 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond performance-wise Contribution Evaluation in Federated Learning
Feb 25, 2026Federated learning offers a privacy-friendly collaborative learning framework, yet its success, like any joint venture, hinges on the contributions of its participants. Existing client evaluation methods predominantly focus on model performance, such as accuracy or loss, which represents only one dimension of a machine learning model's overall utility. In contrast, this work investigates the critical, yet overlooked, issue of client contributions towards a model's trustworthiness -- specifically, its reliability (tolerance to noisy data), resilience (resistance to adversarial examples), and fairness (measured via demographic parity). To quantify these multifaceted contributions, we employ the state-of-the-art approximation of the Shapley value, a principled method for value attribution. Our results reveal that no single client excels across all dimensions, which are largely independent from each other, highlighting a critical flaw in current evaluation scheme: no single metric is adequate for comprehensive evaluation and equitable rewarding allocation.
Private and Robust Contribution Evaluation in Federated Learning
Feb 25, 2026Cross-silo federated learning allows multiple organizations to collaboratively train machine learning models without sharing raw data, but client updates can still leak sensitive information through inference attacks. Secure aggregation protects privacy by hiding individual updates, yet it complicates contribution evaluation, which is critical for fair rewards and detecting low-quality or malicious participants. Existing marginal-contribution methods, such as the Shapley value, are incompatible with secure aggregation, and practical alternatives, such as Leave-One-Out, are crude and rely on self-evaluation. We introduce two marginal-difference contribution scores compatible with secure aggregation. Fair-Private satisfies standard fairness axioms, while Everybody-Else eliminates self-evaluation and provides resistance to manipulation, addressing a largely overlooked vulnerability. We provide theoretical guarantees for fairness, privacy, robustness, and computational efficiency, and evaluate our methods on multiple medical image datasets and CIFAR10 in cross-silo settings. Our scores consistently outperform existing baselines, better approximate Shapley-induced client rankings, and improve downstream model performance as well as misbehavior detection. These results demonstrate that fairness, privacy, robustness, and practical utility can be achieved jointly in federated contribution evaluation, offering a principled solution for real-world cross-silo deployments.
SQLi Detection with ML: A data-source perspective
Apr 24, 2023



Almost 50 years after the invention of SQL, injection attacks are still top-tier vulnerabilities of today's ICT systems. Consequently, SQLi detection is still an active area of research, where the most recent works incorporate machine learning techniques into the proposed solutions. In this work, we highlight the shortcomings of the previous ML-based results focusing on four aspects: the evaluation methods, the optimization of the model parameters, the distribution of utilized datasets, and the feature selection. Since no single work explored all of these aspects satisfactorily, we fill this gap and provide an in-depth and comprehensive empirical analysis. Moreover, we cross-validate the trained models by using data from other distributions. This aspect of ML models (trained for SQLi detection) was never studied. Yet, the sensitivity of the model's performance to this is crucial for any real-life deployment. Finally, we validate our findings on a real-world industrial SQLi dataset.
Collaborative Drug Discovery: Inference-level Data Protection Perspective
May 13, 2022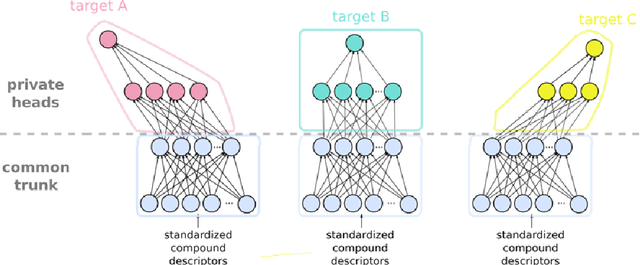
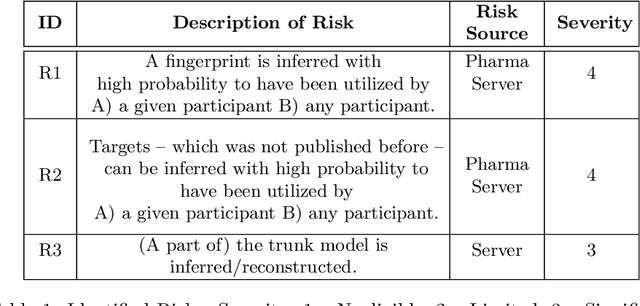
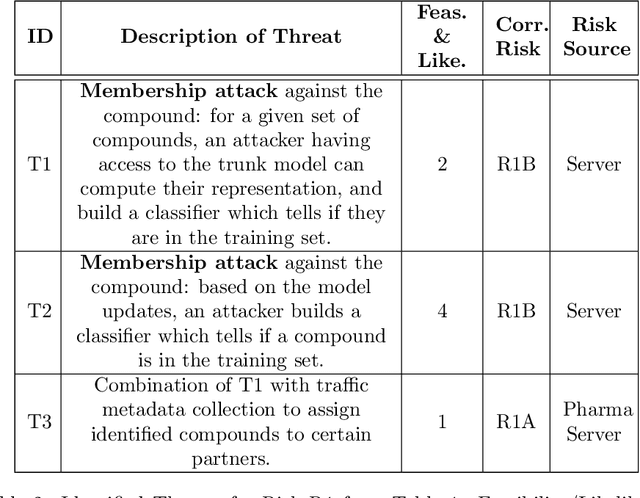
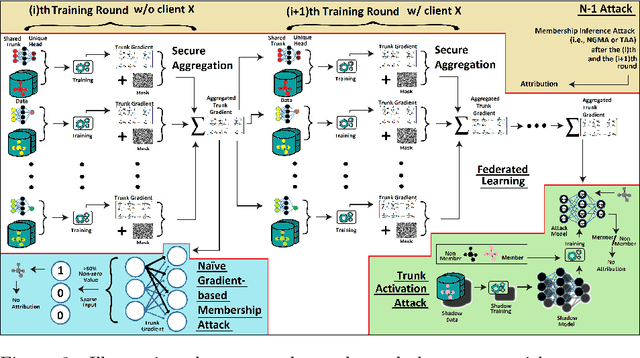
Pharmaceutical industry can better leverage its data assets to virtualize drug discovery through a collaborative machine learning platform. On the other hand, there are non-negligible risks stemming from the unintended leakage of participants' training data, hence, it is essential for such a platform to be secure and privacy-preserving. This paper describes a privacy risk assessment for collaborative modeling in the preclinical phase of drug discovery to accelerate the selection of promising drug candidates. After a short taxonomy of state-of-the-art inference attacks we adopt and customize several to the underlying scenario. Finally we describe and experiments with a handful of relevant privacy protection techniques to mitigate such attacks.
Property Inference Attacks on Convolutional Neural Networks: Influence and Implications of Target Model's Complexity
Apr 27, 2021



Machine learning models' goal is to make correct predictions for specific tasks by learning important properties and patterns from data. By doing so, there is a chance that the model learns properties that are unrelated to its primary task. Property Inference Attacks exploit this and aim to infer from a given model (\ie the target model) properties about the training dataset seemingly unrelated to the model's primary goal. If the training data is sensitive, such an attack could lead to privacy leakage. This paper investigates the influence of the target model's complexity on the accuracy of this type of attack, focusing on convolutional neural network classifiers. We perform attacks on models that are trained on facial images to predict whether someone's mouth is open. Our attacks' goal is to infer whether the training dataset is balanced gender-wise. Our findings reveal that the risk of a privacy breach is present independently of the target model's complexity: for all studied architectures, the attack's accuracy is clearly over the baseline. We discuss the implication of the property inference on personal data in the light of Data Protection Regulations and Guidelines.