 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provably Efficient Option-Based Algorithm for both High-Level and Low-Level Learning
Jun 21, 2024Hierarchical Reinforcement Learning (HRL) approaches have shown successful results in solving a large variety of complex, structured, long-horizon problems. Nevertheless, a full theoretical understanding of this empirical evidence is currently missing. In the context of the \emph{option} framework, prior research has devised efficient algorithms for scenarios where options are fixed, and the high-level policy selecting among options only has to be learned. However, the fully realistic scenario in which both the high-level and the low-level policies are learned is surprisingly disregarded from a theoretical perspective. This work makes a step towards the understanding of this latter scenario. Focusing on the finite-horizon problem, we present a meta-algorithm alternating between regret minimization algorithms instanced at different (high and low) temporal abstractions. At the higher level, we treat the problem as a Semi-Markov Decision Process (SMDP), with fixed low-level policies, while at a lower level, inner option policies are learned with a fixed high-level policy. The bounds derived are compared with the lower bound for non-hierarchical finite-horizon problems, allowing to characterize when a hierarchical approach is provably preferable, even without pre-trained options.
An Option-Dependent Analysis of Regret Minimization Algorithms in Finite-Horizon Semi-Markov Decision Processes
May 10, 2023A large variety of real-world Reinforcement Learning (RL) tasks is characterized by a complex and heterogeneous structure that makes end-to-end (or flat) approaches hardly applicable or even infeasible. Hierarchical Reinforcement Learning (HRL) provides general solutions to address these problems thanks to a convenient multi-level decomposition of the tasks, making their solution accessible. Although often used in practice, few works provide theoretical guarantees to justify this outcome effectively. Thus, it is not yet clear when to prefer such approaches compared to standard flat ones. In this work, we provide an option-dependent upper bound to the regret suffered by regret minimization algorithms in finite-horizon problems. We illustrate that the performance improvement derives from the planning horizon reduction induced by the temporal abstraction enforced by the hierarchical structure. Then, focusing on a sub-setting of HRL approaches, the options framework, we highlight how the average duration of the available options affects the planning horizon and, consequently, the regret itself. Finally, we relax the assumption of having pre-trained options to show how in particular situations, learning hierarchically from scratch could be preferable to using a standard approach.
Inverse Reinforcement Learning from a Gradient-based Learner
Jul 15, 2020

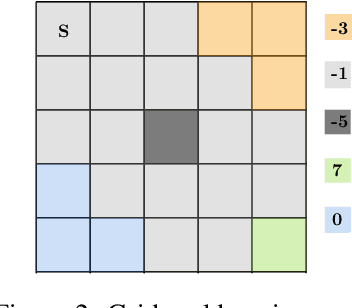
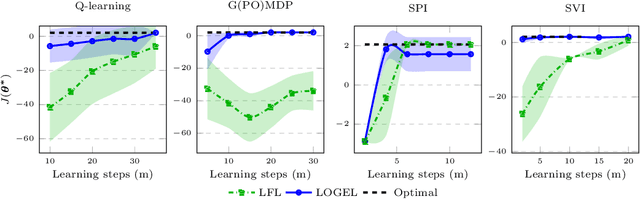
Inverse Reinforcement Learning addresses the problem of inferring an expert's reward function from demonstrations. However, in many applications, we not only have access to the expert's near-optimal behavior, but we also observe part of her learning process. In this paper, we propose a new algorithm for this setting, in which the goal is to recover the reward function being optimized by an agent, given a sequence of policies produced during learning. Our approach is based on the assumption that the observed agent is updating her policy parameters along the gradient direction. Then we extend our method to deal with the more realistic scenario where we only have access to a dataset of learning trajectories. For both settings, we provide theoretical insights into our algorithms' performance. Finally, we evaluate the approach in a simulated GridWorld environment and on the MuJoCo environments, comparing it with the state-of-the-art baseline.