 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Drug Discovery: Inference-level Data Protection Perspective
May 13, 2022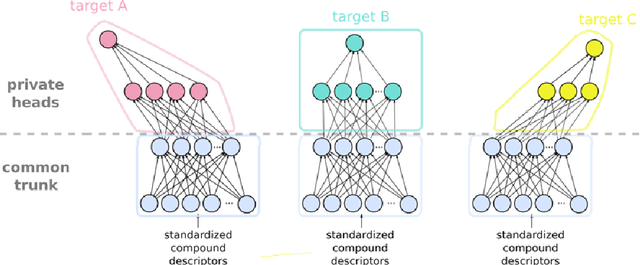
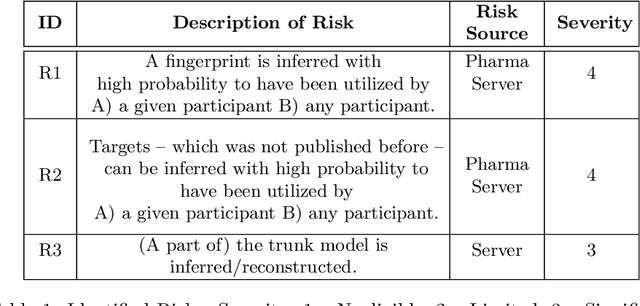
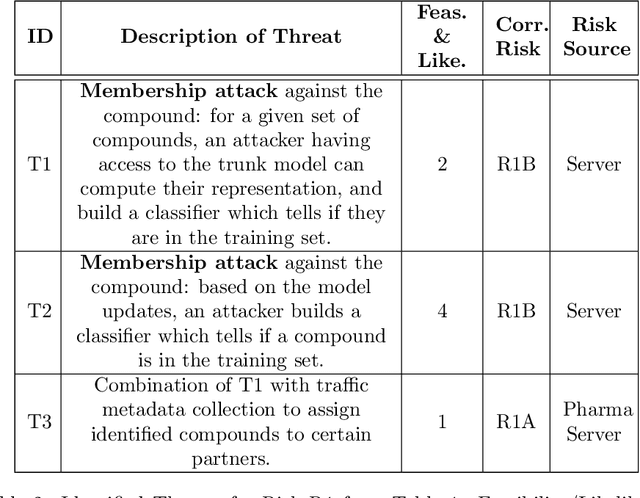
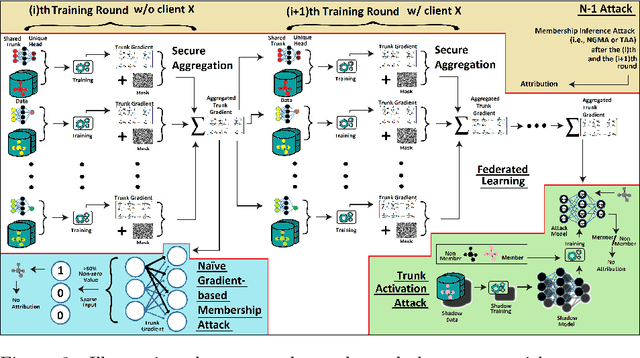
Pharmaceutical industry can better leverage its data assets to virtualize drug discovery through a collaborative machine learning platform. On the other hand, there are non-negligible risks stemming from the unintended leakage of participants' training data, hence, it is essential for such a platform to be secure and privacy-preserving. This paper describes a privacy risk assessment for collaborative modeling in the preclinical phase of drug discovery to accelerate the selection of promising drug candidates. After a short taxonomy of state-of-the-art inference attacks we adopt and customize several to the underlying scenario. Finally we describe and experiments with a handful of relevant privacy protection techniques to mitigate such attacks.
