 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Cepstrum: Pitch Modification for Mel-Based Neural Vocoders
Dec 18, 2025



This paper introduces a cepstrum-based pitch modification method that can be applied to any mel-spectrogram representation. As a result, this method is compatible with any mel-based vocoder without requiring any additional training or changes to the model. This is achieved by directly modifying the cepstrum feature space in order to shift the harmonic structure to the desired target. The spectrogram magnitude is computed via the pseudo-inverse mel transform, then converted to the cepstrum by applying DCT. In this domain, the cepstral peak is shifted without having to estimate its position and the modified mel is recomputed by applying IDCT and mel-filterbank. These pitch-shifted mel-spectrogram features can be converted to speech with any compatible vocoder. The proposed method is validated experimentally with objective and subjective metrics on various state-of-the-art neural vocoders as well as in comparison with traditional pitch modification methods.
MambaRate: Speech Quality Assessment Across Different Sampling Rates
Jul 16, 2025



We propose MambaRate, which predicts Mean Opinion Scores (MOS) with limited bias regarding the sampling rate of the waveform under evaluation. It is designed for Track 3 of the AudioMOS Challenge 2025, which focuses on predicting MOS for speech in high sampling frequencies. Our model leverages self-supervised embeddings and selective state space modeling. The target ratings are encoded in a continuous representation via Gaussian radial basis functions (RBF). The results of the challenge were based on the system-level Spearman's Rank Correllation Coefficient (SRCC) metric. An initial MambaRate version (T16 system) outperformed the pre-trained baseline (B03) by ~14% in a few-shot setting without pre-training. T16 ranked fourth out of five in the challenge, differing by ~6% from the winning system. We present additional results on the BVCC dataset as well as ablations with different representations as input, which outperform the initial T16 version.
Investigating Disentanglement in a Phoneme-level Speech Codec for Prosody Modeling
Sep 13, 2024



