
This paper presents a novel technique based on gradient boosting to train a shallow neural network (NN). Gradient boosting is an additive expansion algorithm in which a series of models are trained sequentially to approximate a given function. A one hidden layer neural network can also be seen as an additive model where the scalar product of the responses of the hidden layer and its weights provide the final output of the network. Instead of training the network as a whole, the proposed algorithm trains the network sequentially in $T$ steps. First, the bias term of the network is initialized with a constant approximation that minimizes the average loss of the data. Then, at each step, a portion of the network, composed of $K$ neurons, is trained to approximate the pseudo-residuals on the training data computed from the previous iteration. Finally, the $T$ partial models and bias are integrated as a single NN with $T \times K$ neurons in the hidden layer. We show that the proposed algorithm is more robust to overfitting than a standard neural network with respect to the number of neurons of the last hidden layer. Furthermore, we show that the proposed method design permits to reduce the number of neurons to be used without a significant reduction of its generalization ability. This permits to adapt the model to different classification speed requirements on the fly. Extensive experiments in classification and regression tasks, as well as in combination with a deep convolutional neural network, are carried out showing a better generalization performance than a standard neural network.
Pooling homogeneous ensembles to build heterogeneous ensembles
Feb 21, 2018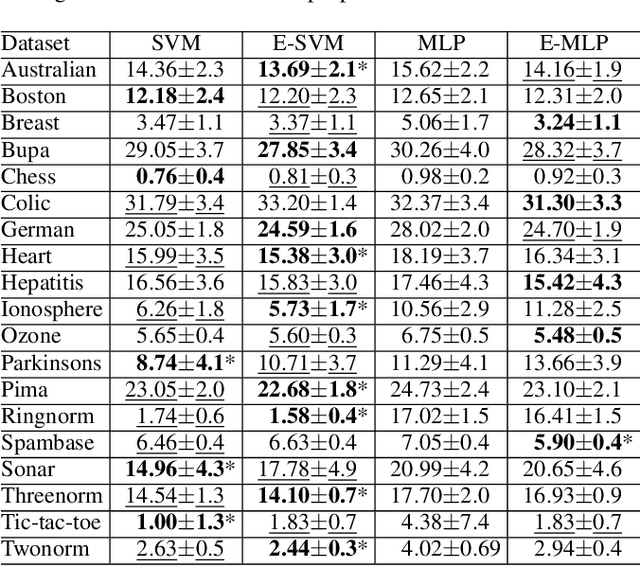
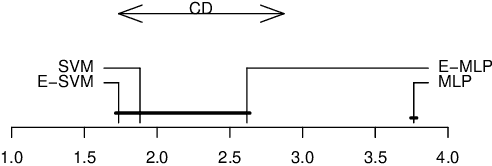
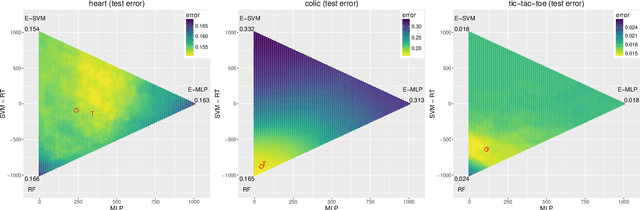
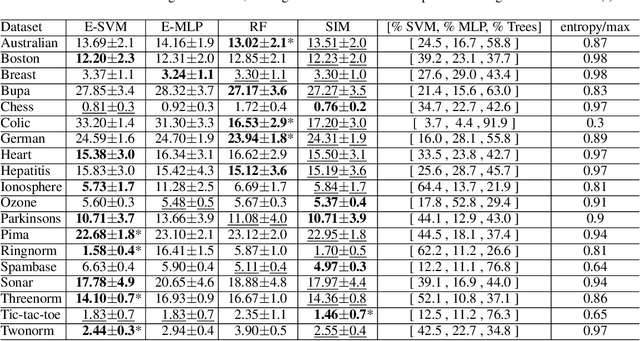
In ensemble methods, the outputs of a collection of diverse classifiers are combined in the expectation that the global prediction be more accurate than the individual ones. Heterogeneous ensembles consist of predictors of different types, which are likely to have different biases. If these biases are complementary, the combination of their decisions is beneficial. In this work, a family of heterogeneous ensembles is built by pooling classifiers from M homogeneous ensembles of different types of size T. Depending on the fraction of base classifiers of each type, a particular heterogeneous combination in this family is represented by a point in a regular simplex in M dimensions. The M vertices of this simplex represent the different homogeneous ensembles. A displacement away from one of these vertices effects a smooth transformation of the corresponding homogeneous ensemble into a heterogeneous one. The optimal composition of such heterogeneous ensemble can be determined using cross-validation or, if bootstrap samples are used to build the individual classifiers, out-of-bag data. An empirical analysis of such combinations of bootstraped ensembles composed of neural networks, SVMs, and random trees (i.e. from a standard random forest) illustrates the gains that can be achieved by this heterogeneous ensemble creation method.
