 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical data as a stone guest in a data science project for predicting defective water meters
Paper and Code
Feb 05, 2021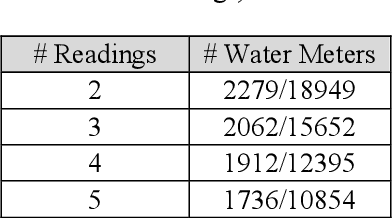

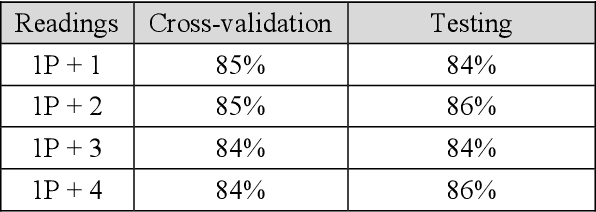
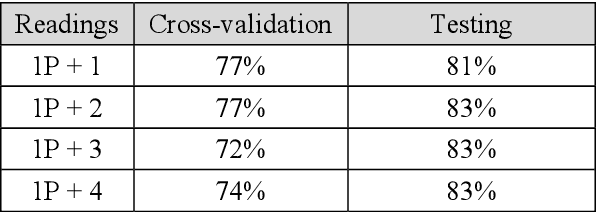
After a one-year long effort of research on the field, we developed a machine learning-based classifier, tailored to predict whether a mechanical water meter would fail with passage of time and intensive use as well. A recurrent deep neural network (RNN) was trained with data extrapolated from 15 million readings of water consumption, gathered from 1 million meters. The data we used for training were essentially of two types: continuous vs categorical. Categorical being a type of data that can take on one of a limited and fixed number of possible values, on the basis of some qualitative property; while continuous, in this case, are the values of the measurements. taken at the meters, of the quantity of consumed water (cubic meters). In this paper, we want to discuss the fact that while the prediction accuracy of our RNN has exceeded the 80% on average, based on the use of continuous data, those performances did not improve, significantly, with the introduction of categorical information during the training phase. From a specific viewpoint, this remains an unsolved and critical problem of our research. Yet, if we reason about this controversial case from a data science perspective, we realize that we have had a confirmation that accurate machine learning solutions cannot be built without the participation of domain experts, who can differentiate on the importance of (the relation between) different types of data, each with its own sense, validity, and implications. Past all the original hype, the science of data is thus evolving towards a multifaceted discipline, where the designitations of data scientist/machine learning expert and domain expert are symbiotic