 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-LSTM: A Model for Human Trajectory Prediction
Aug 12, 2018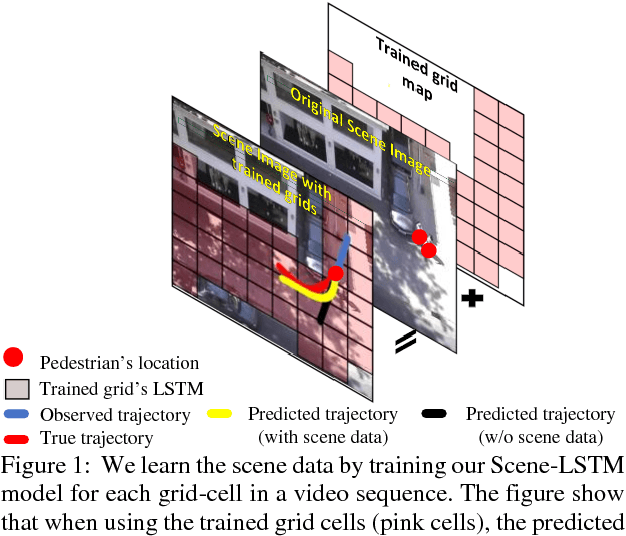
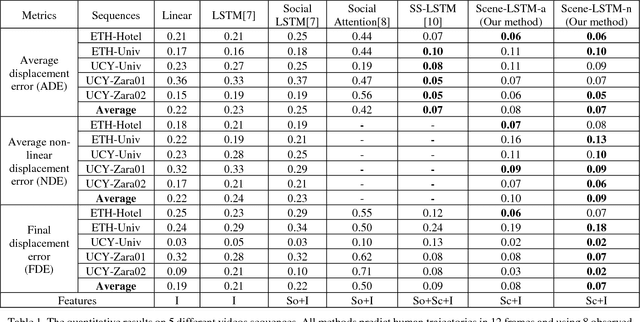
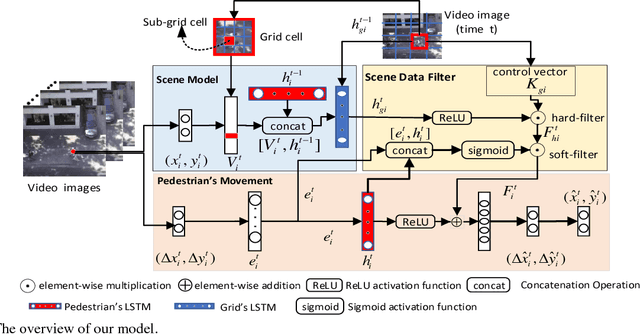
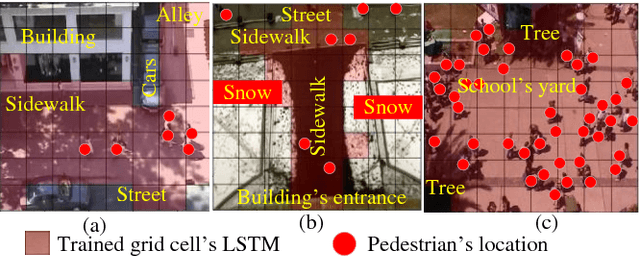
We develop a human movement trajectory prediction system that incorporates the scene information (Scene-LSTM) as well as human movement trajectories (Pedestrian movement LSTM) in the prediction process within static crowded scenes. We superimpose a two-level grid structure (scene is divided into grid cells each modeled by a scene-LSTM, which are further divided into smaller sub-grids for finer spatial granularity) and explore common human trajectories occurring in the grid cell (e.g., making a right or left turn onto sidewalks coming out of an alley; or standing still at bus/train stops). Two coupled LSTM networks, Pedestrian movement LSTMs (one per target) and the corresponding Scene-LSTMs (one per grid-cell) are trained simultaneously to predict the next movements. We show that such common path information greatly influences prediction of future movement. We further design a scene data filter that holds important non-linear movement information. The scene data filter allows us to select the relevant parts of the information from the grid cell's memory relative to a target's state. We evaluate and compare two versions of our method with the Linear and several existing LSTM-based methods on five crowded video sequences from the UCY [1] and ETH [2] datasets. The results show that our method reduces the location displacement errors compared to related methods and specifically about 80% reduction compared to social interaction methods.
