 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Text Emotion Prediction Using Combined Valence and Arousal Ordinal Classification
Apr 02, 2024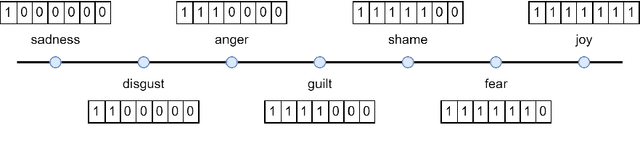
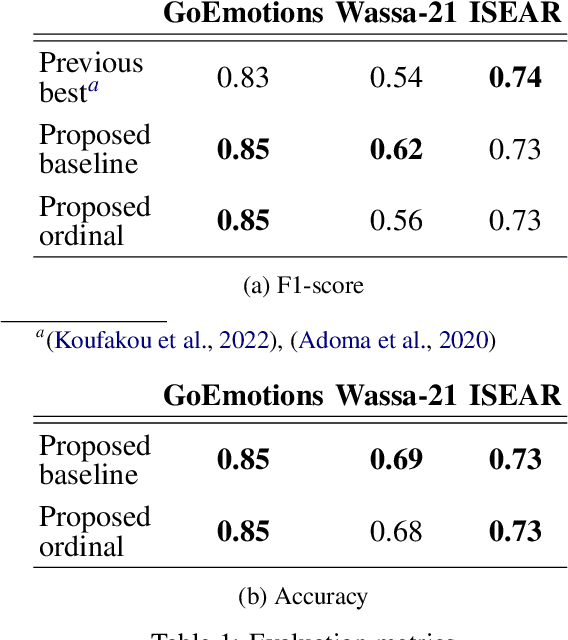
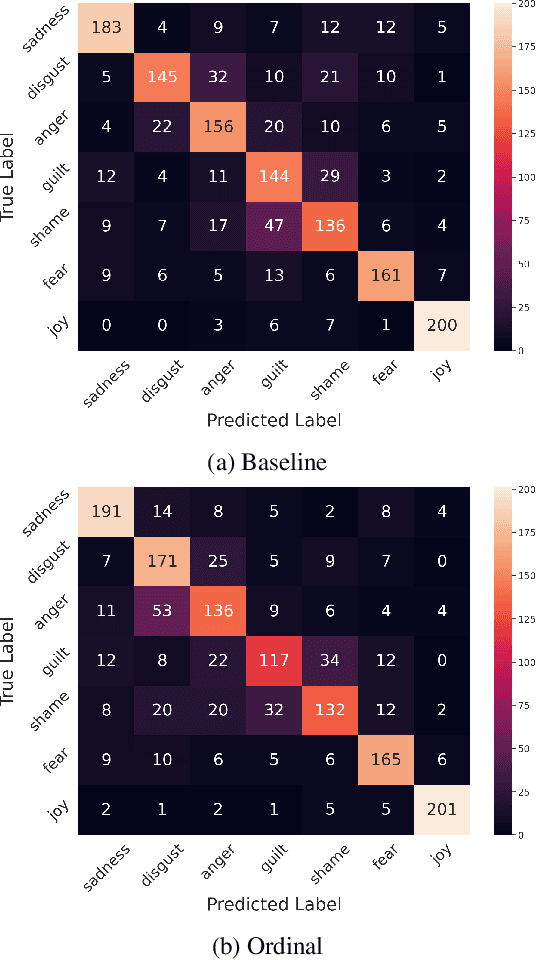
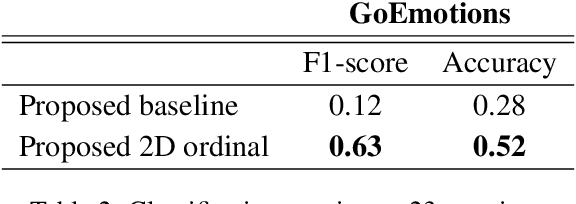
Emotion detection in textual data has received growing interest in recent years, as it is pivotal for developing empathetic human-computer interaction systems. This paper introduces a method for categorizing emotions from text, which acknowledges and differentiates between the diversified similarities and distinctions of various emotions. Initially, we establish a baseline by training a transformer-based model for standard emotion classification, achieving state-of-the-art performance. We argue that not all misclassifications are of the same importance, as there are perceptual similarities among emotional classes. We thus redefine the emotion labeling problem by shifting it from a traditional classification model to an ordinal classification one, where discrete emotions are arranged in a sequential order according to their valence levels. Finally, we propose a method that performs ordinal classification in the two-dimensional emotion space, considering both valence and arousal scales. The results show that our approach not only preserves high accuracy in emotion prediction but also significantly reduces the magnitude of errors in cases of misclassification.
Generating Gender-Ambiguous Text-to-Speech Voices
Nov 01, 2022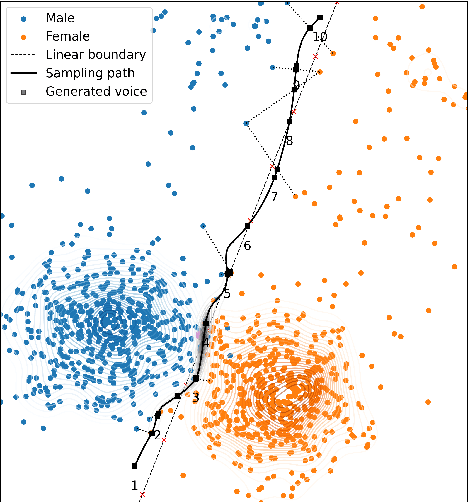

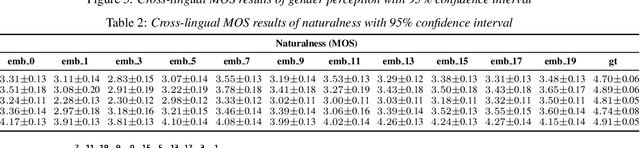
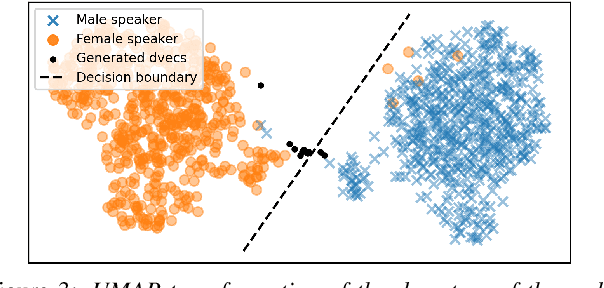
The gender of a voice assistant or any voice user interface is a central element of its perceived identity. While a female voice is a common choice, there is an increasing interest in alternative approaches where the gender is ambiguous rather than clearly identifying as female or male. This work addresses the task of generating gender-ambiguous text-to-speech (TTS) voices that do not correspond to any existing person. This is accomplished by sampling from a latent speaker embeddings' space that was formed while training a multilingual, multi-speaker TTS system on data from multiple male and female speakers. Various options are investigated regarding the sampling process. In our experiments, the effects of different sampling choices on the gender ambiguity and the naturalness of the resulting voices are evaluated. The proposed method is shown able to efficiently generate novel speakers that are superior to a baseline averaged speaker embedding. To our knowledge, this is the first systematic approach that can reliably generate a range of gender-ambiguous voices to meet diverse user requirements.