 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Mixture-of-Experts Approach for Cytotoxic Edema Assessment in Infants and Children
Oct 06, 2022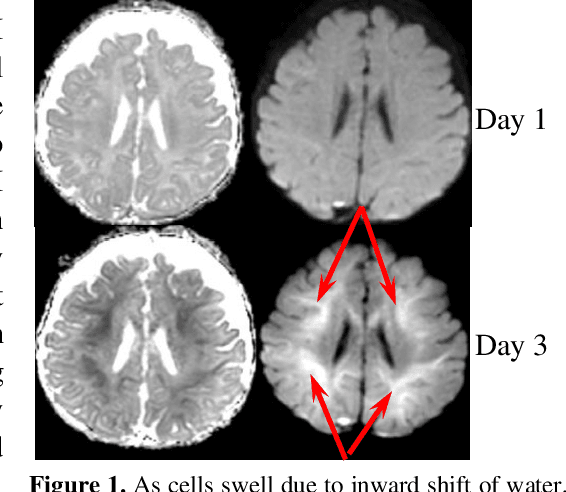
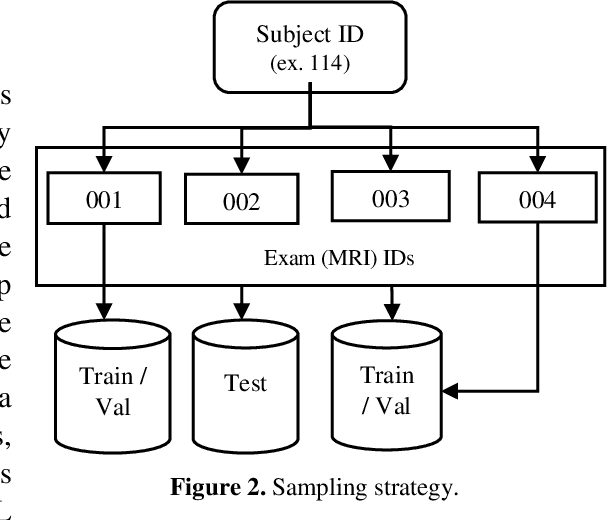
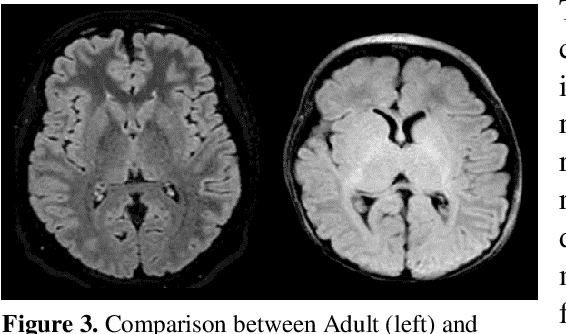
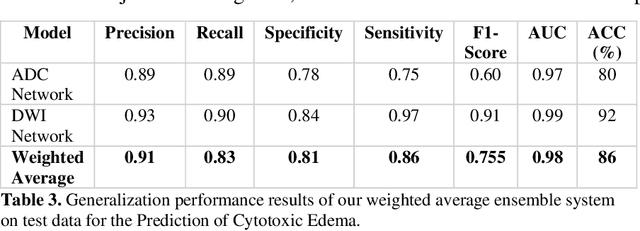
This paper presents a deep learning framework for image classification aimed at increasing predictive performance for Cytotoxic Edema (CE) diagnosis in infants and children. The proposed framework includes two 3D network architectures optimized to learn from two types of clinical MRI data , a trace Diffusion Weighted Image (DWI) and the calculated Apparent Diffusion Coefficient map (ADC). This work proposes a robust and novel solution based on volumetric analysis of 3D images (using pixels from time slices) and 3D convolutional neural network (CNN) models. While simple in architecture, the proposed framework shows significant quantitative results on the domain problem. We use a dataset curated from a Childrens Hospital Colorado (CHCO) patient registry to report a predictive performance F1 score of 0.91 at distinguishing CE patients from children with severe neurologic injury without CE. In addition, we perform analysis of our systems output to determine the association of CE with Abusive Head Trauma (AHT) , a type of traumatic brain injury (TBI) associated with abuse , and overall functional outcome and in hospital mortality of infants and young children. We used two clinical variables, AHT diagnosis and Functional Status Scale (FSS) score, to arrive at the conclusion that CE is highly correlated with overall outcome and that further study is needed to determine whether CE is a biomarker of AHT. With that, this paper introduces a simple yet powerful deep learning based solution for automated CE classification. This solution also enables an indepth analysis of progression of CE and its correlation to AHT and overall neurologic outcome, which in turn has the potential to empower experts to diagnose and mitigate AHT during early stages of a childs life.
