 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Crucial Role of Problem Formulation in Real-World Reinforcement Learning
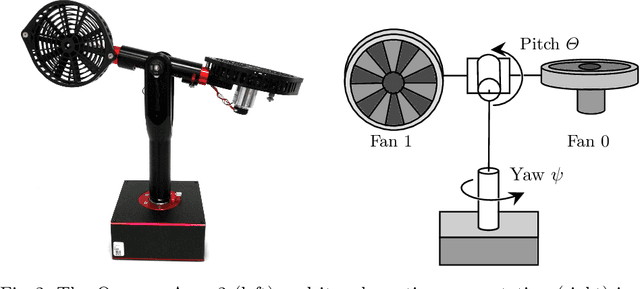
Mar 26, 2025Reinforcement Learning (RL) offers promising solutions for control tasks in industrial cyber-physical systems (ICPSs), yet its real-world adoption remains limited. This paper demonstrates how seemingly small but well-designed modifications to the RL problem formulation can substantially improve performance, stability, and sample efficiency. We identify and investigate key elements of RL problem formulation and show that these enhance both learning speed and final policy quality. Our experiments use a one-degree-of-freedom (1-DoF) helicopter testbed, the Quanser Aero~2, which features non-linear dynamics representative of many industrial settings. In simulation, the proposed problem design principles yield more reliable and efficient training, and we further validate these results by training the agent directly on physical hardware. The encouraging real-world outcomes highlight the potential of RL for ICPS, especially when careful attention is paid to the design principles of problem formulation. Overall, our study underscores the crucial role of thoughtful problem formulation in bridging the gap between RL research and the demands of real-world industrial systems.
A Generative Model Based Honeypot for Industrial OPC UA Communication
Oct 28, 2024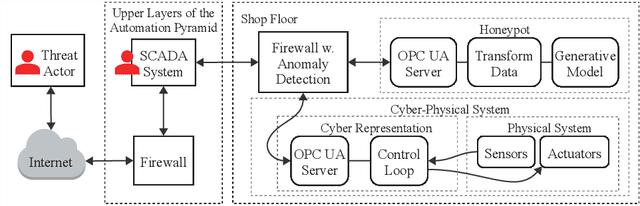

Industrial Operational Technology (OT) systems are increasingly targeted by cyber-attacks due to their integration with Information Technology (IT) systems in the Industry 4.0 era. Besides intrusion detection systems, honeypots can effectively detect these attacks. However, creating realistic honeypots for brownfield systems is particularly challenging. This paper introduces a generative model-based honeypot designed to mimic industrial OPC UA communication. Utilizing a Long ShortTerm Memory (LSTM) network, the honeypot learns the characteristics of a highly dynamic mechatronic system from recorded state space trajectories. Our contributions are twofold: first, we present a proof-of concept for a honeypot based on generative machine-learning models, and second, we publish a dataset for a cyclic industrial process. The results demonstrate that a generative model-based honeypot can feasibly replicate a cyclic industrial process via OPC UA communication. In the short-term, the generative model indicates a stable and plausible trajectory generation, while deviations occur over extended periods. The proposed honeypot implementation operates efficiently on constrained hardware, requiring low computational resources. Future work will focus on improving model accuracy, interaction capabilities, and extending the dataset for broader applications.
Comparison of Model Predictive Control and Proximal Policy Optimization for a 1-DOF Helicopter System
Aug 28, 2024This study conducts a comparative analysis of Model Predictive Control (MPC) and Proximal Policy Optimization (PPO), a Deep Reinforcement Learning (DRL) algorithm, applied to a 1-Degree of Freedom (DOF) Quanser Aero 2 system. Classical control techniques such as MPC and Linear Quadratic Regulator (LQR) are widely used due to their theoretical foundation and practical effectiveness. However, with advancements in computational techniques and machine learning, DRL approaches like PPO have gained traction in solving optimal control problems through environment interaction. This paper systematically evaluates the dynamic response characteristics of PPO and MPC, comparing their performance, computational resource consumption, and implementation complexity. Experimental results show that while LQR achieves the best steady-state accuracy, PPO excels in rise-time and adaptability, making it a promising approach for applications requiring rapid response and adaptability. Additionally, we have established a baseline for future RL-related research on this specific testbed. We also discuss the strengths and limitations of each control strategy, providing recommendations for selecting appropriate controllers for real-world scenarios.
Python-Based Reinforcement Learning on Simulink Models
May 14, 2024This paper proposes a framework for training Reinforcement Learning agents using Python in conjunction with Simulink models. Leveraging Python's superior customization options and popular libraries like Stable Baselines3, we aim to bridge the gap between the established Simulink environment and the flexibility of Python for training bleeding edge agents. Our approach is demonstrated on the Quanser Aero 2, a versatile dual-rotor helicopter. We show that policies trained on Simulink models can be seamlessly transferred to the real system, enabling efficient development and deployment of Reinforcement Learning agents for control tasks. Through systematic integration steps, including C-code generation from Simulink, DLL compilation, and Python interface development, we establish a robust framework for training agents on Simulink models. Experimental results demonstrate the effectiveness of our approach, surpassing previous efforts and highlighting the potential of combining Simulink with Python for Reinforcement Learning research and applications.
A Modular Test Bed for Reinforcement Learning Incorporation into Industrial Applications
Jun 02, 2023
This application paper explores the potential of using reinforcement learning (RL) to address the demands of Industry 4.0, including shorter time-to-market, mass customization, and batch size one production. Specifically, we present a use case in which the task is to transport and assemble goods through a model factory following predefined rules. Each simulation run involves placing a specific number of goods of random color at the entry point. The objective is to transport the goods to the assembly station, where two rivets are installed in each product, connecting the upper part to the lower part. Following the installation of rivets, blue products must be transported to the exit, while green products are to be transported to storage. The study focuses on the application of reinforcement learning techniques to address this problem and improve the efficiency of the production process.
An Architecture for Deploying Reinforcement Learning in Industrial Environments
Jun 02, 2023Industry 4.0 is driven by demands like shorter time-to-market, mass customization of products, and batch size one production. Reinforcement Learning (RL), a machine learning paradigm shown to possess a great potential in improving and surpassing human level performance in numerous complex tasks, allows coping with the mentioned demands. In this paper, we present an OPC UA based Operational Technology (OT)-aware RL architecture, which extends the standard RL setting, combining it with the setting of digital twins. Moreover, we define an OPC UA information model allowing for a generalized plug-and-play like approach for exchanging the RL agent used. In conclusion, we demonstrate and evaluate the architecture, by creating a proof of concept. By means of solving a toy example, we show that this architecture can be used to determine the optimal policy using a real control system.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in Computer Aided Systems Theory - EUROCAST 2022 and is available online at https://doi.org/10.1007/978-3-031-25312-6_67