 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Distribution Impacts Model Fairness: Single vs. Multi-Task Learning
Jul 24, 2024The influence of bias in datasets on the fairness of model predictions is a topic of ongoing research in various fields. We evaluate the performance of skin lesion classification using ResNet-based CNNs, focusing on patient sex variations in training data and three different learning strategies. We present a linear programming method for generating datasets with varying patient sex and class labels, taking into account the correlations between these variables. We evaluated the model performance using three different learning strategies: a single-task model, a reinforcing multi-task model, and an adversarial learning scheme. Our observations include: 1) sex-specific training data yields better results, 2) single-task models exhibit sex bias, 3) the reinforcement approach does not remove sex bias, 4) the adversarial model eliminates sex bias in cases involving only female patients, and 5) datasets that include male patients enhance model performance for the male subgroup, even when female patients are the majority. To generalise these findings, in future research, we will examine more demographic attributes, like age, and other possibly confounding factors, such as skin colour and artefacts in the skin lesions. We make all data and models available on GitHub.
Defining Quality Requirements for a Trustworthy AI Wildflower Monitoring Platform
Mar 23, 2023
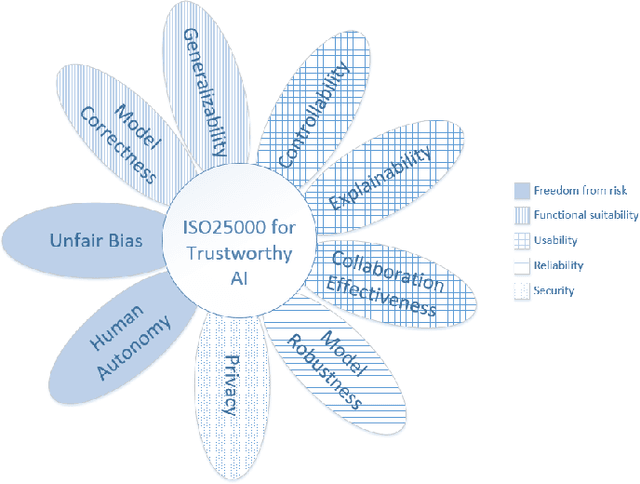