GPRAR: Graph Convolutional Network based Pose Reconstruction and Action Recognition for Human Trajectory Prediction
Mar 25, 2021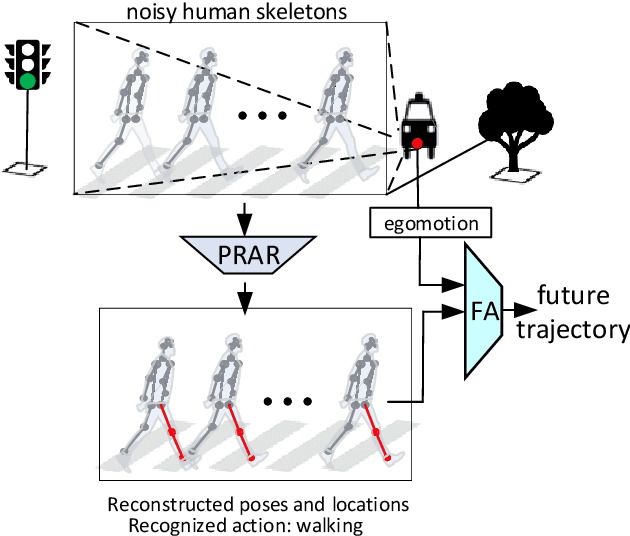
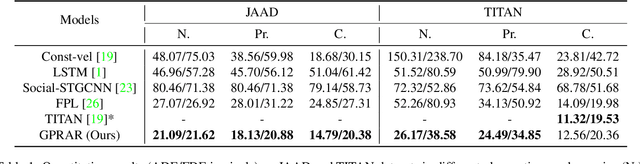
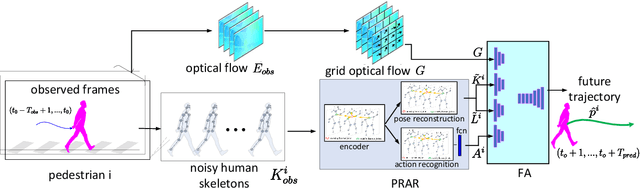

Prediction with high accuracy is essential for various applications such as autonomous driving. Existing prediction models are easily prone to errors in real-world settings where observations (e.g. human poses and locations) are often noisy. To address this problem, we introduce GPRAR, a graph convolutional network based pose reconstruction and action recognition for human trajectory prediction. The key idea of GPRAR is to generate robust features: human poses and actions, under noisy scenarios. To this end, we design GPRAR using two novel sub-networks: PRAR (Pose Reconstruction and Action Recognition) and FA (Feature Aggregator). PRAR aims to simultaneously reconstruct human poses and action features from the coherent and structural properties of human skeletons. It is a network of an encoder and two decoders, each of which comprises multiple layers of spatiotemporal graph convolutional networks. Moreover, we propose a Feature Aggregator (FA) to channel-wise aggregate the learned features: human poses, actions, locations, and camera motion using encoder-decoder based temporal convolutional neural networks to predict future locations. Extensive experiments on the commonly used datasets: JAAD [13] and TITAN [19] show accuracy improvements of GPRAR over state-of-theart models. Specifically, GPRAR improves the prediction accuracy up to 22% and 50% under noisy observations on JAAD and TITAN datasets, respectively
