 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High Quality Text-To-Speech System Composed of Multiple Neural Networks
Dec 05, 1998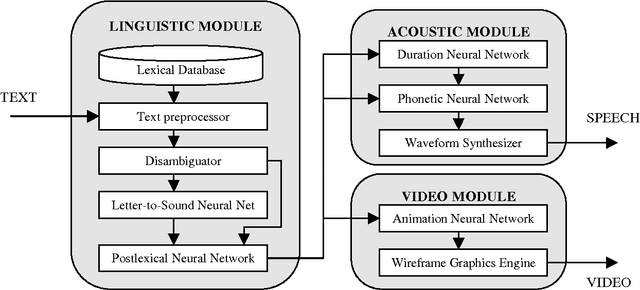
While neural networks have been employed to handle several different text-to-speech tasks, ours is the first system to use neural networks throughout, for both linguistic and acoustic processing. We divide the text-to-speech task into three subtasks, a linguistic module mapping from text to a linguistic representation, an acoustic module mapping from the linguistic representation to speech, and a video module mapping from the linguistic representation to animated images. The linguistic module employs a letter-to-sound neural network and a postlexical neural network. The acoustic module employs a duration neural network and a phonetic neural network. The visual neural network is employed in parallel to the acoustic module to drive a talking head. The use of neural networks that can be retrained on the characteristics of different voices and languages affords our system a degree of adaptability and naturalness heretofore unavailable.
* Source link (9812006.tar.gz) contains: 1 PostScript file (4 pages) and 3 WAV audio files. If your system does not support Windows WAV files, try a tool like "sox" to translate the audio into a format of your choice
Text-To-Speech Conversion with Neural Networks: A Recurrent TDNN Approach
Nov 24, 1998
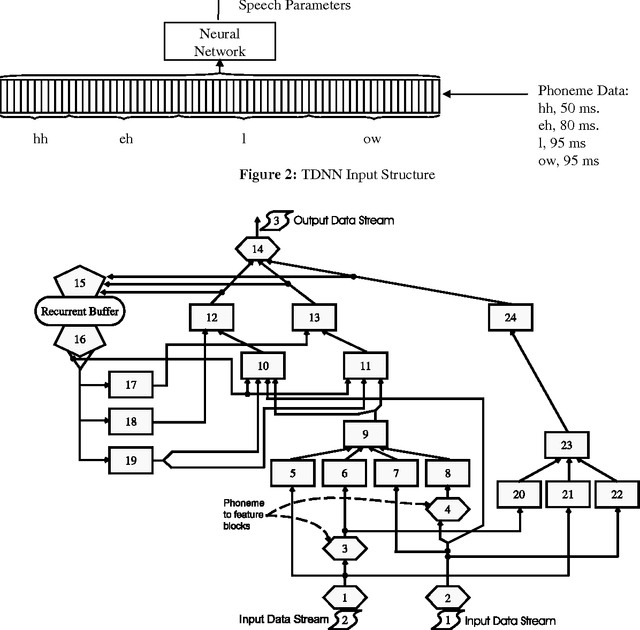
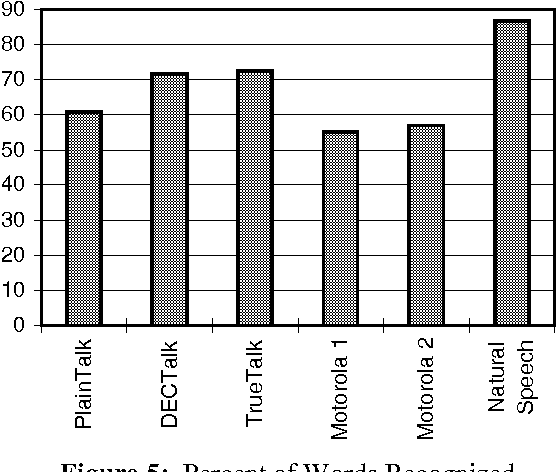
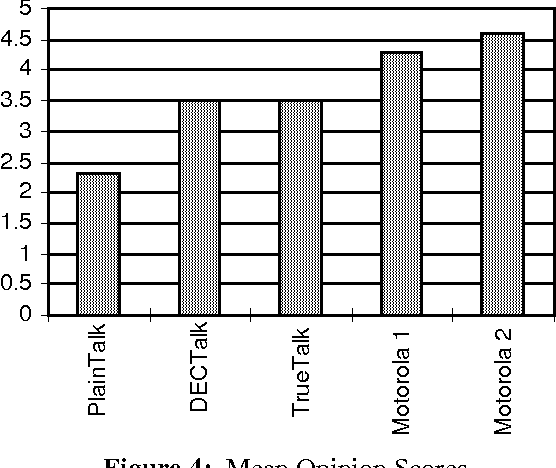
This paper describes the design of a neural network that performs the phonetic-to-acoustic mapping in a speech synthesis system. The use of a time-domain neural network architecture limits discontinuities that occur at phone boundaries. Recurrent data input also helps smooth the output parameter tracks. Independent testing has demonstrated that the voice quality produced by this system compares favorably with speech from existing commercial text-to-speech systems.
