 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Entity Chains for Abstractive Summarization
Apr 15, 2021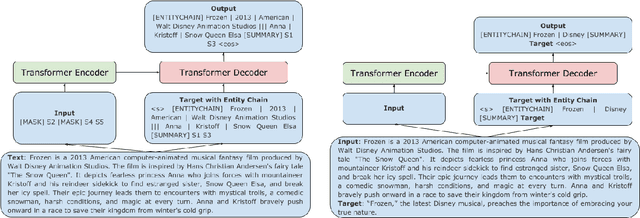

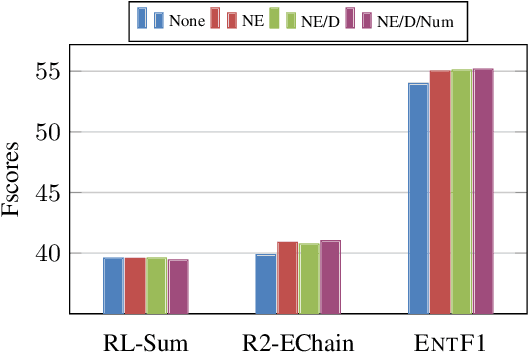
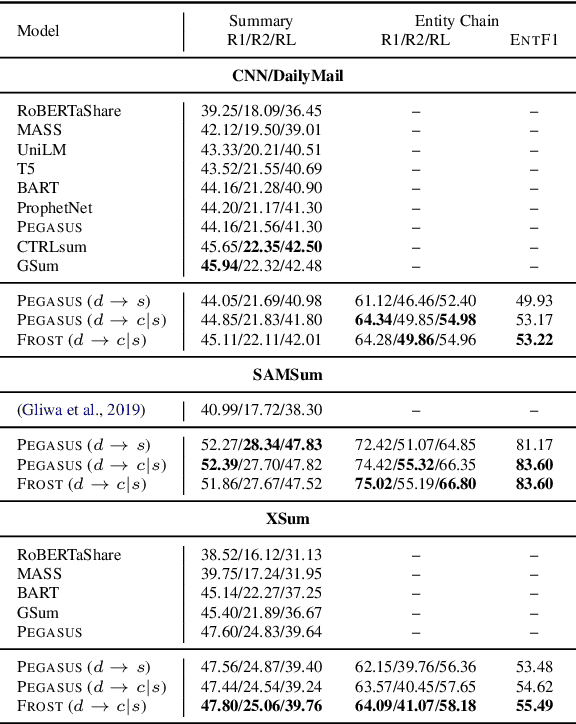
Pre-trained transformer-based sequence-to-sequence models have become the go-to solution for many text generation tasks, including summarization. However, the results produced by these models tend to contain significant issues such as hallucinations and irrelevant passages. One solution to mitigate these problems is to incorporate better content planning in neural summarization. We propose to use entity chains (i.e., chains of entities mentioned in the summary) to better plan and ground the generation of abstractive summaries. In particular, we augment the target by prepending it with its entity chain. We experimented with both pre-training and finetuning with this content planning objective. When evaluated on CNN/DailyMail, SAMSum and XSum, models trained with this objective improved on entity correctness and summary conciseness, and achieved state-of-the-art performance on ROUGE for SAMSum and XSum.
QURIOUS: Question Generation Pretraining for Text Generation
Apr 23, 2020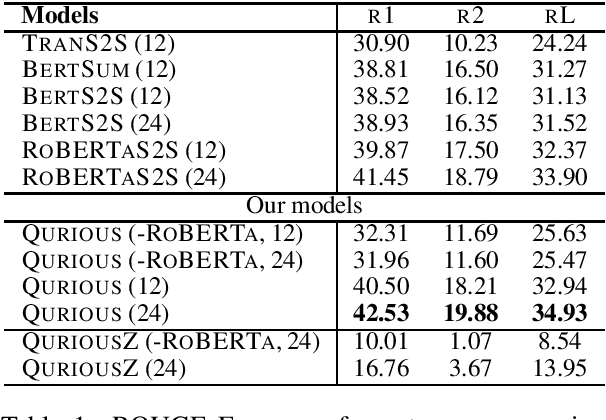
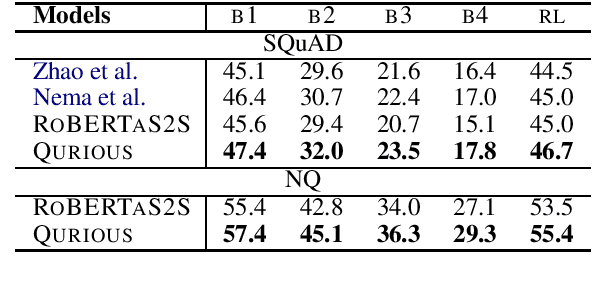
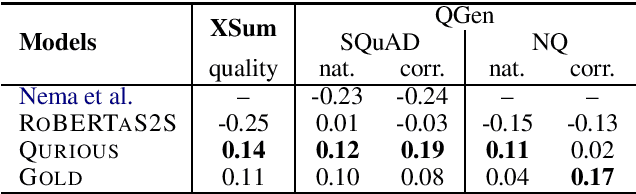
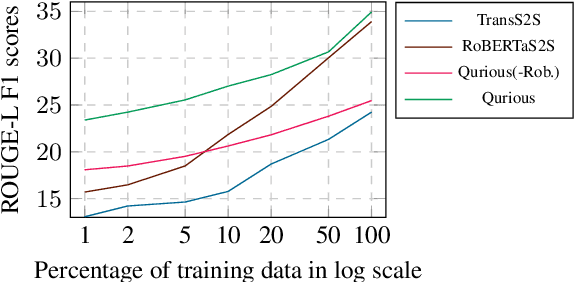
Recent trends in natural language processing using pretraining have shifted focus towards pretraining and fine-tuning approaches for text generation. Often the focus has been on task-agnostic approaches that generalize the language modeling objective. We propose question generation as a pretraining method, which better aligns with the text generation objectives. Our text generation models pretrained with this method are better at understanding the essence of the input and are better language models for the target task. When evaluated on two text generation tasks, abstractive summarization and answer-focused question generation, our models result in state-of-the-art performances in terms of automatic metrics. Human evaluators also found our summaries and generated questions to be more natural, concise and informative.