Generator From Edges: Reconstruction of Facial Images
Feb 22, 2020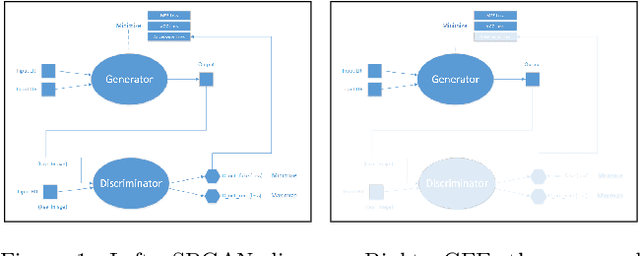

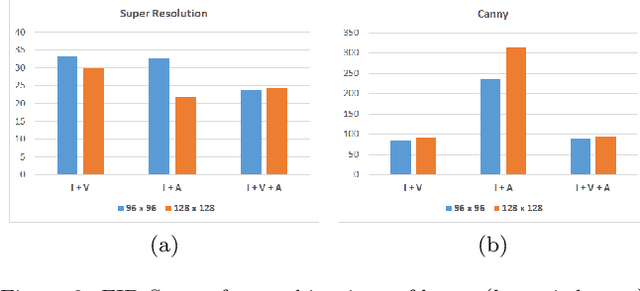
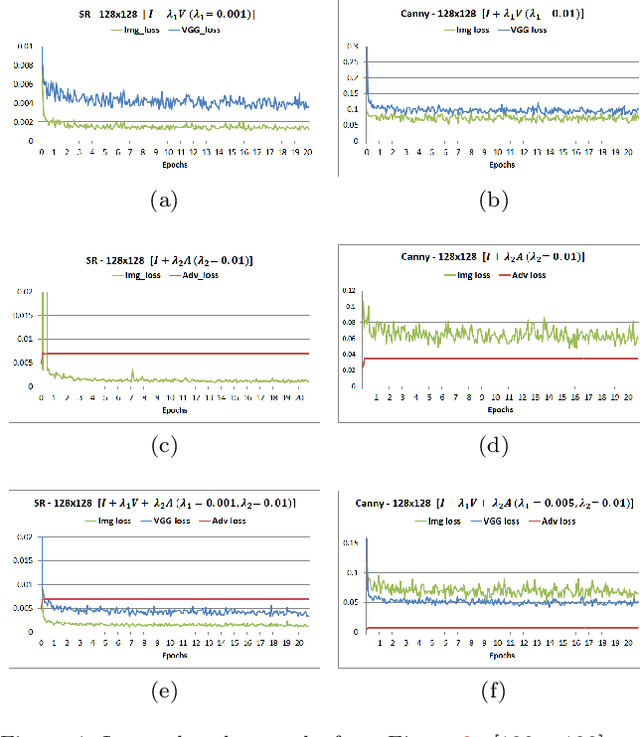
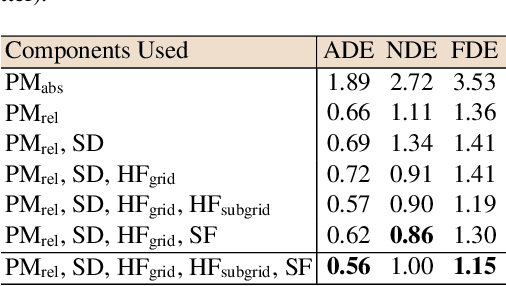
Applications that involve supervised training require paired images. Researchers of single image super-resolution (SISR) create such images by artificially generating blurry input images from the corresponding ground truth. Similarly we can create paired images with the canny edge. We propose Generator From Edges (GFE) [Figure 2]. Our aim is to determine the best architecture for GFE, along with reviews of perceptual loss [1, 2]. To this end, we conducted three experiments. First, we explored the effects of the adversarial loss often used in SISR. In particular, we uncovered that it is not an essential component to form a perceptual loss. Eliminating adversarial loss will lead to a more effective architecture from the perspective of hardware resource. It also means that considerations for the problems pertaining to generative adversarial network (GAN) [3], such as mode collapse, are not necessary. Second, we reexamined VGG loss and found that the mid-layers yield the best results. By extracting the full potential of VGG loss, the overall performance of perceptual loss improves significantly. Third, based on the findings of the first two experiments, we reevaluated the dense network to construct GFE. Using GFE as an intermediate process, reconstructing a facial image from a pencil sketch can become an easy task.