For an AI solution to evolve from a trained machine learning model into a production-ready AI system, many more things need to be considered than just the performance of the machine learning model. A production-ready AI system needs to be trustworthy, i.e. of high quality. But how to determine this in practice? For traditional software, ISO25000 and its predecessors have since long time been used to define and measure quality characteristics. Recently, quality models for AI systems, based on ISO25000, have been introduced. This paper applies one such quality model to a real-life case study: a deep learning platform for monitoring wildflowers. The paper presents three realistic scenarios sketching what it means to respectively use, extend and incrementally improve the deep learning platform for wildflower identification and counting. Next, it is shown how the quality model can be used as a structured dictionary to define quality requirements for data, model and software. Future work remains to extend the quality model with metrics, tools and best practices to aid AI engineering practitioners in implementing trustworthy AI systems.
ENHANCE : A case study for skin lesion classification
Jul 27, 2021
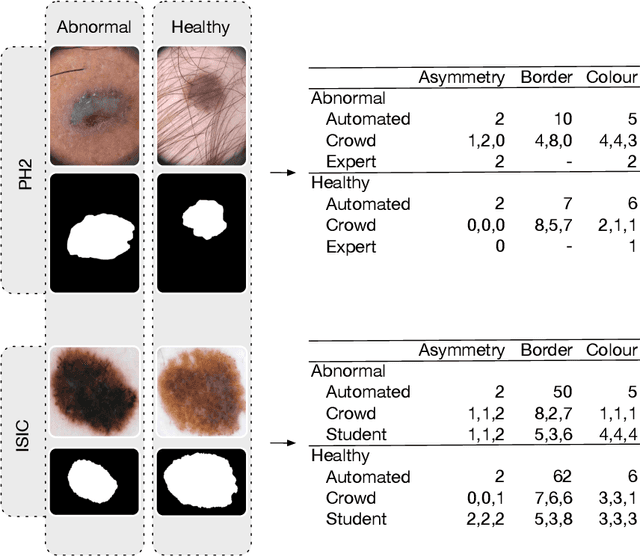
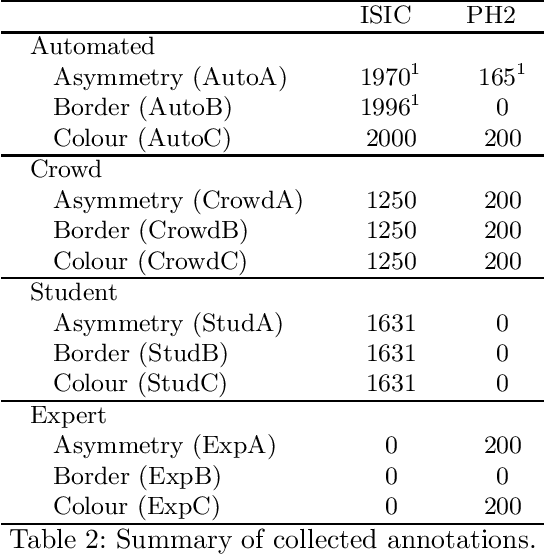
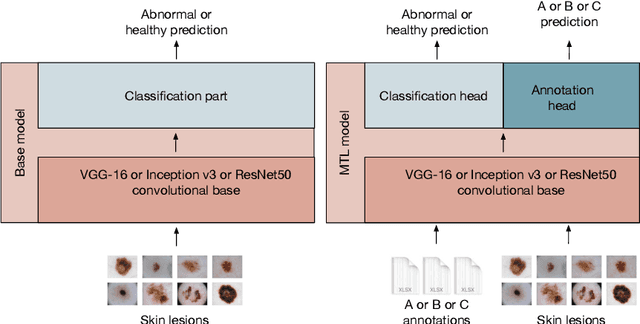
We present ENHANCE, an open dataset with multiple annotations to complement the existing ISIC and PH2 skin lesion classification datasets. This dataset contains annotations of visual ABC (asymmetry, border, colour) features from non-expert annotation sources: undergraduate students, crowd workers from Amazon MTurk and classic image processing algorithms. In this paper we first analyse the correlations between the annotations and the diagnostic label of the lesion, as well as study the agreement between different annotation sources. Overall we find weak correlations of non-expert annotations with the diagnostic label, and low agreement between different annotation sources. We then study multi-task learning (MTL) with the annotations as additional labels, and show that non-expert annotations can improve (ensembles of) state-of-the-art convolutional neural networks via MTL. We hope that our dataset can be used in further research into multiple annotations and/or MTL. All data and models are available on Github: https://github.com/raumannsr/ENHANCE.
Lessons Learned from Educating AI Engineers
Mar 19, 2021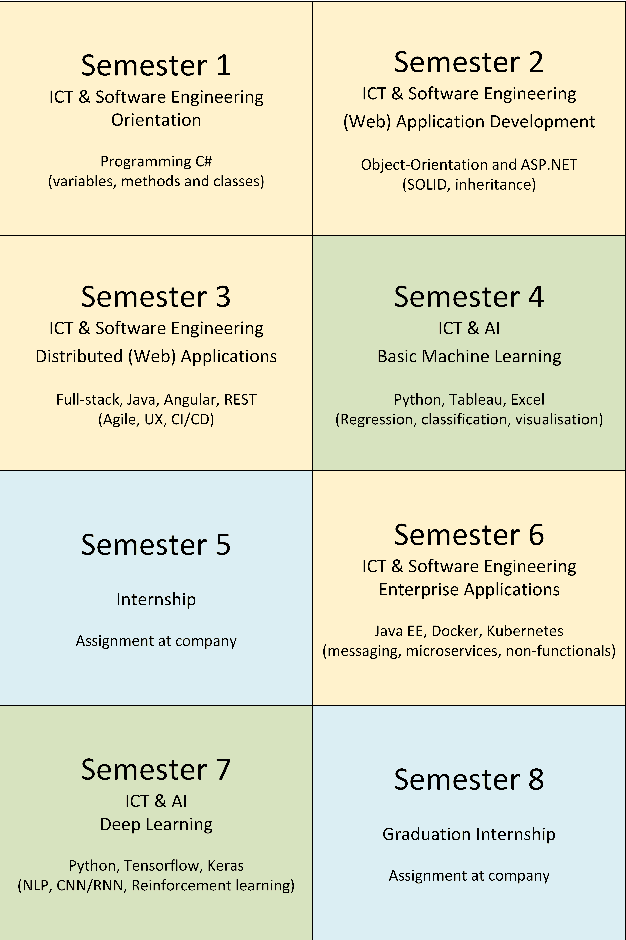


