 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Faceted Proposal for Transparent Attribution of AI-Assisted Text Production
Apr 28, 2026Artificial intelligence systems are increasingly integrated into writing processes, challenging traditional notions of authorship, responsibility, and intellectual contribution. Current disclosure practices usually indicate whether AI was used, but rarely explain how it was used, where it intervened, or how its output was reviewed. This paper proposes a faceted model for representing AI-assisted text production at the levels of documents, chapters, sections, and paragraphs. The proposal introduces a core model based on Form, Generation, and Evaluation, and an extended model that adds Intent, Control, and Traceability. The model is positioned as a minimal operational baseline with extensibility toward higher-fidelity representations. A worked example based on the production of this article demonstrates applicability.
The Economic Implications of Large Language Model Selection on Earnings and Return on Investment: A Decision Theoretic Model
May 27, 2024Selecting language models in business contexts requires a careful analysis of the final financial benefits of the investment. However, the emphasis of academia and industry analysis of LLM is solely on performance. This work introduces a framework to evaluate LLMs, focusing on the earnings and return on investment aspects that should be taken into account in business decision making. We use a decision-theoretic approach to compare the financial impact of different LLMs, considering variables such as the cost per token, the probability of success in the specific task, and the gain and losses associated with LLMs use. The study reveals how the superior accuracy of more expensive models can, under certain conditions, justify a greater investment through more significant earnings but not necessarily a larger RoI. This article provides a framework for companies looking to optimize their technology choices, ensuring that investment in cutting-edge technology aligns with strategic financial objectives. In addition, we discuss how changes in operational variables influence the economics of using LLMs, offering practical insights for enterprise settings, finding that the predicted gain and loss and the different probabilities of success and failure are the variables that most impact the sensitivity of the models.
Word Embeddings: A Survey
Jan 25, 2019


This work lists and describes the main recent strategies for building fixed-length, dense and distributed representations for words, based on the distributional hypothesis. These representations are now commonly called word embeddings and, in addition to encoding surprisingly good syntactic and semantic information, have been proven useful as extra features in many downstream NLP tasks.
RDF2PT: Generating Brazilian Portuguese Texts from RDF Data
Feb 22, 2018
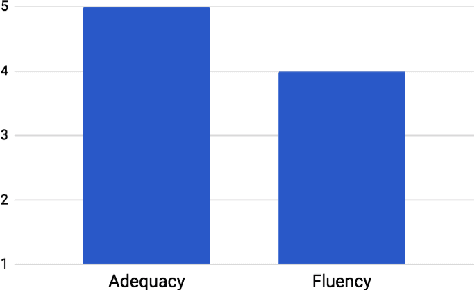

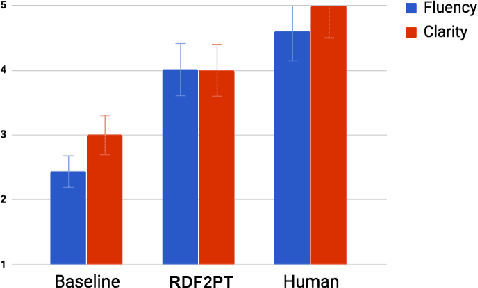
The generation of natural language from Resource Description Framework (RDF) data has recently gained significant attention due to the continuous growth of Linked Data. A number of these approaches generate natural language in languages other than English, however, no work has been proposed to generate Brazilian Portuguese texts out of RDF. We address this research gap by presenting RDF2PT, an approach that verbalizes RDF data to Brazilian Portuguese language. We evaluated RDF2PT in an open questionnaire with 44 native speakers divided into experts and non-experts. Our results suggest that RDF2PT is able to generate text which is similar to that generated by humans and can hence be easily understood.