AOL: Adaptive Online Learning for Human Trajectory Prediction in Dynamic Video Scenes
Feb 16, 2020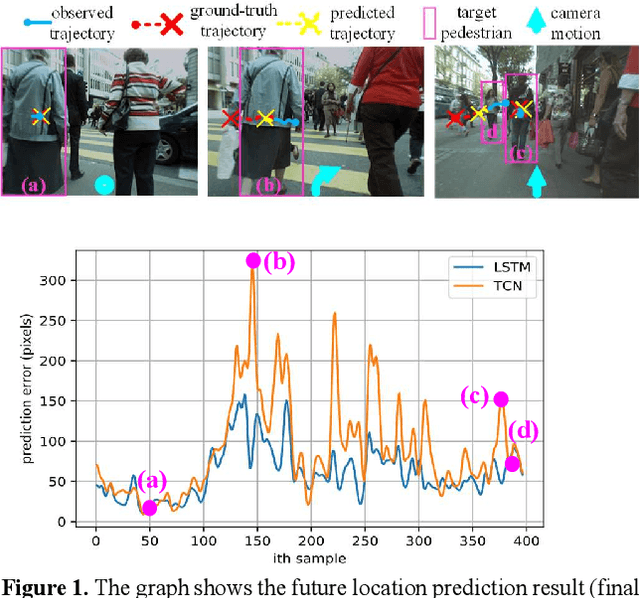
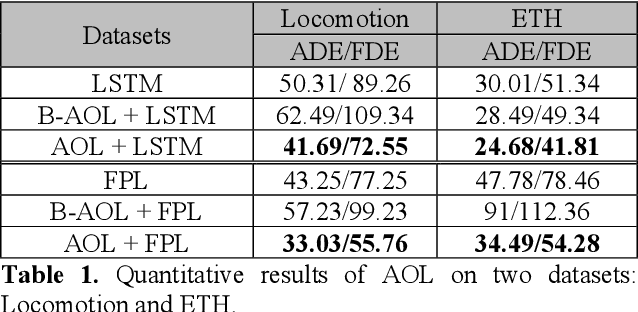
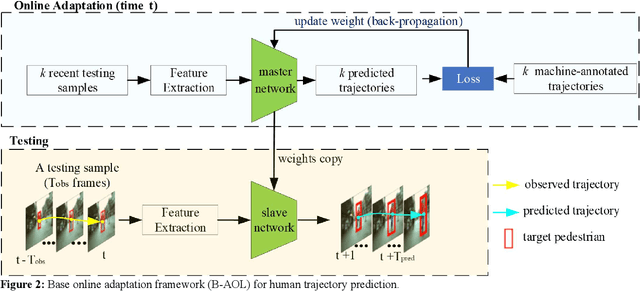

We present a novel adaptive online learning (AOL) framework to predict human movement trajectories in dynamic video scenes. Our framework learns and adapts to changes in the scene environment and generates best network weights for different scenarios. The framework can be applied to prediction models and improve their performance as it dynamically adjusts when it encounters changes in the scene and can apply the best training weights for predicting the next locations. We demonstrate this by integrating our framework with two existing prediction models: LSTM [3] and Future Person Location (FPL) [1]. Furthermore, we analyze the number of network weights for optimal performance and show that we can achieve real-time with a fixed number of networks using the least recently used (LRU) strategy for maintaining the most recently trained network weights. With extensive experiments, we show that our framework increases prediction accuracies of LSTM and FPL by ~17% and 28% on average, and up to ~50% for FPL on the worst case while achieving real-time (20fps).