Spatiotemporal KSVD Dictionary Learning for Online Multi-target Tracking
Jul 05, 2018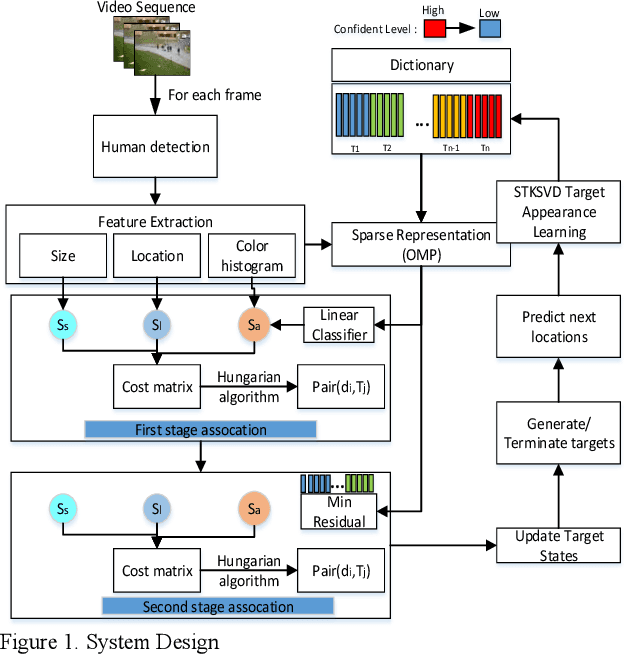
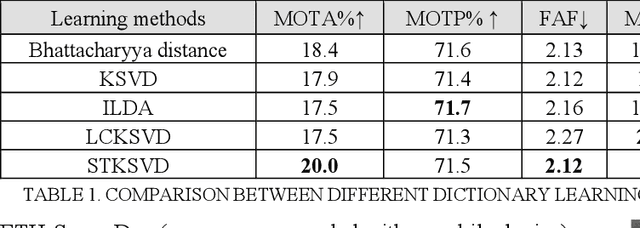
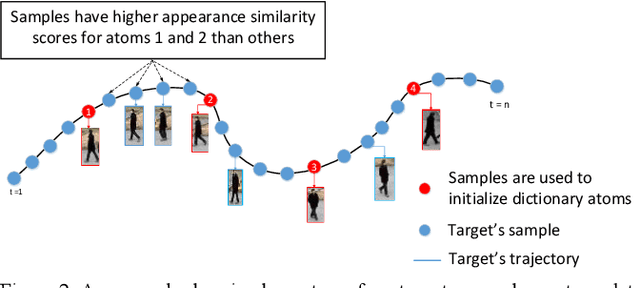
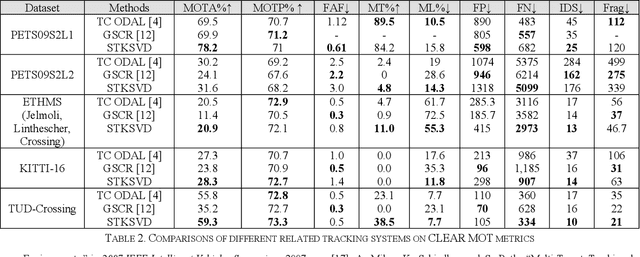
In this paper, we present a new spatial discriminative KSVD dictionary algorithm (STKSVD) for learning target appearance in online multi-target tracking. Different from other classification/recognition tasks (e.g. face, image recognition), learning target's appearance in online multi-target tracking is impacted by factors such as posture/articulation changes, partial occlusion by background scene or other targets, background changes (human detection bounding box covers human parts and part of the scene), etc. However, we observe that these variations occur gradually relative to spatial and temporal dynamics. We characterize the spatial and temporal information between target's samples through a new STKSVD appearance learning algorithm to better discriminate sparse code, linear classifier parameters and minimize reconstruction error in a single optimization system. Our appearance learning algorithm and tracking framework employ two different methods of calculating appearance similarity score in each stage of a two-stage association: a linear classifier in the first stage, and minimum residual errors in the second stage. The results tested using 2DMOT2015 dataset and its public Aggregated Channel features (ACF) human detection for all comparisons show that our method outperforms the existing related learning methods.