Automatic Driver Identification from In-Vehicle Network Logs
Oct 25, 2019
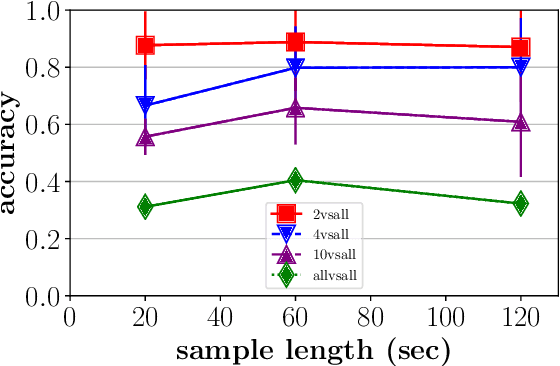
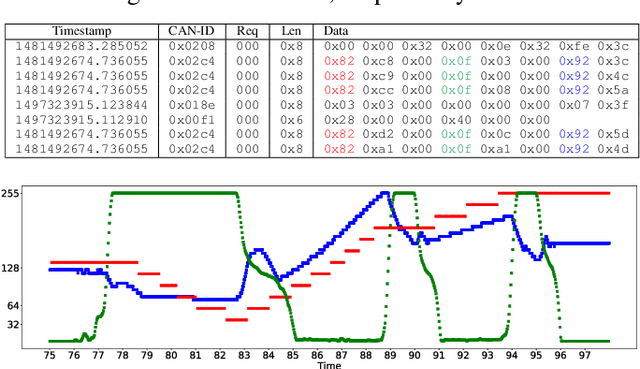
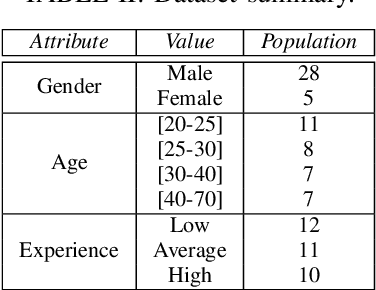
Data generated by cars is growing at an unprecedented scale. As cars gradually become part of the Internet of Things (IoT) ecosystem, several stakeholders discover the value of in-vehicle network logs containing the measurements of the multitude of sensors deployed within the car. This wealth of data is also expected to be exploitable by third parties for the purpose of profiling drivers in order to provide personalized, valueadded services. Although several prior works have successfully demonstrated the feasibility of driver re-identification using the in-vehicle network data captured on the vehicle's CAN (Controller Area Network) bus, they inferred the identity of the driver only from known sensor signals (such as the vehicle's speed, brake pedal position, steering wheel angle, etc.) extracted from the CAN messages. However, car manufacturers intentionally do not reveal exact signal location and semantics within CAN logs. We show that the inference of driver identity is possible even with off-the-shelf machine learning techniques without reverse-engineering the CAN protocol. We demonstrate our approach on a dataset of 33 drivers and show that a driver can be re-identified and distinguished from other drivers with an accuracy of 75-85%.
Differentially Private Mixture of Generative Neural Networks
Jul 13, 2018
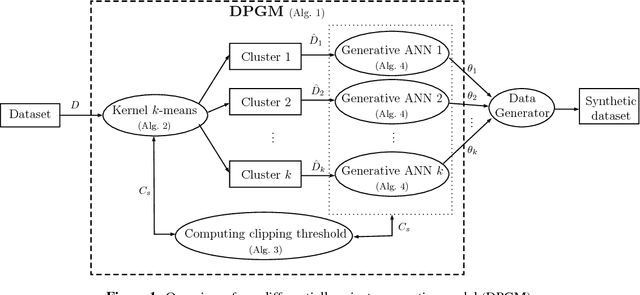
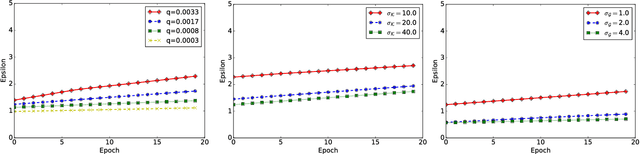
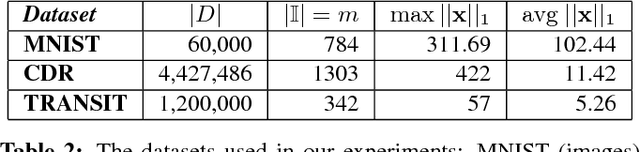
Generative models are used in a wide range of applications building on large amounts of contextually rich information. Due to possible privacy violations of the individuals whose data is used to train these models, however, publishing or sharing generative models is not always viable. In this paper, we present a novel technique for privately releasing generative models and entire high-dimensional datasets produced by these models. We model the generator distribution of the training data with a mixture of $k$ generative neural networks. These are trained together and collectively learn the generator distribution of a dataset. Data is divided into $k$ clusters, using a novel differentially private kernel $k$-means, then each cluster is given to separate generative neural networks, such as Restricted Boltzmann Machines or Variational Autoencoders, which are trained only on their own cluster using differentially private gradient descent. We evaluate our approach using the MNIST dataset, as well as call detail records and transit datasets, showing that it produces realistic synthetic samples, which can also be used to accurately compute arbitrary number of counting queries.