* 4 pages, PostScript
Speech Synthesis with Neural Networks
Nov 24, 1998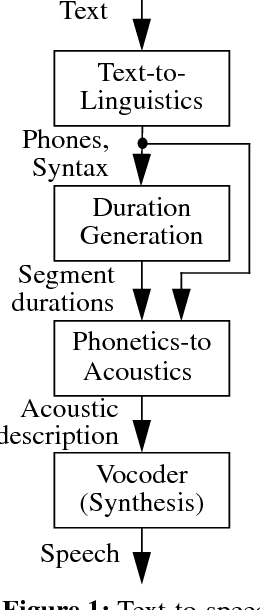
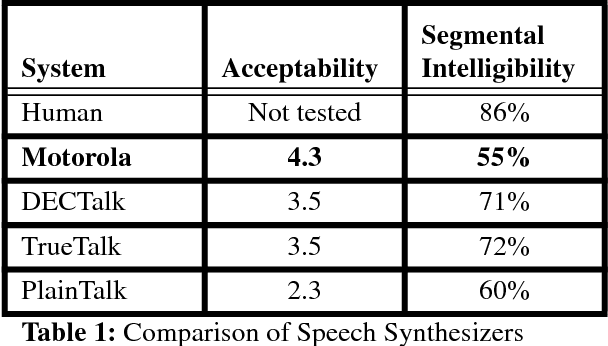


Text-to-speech conversion has traditionally been performed either by concatenating short samples of speech or by using rule-based systems to convert a phonetic representation of speech into an acoustic representation, which is then converted into speech. This paper describes a system that uses a time-delay neural network (TDNN) to perform this phonetic-to-acoustic mapping, with another neural network to control the timing of the generated speech. The neural network system requires less memory than a concatenation system, and performed well in tests comparing it to commercial systems using other technologies.
* 6 pages, PostScript
Generating Segment Durations in a Text-To-Speech System: A Hybrid Rule-Based/Neural Network Approach
Nov 24, 1998


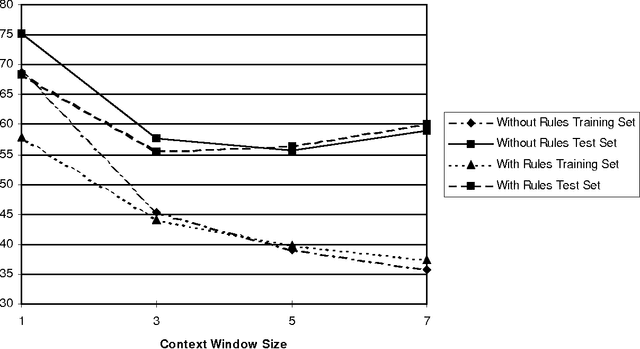
A combination of a neural network with rule firing information from a rule-based system is used to generate segment durations for a text-to-speech system. The system shows a slight improvement in performance over a neural network system without the rule firing information. Synthesized speech using segment durations was accepted by listeners as having about the same quality as speech generated using segment durations extracted from natural speech.
* 4 pages, PostScript