 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High Quality Text-To-Speech System Composed of Multiple Neural Networks
Dec 05, 1998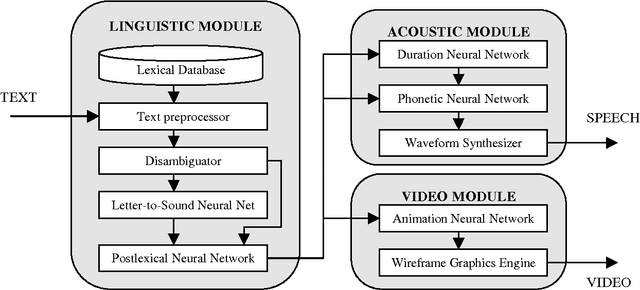
While neural networks have been employed to handle several different text-to-speech tasks, ours is the first system to use neural networks throughout, for both linguistic and acoustic processing. We divide the text-to-speech task into three subtasks, a linguistic module mapping from text to a linguistic representation, an acoustic module mapping from the linguistic representation to speech, and a video module mapping from the linguistic representation to animated images. The linguistic module employs a letter-to-sound neural network and a postlexical neural network. The acoustic module employs a duration neural network and a phonetic neural network. The visual neural network is employed in parallel to the acoustic module to drive a talking head. The use of neural networks that can be retrained on the characteristics of different voices and languages affords our system a degree of adaptability and naturalness heretofore unavailable.
* Source link (9812006.tar.gz) contains: 1 PostScript file (4 pages) and 3 WAV audio files. If your system does not support Windows WAV files, try a tool like "sox" to translate the audio into a format of your choice