 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerator From Edges: Reconstruction of Facial Images
Feb 22, 2020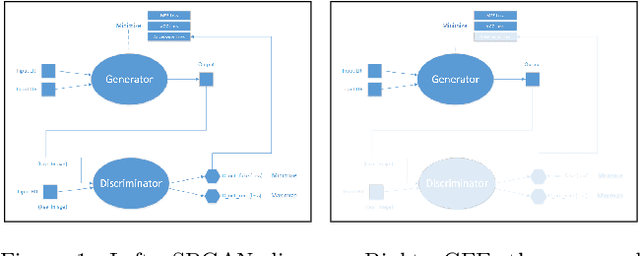

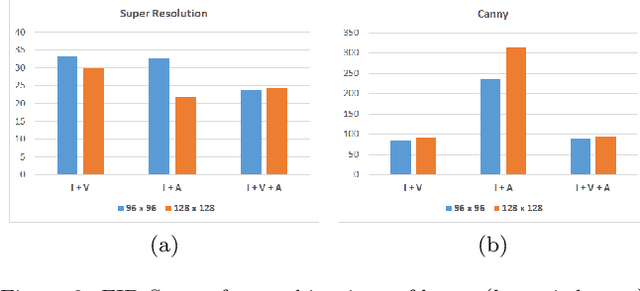
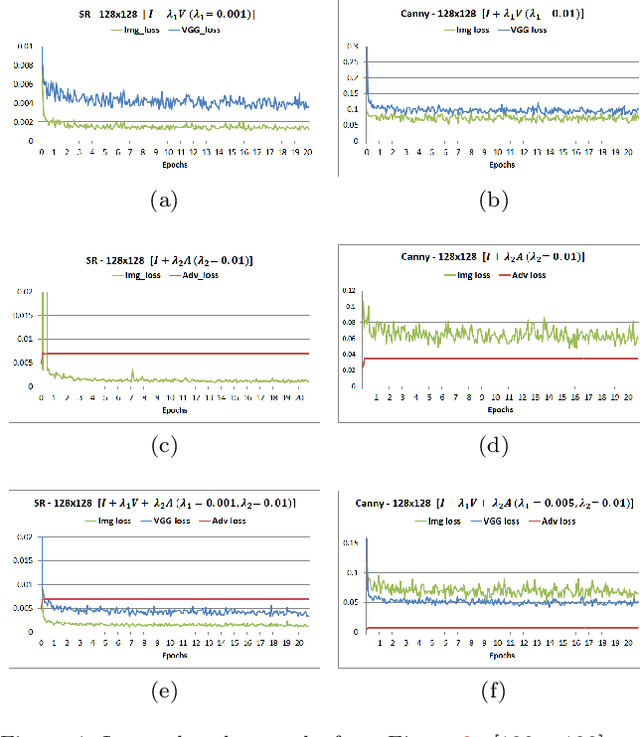
Applications that involve supervised training require paired images. Researchers of single image super-resolution (SISR) create such images by artificially generating blurry input images from the corresponding ground truth. Similarly we can create paired images with the canny edge. We propose Generator From Edges (GFE) [Figure 2]. Our aim is to determine the best architecture for GFE, along with reviews of perceptual loss [1, 2]. To this end, we conducted three experiments. First, we explored the effects of the adversarial loss often used in SISR. In particular, we uncovered that it is not an essential component to form a perceptual loss. Eliminating adversarial loss will lead to a more effective architecture from the perspective of hardware resource. It also means that considerations for the problems pertaining to generative adversarial network (GAN) [3], such as mode collapse, are not necessary. Second, we reexamined VGG loss and found that the mid-layers yield the best results. By extracting the full potential of VGG loss, the overall performance of perceptual loss improves significantly. Third, based on the findings of the first two experiments, we reevaluated the dense network to construct GFE. Using GFE as an intermediate process, reconstructing a facial image from a pencil sketch can become an easy task.
SRGAN: Training Dataset Matters
Mar 24, 2019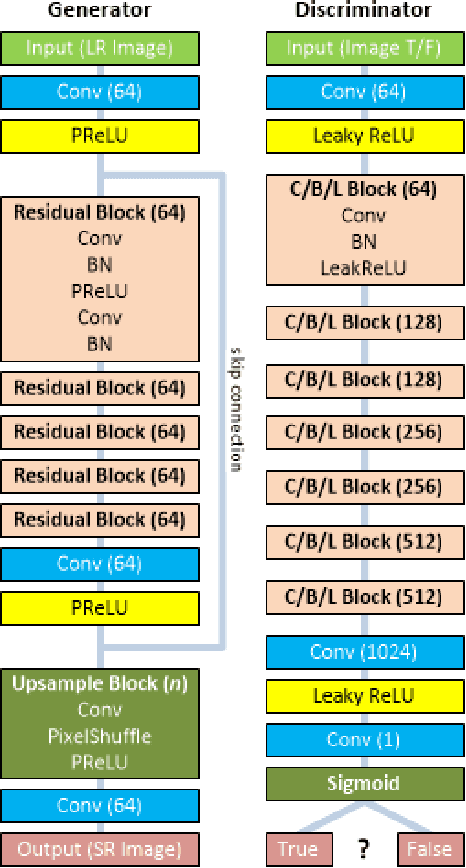

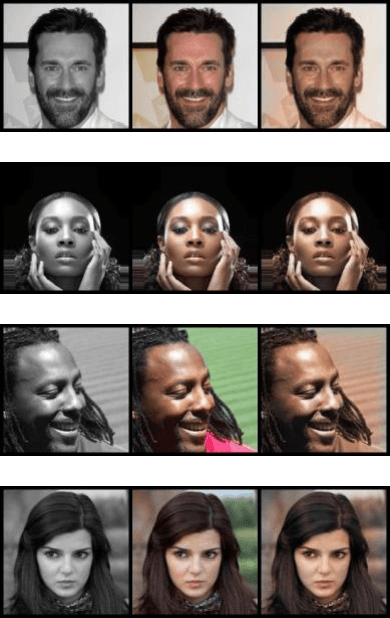

Generative Adversarial Networks (GANs) in supervised settings can generate photo-realistic corresponding output from low-definition input (SRGAN). Using the architecture presented in the SRGAN original paper [2], we explore how selecting a dataset affects the outcome by using three different datasets to see that SRGAN fundamentally learns objects, with their shape, color, and texture, and redraws them in the output rather than merely attempting to sharpen edges. This is further underscored with our demonstration that once the network learns the images of the dataset, it can generate a photo-like image with even a slight hint of what it might look like for the original from a very blurry edged sketch. Given a set of inference images, the network trained with the same dataset results in a better outcome over the one trained with arbitrary set of images, and we report its significance numerically with Frechet Inception Distance score [22].