 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Information Complexity of Learning Tasks, their Structure and their Distance
Apr 05, 2019

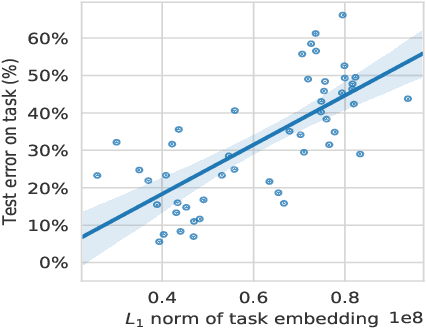
We introduce an asymmetric distance in the space of learning tasks, and a framework to compute their complexity. These concepts are foundational to the practice of transfer learning, ubiquitous in Deep Learning, whereby a parametric model is pre-trained for a task, and then used for another after fine-tuning. The framework we develop is intrinsically non-asymptotic, capturing the finite nature of the training dataset, yet it allows distinguishing learning from memorization. It encompasses, as special cases, classical notions from Kolmogorov complexity, Shannon, and Fisher Information. However, unlike some of those frameworks, it can be applied easily to large-scale models and real-world datasets. It is the first framework to explicitly account for the optimization scheme, which plays a crucial role in Deep Learning, in measuring complexity and information.