 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Augmentation for Multi-Task Chinese Porcelain Classification: A Stable Diffusion Approach
Jan 21, 2026The scarcity of training data presents a fundamental challenge in applying deep learning to archaeological artifact classification, particularly for the rare types of Chinese porcelain. This study investigates whether synthetic images generated through Stable Diffusion with Low-Rank Adaptation (LoRA) can effectively augment limited real datasets for multi-task CNN-based porcelain classification. Using MobileNetV3 with transfer learning, we conducted controlled experiments comparing models trained on pure real data against those trained on mixed real-synthetic datasets (95:5 and 90:10 ratios) across four classification tasks: dynasty, glaze, kiln and type identification. Results demonstrate task-specific benefits: type classification showed the most substantial improvement (5.5\% F1-macro increase with 90:10 ratio), while dynasty and kiln tasks exhibited modest gains (3-4\%), suggesting that synthetic augmentation effectiveness depends on the alignment between generated features and task-relevant visual signatures. Our work contributes practical guidelines for deploying generative AI in archaeological research, demonstrating both the potential and limitations of synthetic data when archaeological authenticity must be balanced with data diversity.
Multi-task Learning for Identification of Porcelain in Song and Yuan Dynasties
Mar 18, 2025

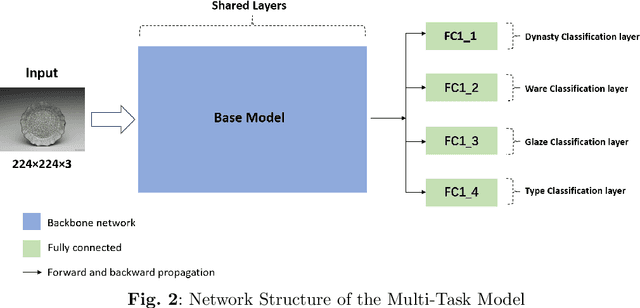

Chinese porcelain holds immense historical and cultural value, making its accurate classification essential for archaeological research and cultural heritage preservation. Traditional classification methods rely heavily on expert analysis, which is time-consuming, subjective, and difficult to scale. This paper explores the application of DL and transfer learning techniques to automate the classification of porcelain artifacts across four key attributes: dynasty, glaze, ware, and type. We evaluate four Convolutional Neural Networks (CNNs) - ResNet50, MobileNetV2, VGG16, and InceptionV3 - comparing their performance with and without pre-trained weights. Our results demonstrate that transfer learning significantly enhances classification accuracy, particularly for complex tasks like type classification, where models trained from scratch exhibit lower performance. MobileNetV2 and ResNet50 consistently achieve high accuracy and robustness across all tasks, while VGG16 struggles with more diverse classifications. We further discuss the impact of dataset limitations and propose future directions, including domain-specific pre-training, integration of attention mechanisms, explainable AI methods, and generalization to other cultural artifacts.
The Barrier of meaning in archaeological data science
Feb 11, 2021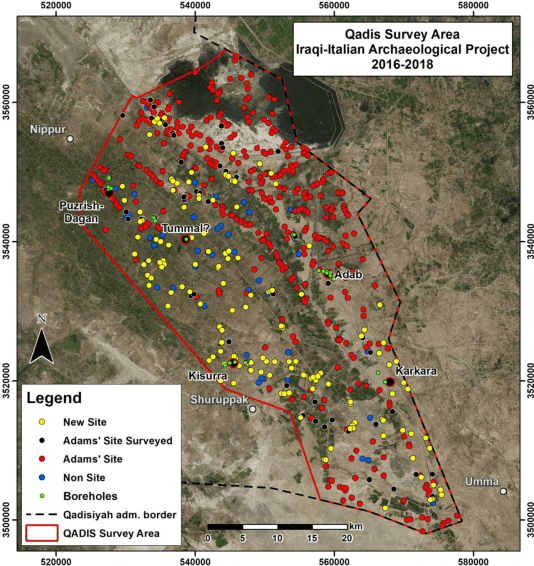


Archaeologists, like other scientists, are experiencing a data-flood in their discipline, fueled by a surge in computing power and devices that enable the creation, collection, storage and transfer of an increasingly complex (and large) amount of data, such as remotely sensed imagery from a multitude of sources. In this paper, we pose the preliminary question if this increasing availability of information actually needs new computerized techniques, and Artificial Intelligence methods, to make new and deeper understanding into archaeological problems. Simply said, while it is a fact that Deep Learning (DL) has become prevalent as a type of machine learning design inspired by the way humans learn, and utilized to perform automatic actions people might describe as intelligent, we want to anticipate, here, a discussion around the subject whether machines, trained following this procedure, can extrapolate, from archaeological data, concepts and meaning in the same way that humans would do. Even prior to getting to technical results, we will start our reflection with a very basic concept: Is a collection of satellite images with notable archaeological sites informative enough to instruct a DL machine to discover new archaeological sites, as well as other potential locations of interest? Further, what if similar results could be reached with less intelligent machines that learn by having people manually program them with rules? Finally: If with barrier of meaning we refer to the extent to which human-like understanding can be achieved by a machine, where should be posed that barrier in the archaeological data science?
Categorical data as a stone guest in a data science project for predicting defective water meters
Feb 05, 2021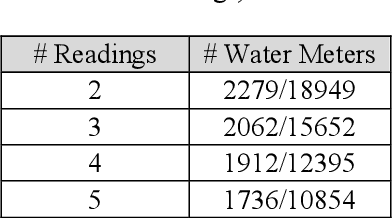

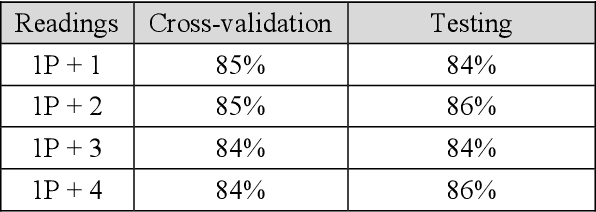
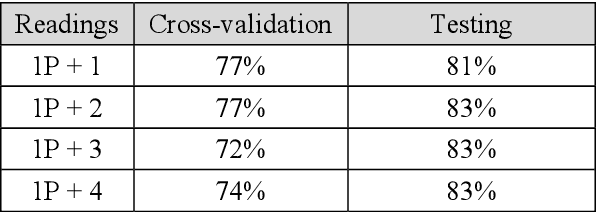
After a one-year long effort of research on the field, we developed a machine learning-based classifier, tailored to predict whether a mechanical water meter would fail with passage of time and intensive use as well. A recurrent deep neural network (RNN) was trained with data extrapolated from 15 million readings of water consumption, gathered from 1 million meters. The data we used for training were essentially of two types: continuous vs categorical. Categorical being a type of data that can take on one of a limited and fixed number of possible values, on the basis of some qualitative property; while continuous, in this case, are the values of the measurements. taken at the meters, of the quantity of consumed water (cubic meters). In this paper, we want to discuss the fact that while the prediction accuracy of our RNN has exceeded the 80% on average, based on the use of continuous data, those performances did not improve, significantly, with the introduction of categorical information during the training phase. From a specific viewpoint, this remains an unsolved and critical problem of our research. Yet, if we reason about this controversial case from a data science perspective, we realize that we have had a confirmation that accurate machine learning solutions cannot be built without the participation of domain experts, who can differentiate on the importance of (the relation between) different types of data, each with its own sense, validity, and implications. Past all the original hype, the science of data is thus evolving towards a multifaceted discipline, where the designitations of data scientist/machine learning expert and domain expert are symbiotic