Trajectory Prediction by Coupling Scene-LSTM with Human Movement LSTM
Aug 23, 2019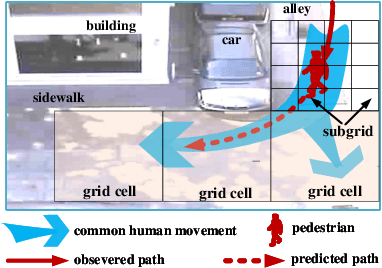
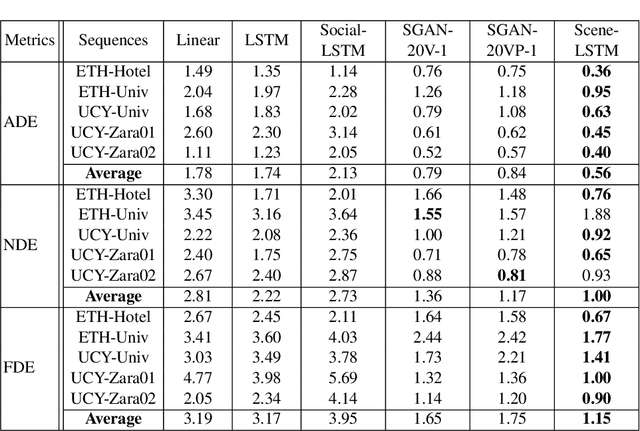
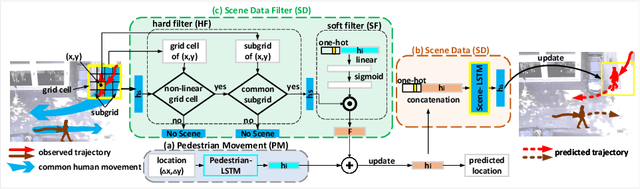
We develop a novel human trajectory prediction system that incorporates the scene information (Scene-LSTM) as well as individual pedestrian movement (Pedestrian-LSTM) trained simultaneously within static crowded scenes. We superimpose a two-level grid structure (grid cells and subgrids) on the scene to encode spatial granularity plus common human movements. The Scene-LSTM captures the commonly traveled paths that can be used to significantly influence the accuracy of human trajectory prediction in local areas (i.e. grid cells). We further design scene data filters, consisting of a hard filter and a soft filter, to select the relevant scene information in a local region when necessary and combine it with Pedestrian-LSTM for forecasting a pedestrian's future locations. The experimental results on several publicly available datasets demonstrate that our method outperforms related works and can produce more accurate predicted trajectories in different scene contexts.
SRGAN: Training Dataset Matters
Mar 24, 2019

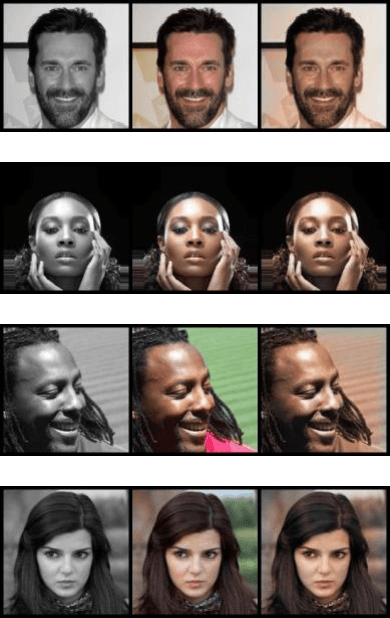

Generative Adversarial Networks (GANs) in supervised settings can generate photo-realistic corresponding output from low-definition input (SRGAN). Using the architecture presented in the SRGAN original paper [2], we explore how selecting a dataset affects the outcome by using three different datasets to see that SRGAN fundamentally learns objects, with their shape, color, and texture, and redraws them in the output rather than merely attempting to sharpen edges. This is further underscored with our demonstration that once the network learns the images of the dataset, it can generate a photo-like image with even a slight hint of what it might look like for the original from a very blurry edged sketch. Given a set of inference images, the network trained with the same dataset results in a better outcome over the one trained with arbitrary set of images, and we report its significance numerically with Frechet Inception Distance score [22].
