Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Synthesis with Neural Networks
Paper and Code
Nov 24, 1998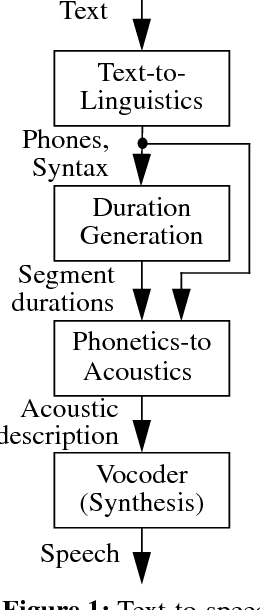
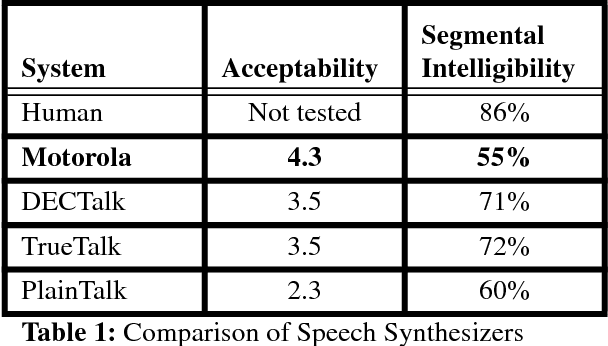


Text-to-speech conversion has traditionally been performed either by concatenating short samples of speech or by using rule-based systems to convert a phonetic representation of speech into an acoustic representation, which is then converted into speech. This paper describes a system that uses a time-delay neural network (TDNN) to perform this phonetic-to-acoustic mapping, with another neural network to control the timing of the generated speech. The neural network system requires less memory than a concatenation system, and performed well in tests comparing it to commercial systems using other technologies.
* World Congress on Neural Networks (1996) 45-50. San Diego * 6 pages, PostScript
View paper on