Vote-boosting ensembles
Feb 21, 2018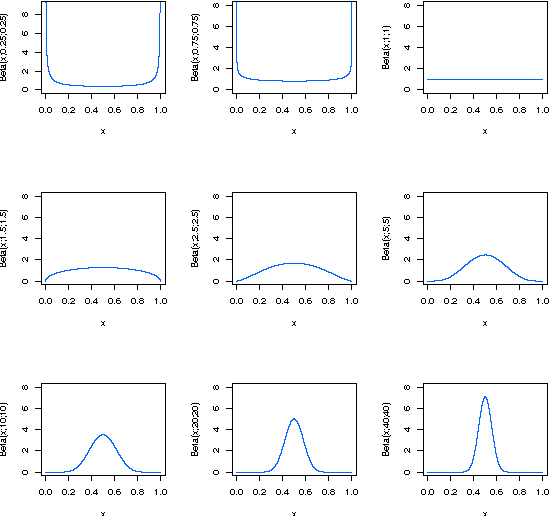
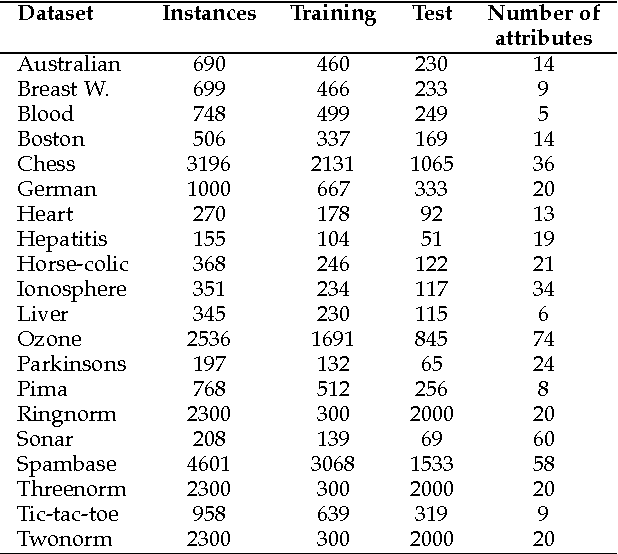
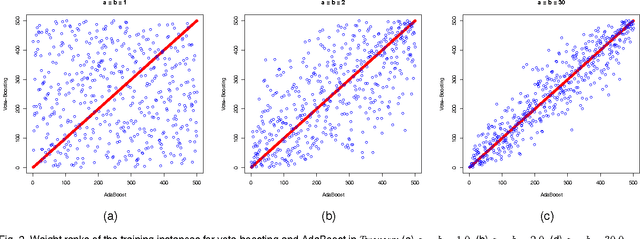
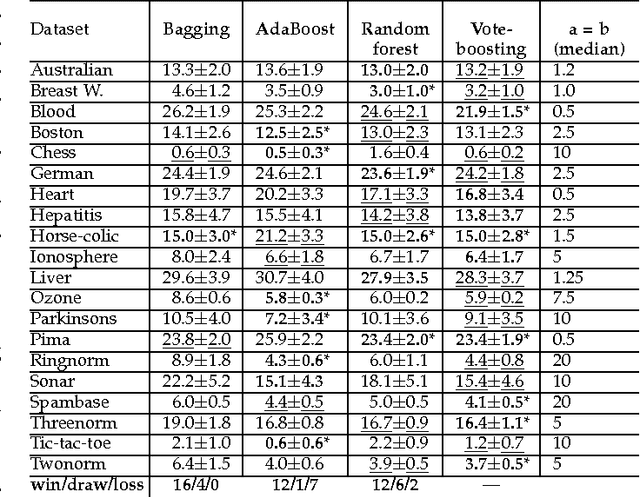
Vote-boosting is a sequential ensemble learning method in which the individual classifiers are built on different weighted versions of the training data. To build a new classifier, the weight of each training instance is determined in terms of the degree of disagreement among the current ensemble predictions for that instance. For low class-label noise levels, especially when simple base learners are used, emphasis should be made on instances for which the disagreement rate is high. When more flexible classifiers are used and as the noise level increases, the emphasis on these uncertain instances should be reduced. In fact, at sufficiently high levels of class-label noise, the focus should be on instances on which the ensemble classifiers agree. The optimal type of emphasis can be automatically determined using cross-validation. An extensive empirical analysis using the beta distribution as emphasis function illustrates that vote-boosting is an effective method to generate ensembles that are both accurate and robust.