Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Segment Durations in a Text-To-Speech System: A Hybrid Rule-Based/Neural Network Approach
Paper and Code
Nov 24, 1998


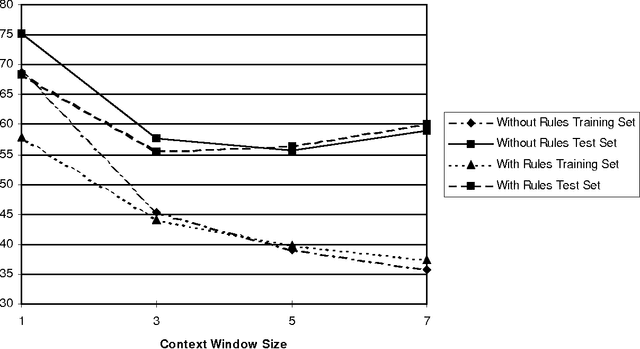
A combination of a neural network with rule firing information from a rule-based system is used to generate segment durations for a text-to-speech system. The system shows a slight improvement in performance over a neural network system without the rule firing information. Synthesized speech using segment durations was accepted by listeners as having about the same quality as speech generated using segment durations extracted from natural speech.
* Proceedings of Eurospeech (1997) 2675-2678. Rhodes, Greece * 4 pages, PostScript
View paper on