 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethodological Precedence in Health Tech: Why ML/Big Data Analysis Must Follow Basic Epidemiological Consistency. A Case Study
Nov 10, 2025The integration of advanced analytical tools, including Machine Learning (ML) and massive data processing, has revolutionized health research, promising unprecedented accuracy in diagnosis and risk prediction. However, the rigor of these complex methods is fundamentally dependent on the quality and integrity of the underlying datasets and the validity of their statistical design. We propose an emblematic case where advanced analysis (ML/Big Data) must necessarily be subsequent to the verification of basic methodological coherence. This study highlights a crucial cautionary principle: sophisticated analyses amplify, rather than correct, severe methodological flaws rooted in basic design choices, leading to misleading or contradictory findings. By applying simple, standard descriptive statistical methods and established national epidemiological benchmarks to a recently published cohort study on vaccine outcomes and psychiatric events, we expose multiple, statistically irreconcilable paradoxes. These paradoxes, including an implausible risk reduction for a chronic disorder in a high-risk group and contradictory incidence rate comparisons, definitively invalidate the reported hazard ratios (HRs). We demonstrate that the observed effects are mathematical artifacts stemming from an uncorrected selection bias in the cohort construction. This analysis serves as a robust reminder that even the most complex health studies must first pass the test of basic epidemiological consistency before any conclusion drawn from subsequent advanced ML or statistical modeling can be considered valid or publishable. We conclude that robust methods, such as Propensity Score Matching, are essential for achieving valid causal inference from administrative data in the absence of randomization
AI-ming backwards: Vanishing archaeological landscapes in Mesopotamia and automatic detection of sites on CORONA imagery
Jul 17, 2025By upgrading an existing deep learning model with the knowledge provided by one of the oldest sets of grayscale satellite imagery, known as CORONA, we improved the AI model attitude towards the automatic identification of archaeological sites in an environment which has been completely transformed in the last five decades, including the complete destruction of many of those same sites. The initial Bing based convolutional network model was retrained using CORONA satellite imagery for the district of Abu Ghraib, west of Baghdad, central Mesopotamian floodplain. The results were twofold and surprising. First, the detection precision obtained on the area of interest increased sensibly: in particular, the Intersection over Union (IoU) values, at the image segmentation level, surpassed 85 percent, while the general accuracy in detecting archeological sites reached 90 percent. Second, our retrained model allowed the identification of four new sites of archaeological interest (confirmed through field verification), previously not identified by archaeologists with traditional techniques. This has confirmed the efficacy of using AI techniques and the CORONA imagery from the 1960 to discover archaeological sites currently no longer visible, a concrete breakthrough with significant consequences for the study of landscapes with vanishing archaeological evidence induced by anthropization
The Barrier of meaning in archaeological data science
Feb 11, 2021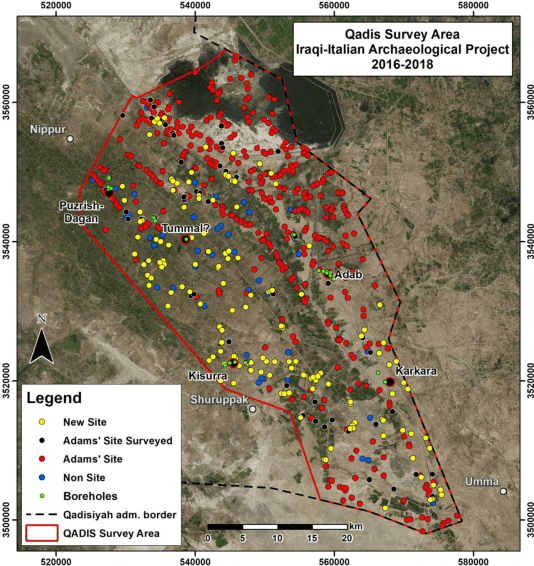


Archaeologists, like other scientists, are experiencing a data-flood in their discipline, fueled by a surge in computing power and devices that enable the creation, collection, storage and transfer of an increasingly complex (and large) amount of data, such as remotely sensed imagery from a multitude of sources. In this paper, we pose the preliminary question if this increasing availability of information actually needs new computerized techniques, and Artificial Intelligence methods, to make new and deeper understanding into archaeological problems. Simply said, while it is a fact that Deep Learning (DL) has become prevalent as a type of machine learning design inspired by the way humans learn, and utilized to perform automatic actions people might describe as intelligent, we want to anticipate, here, a discussion around the subject whether machines, trained following this procedure, can extrapolate, from archaeological data, concepts and meaning in the same way that humans would do. Even prior to getting to technical results, we will start our reflection with a very basic concept: Is a collection of satellite images with notable archaeological sites informative enough to instruct a DL machine to discover new archaeological sites, as well as other potential locations of interest? Further, what if similar results could be reached with less intelligent machines that learn by having people manually program them with rules? Finally: If with barrier of meaning we refer to the extent to which human-like understanding can be achieved by a machine, where should be posed that barrier in the archaeological data science?
Categorical data as a stone guest in a data science project for predicting defective water meters
Feb 05, 2021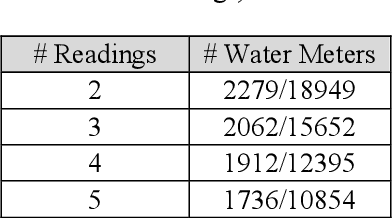

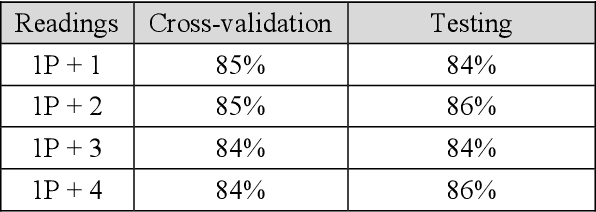
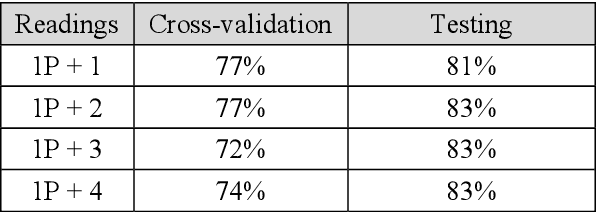
After a one-year long effort of research on the field, we developed a machine learning-based classifier, tailored to predict whether a mechanical water meter would fail with passage of time and intensive use as well. A recurrent deep neural network (RNN) was trained with data extrapolated from 15 million readings of water consumption, gathered from 1 million meters. The data we used for training were essentially of two types: continuous vs categorical. Categorical being a type of data that can take on one of a limited and fixed number of possible values, on the basis of some qualitative property; while continuous, in this case, are the values of the measurements. taken at the meters, of the quantity of consumed water (cubic meters). In this paper, we want to discuss the fact that while the prediction accuracy of our RNN has exceeded the 80% on average, based on the use of continuous data, those performances did not improve, significantly, with the introduction of categorical information during the training phase. From a specific viewpoint, this remains an unsolved and critical problem of our research. Yet, if we reason about this controversial case from a data science perspective, we realize that we have had a confirmation that accurate machine learning solutions cannot be built without the participation of domain experts, who can differentiate on the importance of (the relation between) different types of data, each with its own sense, validity, and implications. Past all the original hype, the science of data is thus evolving towards a multifaceted discipline, where the designitations of data scientist/machine learning expert and domain expert are symbiotic