Scene-LSTM: A Model for Human Trajectory Prediction
Aug 12, 2018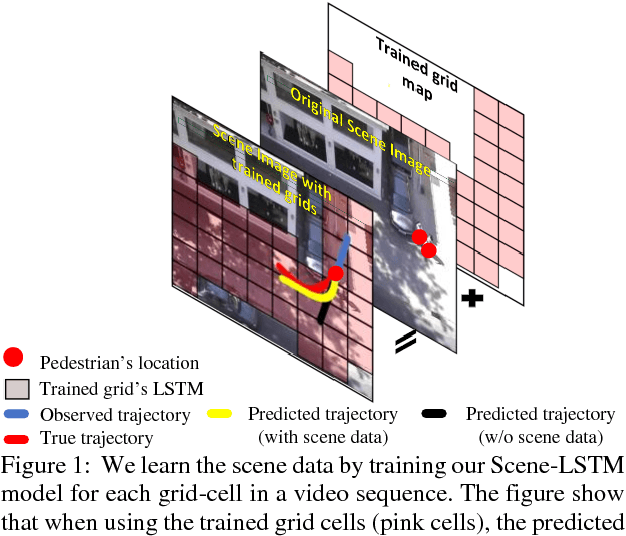
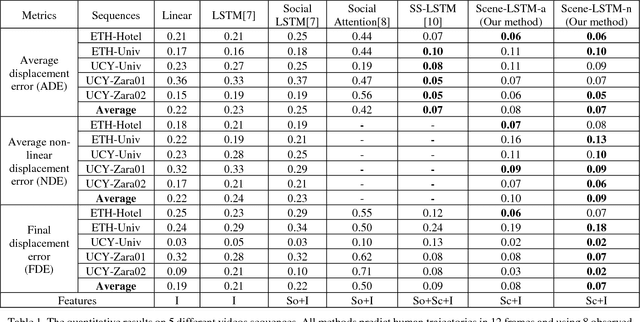
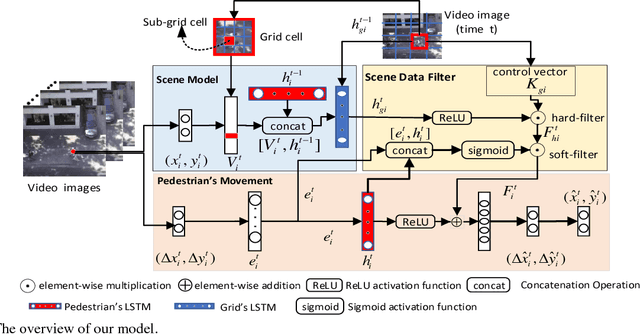
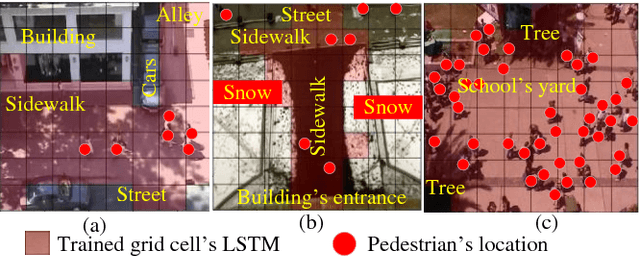
We develop a human movement trajectory prediction system that incorporates the scene information (Scene-LSTM) as well as human movement trajectories (Pedestrian movement LSTM) in the prediction process within static crowded scenes. We superimpose a two-level grid structure (scene is divided into grid cells each modeled by a scene-LSTM, which are further divided into smaller sub-grids for finer spatial granularity) and explore common human trajectories occurring in the grid cell (e.g., making a right or left turn onto sidewalks coming out of an alley; or standing still at bus/train stops). Two coupled LSTM networks, Pedestrian movement LSTMs (one per target) and the corresponding Scene-LSTMs (one per grid-cell) are trained simultaneously to predict the next movements. We show that such common path information greatly influences prediction of future movement. We further design a scene data filter that holds important non-linear movement information. The scene data filter allows us to select the relevant parts of the information from the grid cell's memory relative to a target's state. We evaluate and compare two versions of our method with the Linear and several existing LSTM-based methods on five crowded video sequences from the UCY [1] and ETH [2] datasets. The results show that our method reduces the location displacement errors compared to related methods and specifically about 80% reduction compared to social interaction methods.