Most of the prevalent approaches in speech prosody modeling rely on learning global style representations in a continuous latent space which encode and transfer the attributes of reference speech. However, recent work on neural codecs which are based on Residual Vector Quantization (RVQ) already shows great potential offering distinct advantages. We investigate the prosody modeling capabilities of the discrete space of such an RVQ-VAE model, modifying it to operate on the phoneme-level. We condition both the encoder and decoder of the model on linguistic representations and apply a global speaker embedding in order to factor out both phonetic and speaker information. We conduct an extensive set of investigations based on subjective experiments and objective measures to show that the phoneme-level discrete latent representations obtained this way achieves a high degree of disentanglement, capturing fine-grained prosodic information that is robust and transferable. The latent space turns out to have interpretable structure with its principal components corresponding to pitch and energy.
Improved Text Emotion Prediction Using Combined Valence and Arousal Ordinal Classification
Apr 02, 2024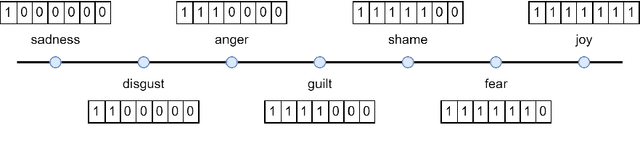
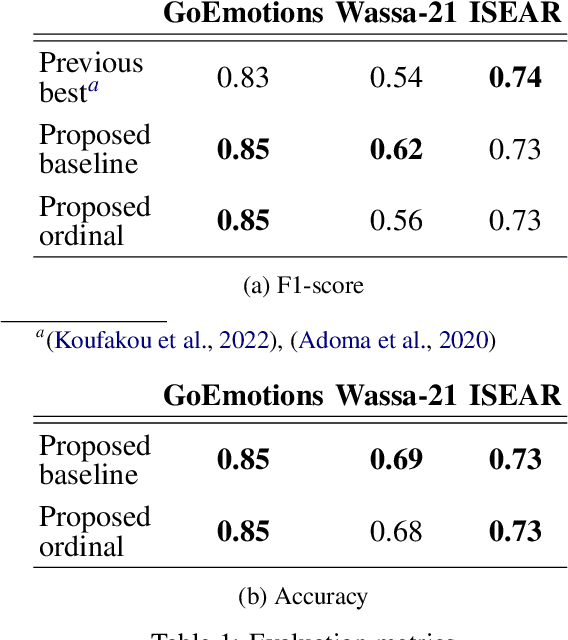
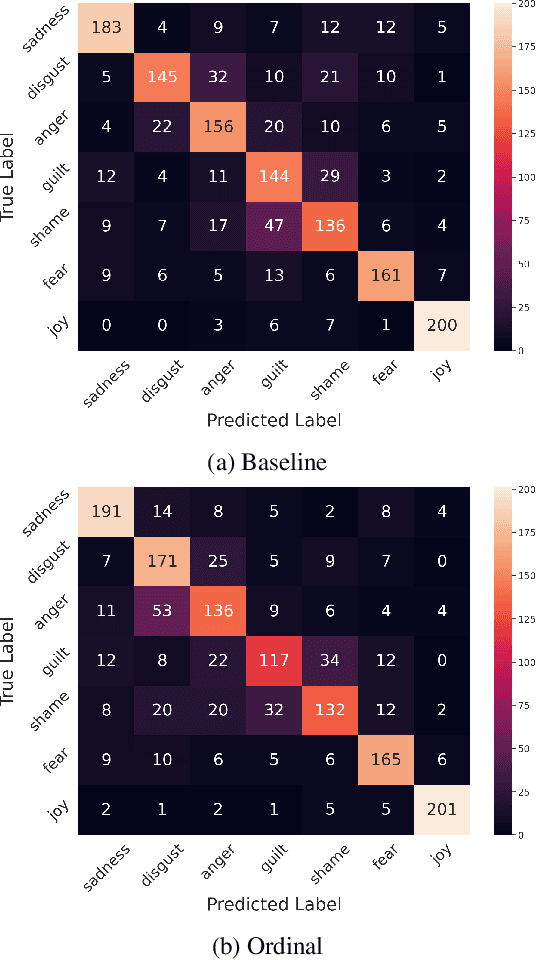
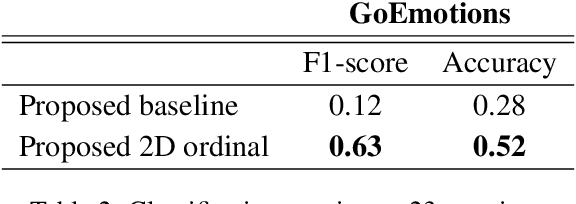
Emotion detection in textual data has received growing interest in recent years, as it is pivotal for developing empathetic human-computer interaction systems. This paper introduces a method for categorizing emotions from text, which acknowledges and differentiates between the diversified similarities and distinctions of various emotions. Initially, we establish a baseline by training a transformer-based model for standard emotion classification, achieving state-of-the-art performance. We argue that not all misclassifications are of the same importance, as there are perceptual similarities among emotional classes. We thus redefine the emotion labeling problem by shifting it from a traditional classification model to an ordinal classification one, where discrete emotions are arranged in a sequential order according to their valence levels. Finally, we propose a method that performs ordinal classification in the two-dimensional emotion space, considering both valence and arousal scales. The results show that our approach not only preserves high accuracy in emotion prediction but also significantly reduces the magnitude of errors in cases of misclassification.
Low-Resource Cross-Domain Singing Voice Synthesis via Reduced Self-Supervised Speech Representations
Feb 02, 2024
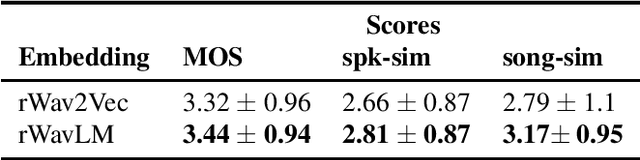
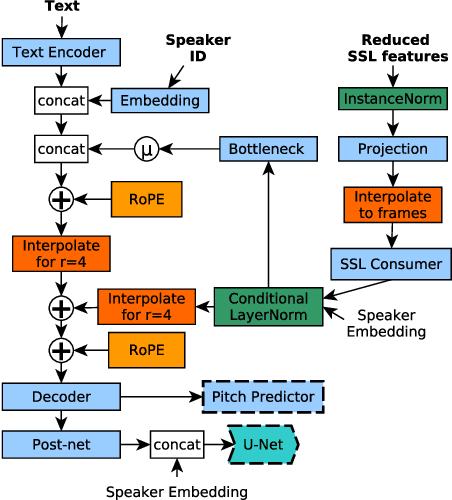
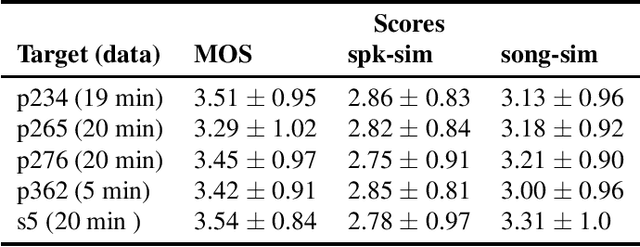
In this paper, we propose a singing voice synthesis model, Karaoker-SSL, that is trained only on text and speech data as a typical multi-speaker acoustic model. It is a low-resource pipeline that does not utilize any singing data end-to-end, since its vocoder is also trained on speech data. Karaoker-SSL is conditioned by self-supervised speech representations in an unsupervised manner. We preprocess these representations by selecting only a subset of their task-correlated dimensions. The conditioning module is indirectly guided to capture style information during training by multi-tasking. This is achieved with a Conformer-based module, which predicts the pitch from the acoustic model's output. Thus, Karaoker-SSL allows singing voice synthesis without reliance on hand-crafted and domain-specific features. There are also no requirements for text alignments or lyrics timestamps. To refine the voice quality, we employ a U-Net discriminator that is conditioned on the target speaker and follows a Diffusion GAN training scheme.