Over the past three years we have built a practice-oriented, bachelor level, educational programme for software engineers to specialize as AI engineers. The experience with this programme and the practical assignments our students execute in industry has given us valuable insights on the profession of AI engineer. In this paper we discuss our programme and the lessons learned for industry and research.
Turning Software Engineers into AI Engineers
Nov 03, 2020



In industry as well as education as well as academics we see a growing need for knowledge on how to apply machine learning in software applications. With the educational programme ICT & AI at Fontys UAS we had to find an answer to the question: "How should we educate software engineers to become AI engineers?" This paper describes our educational programme, the open source tools we use, and the literature it is based on. After three years of experience, we present our lessons learned for both educational institutions and software engineers in practice.
Risk of Training Diagnostic Algorithms on Data with Demographic Bias
Jun 17, 2020
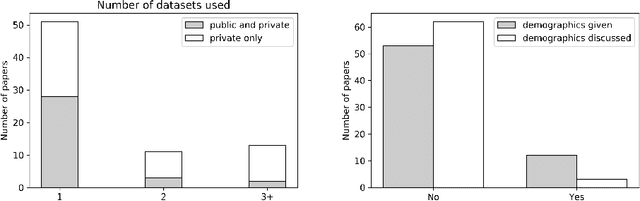

One of the critical challenges in machine learning applications is to have fair predictions. There are numerous recent examples in various domains that convincingly show that algorithms trained with biased datasets can easily lead to erroneous or discriminatory conclusions. This is even more crucial in clinical applications where the predictive algorithms are designed mainly based on a limited or given set of medical images and demographic variables such as age, sex and race are not taken into account. In this work, we conduct a survey of the MICCAI 2018 proceedings to investigate the common practice in medical image analysis applications. Surprisingly, we found that papers focusing on diagnosis rarely describe the demographics of the datasets used, and the diagnosis is purely based on images. In order to highlight the importance of considering the demographics in diagnosis tasks, we used a publicly available dataset of skin lesions. We then demonstrate that a classifier with an overall area under the curve (AUC) of 0.83 has variable performance between 0.76 and 0.91 on subgroups based on age and sex, even though the training set was relatively balanced. Moreover, we show that it is possible to learn unbiased features by explicitly using demographic variables in an adversarial training setup, which leads to balanced scores per subgroups. Finally, we discuss the implications of these results and provide recommendations for further research.
Multi-task Learning with Crowdsourced Features Improves Skin Lesion Diagnosis
Apr 28, 2020
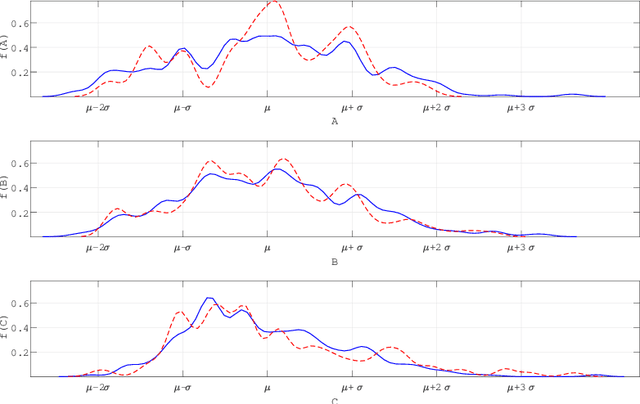


Machine learning has a recognised need for large amounts of annotated data. Due to the high cost of expert annotations, crowdsourcing, where non-experts are asked to label or outline images, has been proposed as an alternative. Although many promising results are reported, the quality of diagnostic crowdsourced labels is still lacking. We propose to address this by instead asking the crowd about visual features of the images, which can be provided more intuitively, and by using these features in a multi-task learning framework. We compare our proposed approach to a baseline model with a set of 2000 skin lesions from the ISIC 2017 challenge dataset. The baseline model only predicts a binary label from the skin lesion image, while our multi-task model also predicts one of the following features: asymmetry of the lesion, border irregularity and color. We show that crowd features in combination with multi-task learning leads to improved generalisation. The area under the receiver operating characteristic curve is 0.754 for the baseline model and 0.782, 0.785 and 0.789 for multi-task models with border, color and asymmetry respectively. Finally, we discuss the findings, identify some limitations and recommend directions for further research.