Spatiotemporal KSVD Dictionary Learning for Online Multi-target Tracking
Jul 05, 2018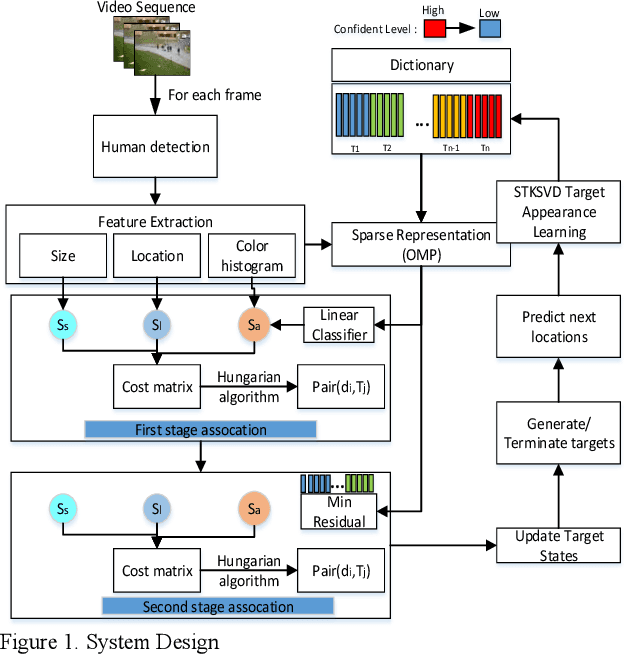
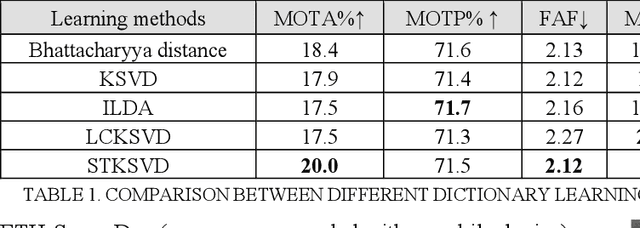
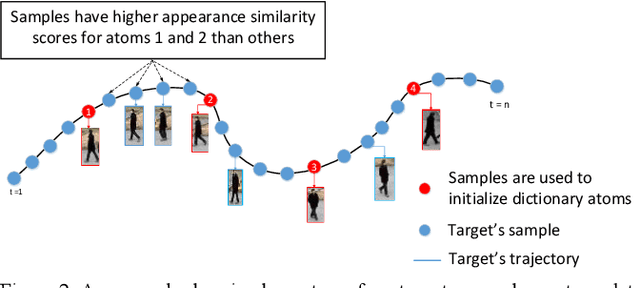
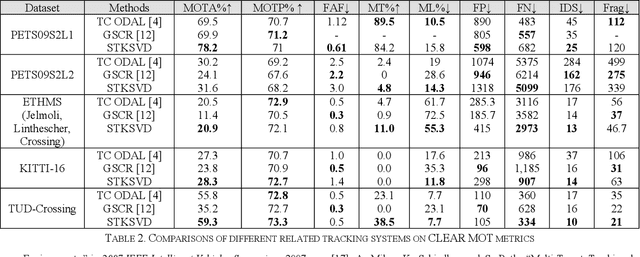
In this paper, we present a new spatial discriminative KSVD dictionary algorithm (STKSVD) for learning target appearance in online multi-target tracking. Different from other classification/recognition tasks (e.g. face, image recognition), learning target's appearance in online multi-target tracking is impacted by factors such as posture/articulation changes, partial occlusion by background scene or other targets, background changes (human detection bounding box covers human parts and part of the scene), etc. However, we observe that these variations occur gradually relative to spatial and temporal dynamics. We characterize the spatial and temporal information between target's samples through a new STKSVD appearance learning algorithm to better discriminate sparse code, linear classifier parameters and minimize reconstruction error in a single optimization system. Our appearance learning algorithm and tracking framework employ two different methods of calculating appearance similarity score in each stage of a two-stage association: a linear classifier in the first stage, and minimum residual errors in the second stage. The results tested using 2DMOT2015 dataset and its public Aggregated Channel features (ACF) human detection for all comparisons show that our method outperforms the existing related learning methods.